







之前刚写spark的时候,囫囵吞枣似的了解过一点点Transformations,详情参见RDD操作
今天利用空闲时间好好的再徐一叙这些RDD的转换操作,加深理解。
repartitionAndSortWithinPartitions
解释
字面意思是在重新分配分区的时候,分区内的数据也进行排序操作。参数为分区器(下一节我会讲讲分区器系统)。官方文档说该方法比repartition要高效,因为他在进入shuffle机器前,已经进行过排序了。
返回
ShuffledRDD
源码
OrderedRDDFunctions.scala
def repartitionAndSortWithinPartitions(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
new ShuffledRDD[K, V, V](self, partitioner).setKeyOrdering(ordering)
}代码逻辑相对比较简单,就是创建了一个ShuffledRDD,而且设置了键排序器。
coalesce和repartition
解释
为何把这两个一起说,因为源码显示repartition其实就是调用的coalesce,只是传递的参数为true。
那就简单了,我们只要理解了coalesce方法就行了。该方法的作用是重新设置分区个数,第二个参数是设置在重新分区的时候是否进行shuffle操作。
返回
CoalescedRDD
源码
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}pipe
解释
简单来说就是执行命令,得到命令的输出,转化为RDD[String],很多利用这个特性来跨语言执行php,python等脚本语言,来达到与scala的相互调用。
返回
PipedRDD
源码
/**
* Return an RDD created by piping elements to a forked external process.
*/
def pipe(command: String): RDD[String] = withScope {
// Similar to Runtime.exec(), if we are given a single string, split it into words
// using a standard StringTokenizer (i.e. by spaces)
pipe(PipedRDD.tokenize(command))
}
/**
* Return an RDD created by piping elements to a forked external process.
*/
def pipe(command: String, env: Map[String, String]): RDD[String] = withScope {
// Similar to Runtime.exec(), if we are given a single string, split it into words
// using a standard StringTokenizer (i.e. by spaces)
pipe(PipedRDD.tokenize(command), env)
}
def pipe(
command: Seq[String],
env: Map[String, String] = Map(),
printPipeContext: (String => Unit) => Unit = null,
printRDDElement: (T, String => Unit) => Unit = null,
separateWorkingDir: Boolean = false,
bufferSize: Int = 8192,
encoding: String = Codec.defaultCharsetCodec.name): RDD[String] = withScope {
new PipedRDD(this, command, env,
if (printPipeContext ne null) sc.clean(printPipeContext) else null,
if (printRDDElement ne null) sc.clean(printRDDElement) else null,
separateWorkingDir,
bufferSize,
encoding)
}cartesian
解释
与另一个RDD中的数据进行笛卡尔积计算。但一般这种场景很少见,我就一笔带过了。
返回
CartesianRDD
源码
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
new CartesianRDD(sc, this, other)
}cogroup
解释
针对的也是Pair类型的RDD,对相同K的不同value,进行组合,生成多元tuple,有多少个不同的value,就是几元元组。
类似于(A,1),(A,2),(A,3),经过cogroup操作后,得到(A,(1,2,3))
源码
cogroup的方法有很9个,我只列举了一个方法如下:

def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other1, other2), partitioner)
cg.mapValues { case Array(vs, w1s, w2s) =>
(vs.asInstanceOf[Iterable[V]],
w1s.asInstanceOf[Iterable[W1]],
w2s.asInstanceOf[Iterable[W2]])
}
}join
解释
类似于mysql中的内联语句。
返回
CoGroupedRDD
源码
既然我们说和mysql的内联关系一样,那join自然分内联,左外内联,右外内联。所以源码中关于join的方法如下图所示:
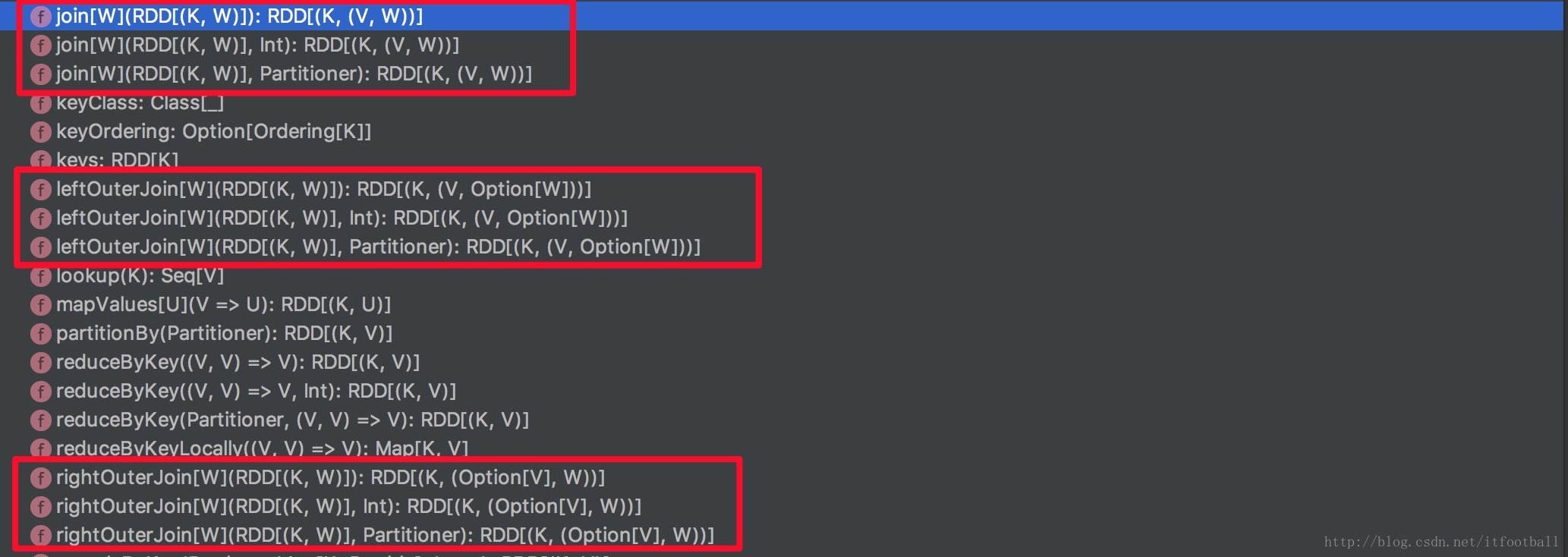
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}从源码得知,调用的其实是cogroup方法。
sortByKey
解释
针对(K,V)格式的RDD,以K进行排序,参数设置倒序还是正序。
返回
ShuffledRDD
源码
OrderedRDDFunctions中
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}aggregateByKey
解释
按key进行聚合操作。
返回
ShuffledRDD
源码

def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
// Serialize the zero value to a byte array so that we can get a new clone of it on each key
val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue)
val zeroArray = new Array[Byte](zeroBuffer.limit)
zeroBuffer.get(zeroArray)
lazy val cachedSerializer = SparkEnv.get.serializer.newInstance()
val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray))
// We will clean the combiner closure later in `combineByKey`
val cleanedSeqOp = self.context.clean(seqOp)
combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),
cleanedSeqOp, combOp, partitioner)
}reduceByKey
解释
以key进行聚合,value值进行合并操作,具体合并函数以第一个参数提供。
返回
ShuffledRDD
源码

def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}groupByKey
解释
(K,V)类型RDD的操作,以Key对数据进行分组,重新分区。
返回
ShuffledRDD
源码

def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}distinct
解释
去重操作
返回
跟父RDD一致
源码
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}intersection
解释
返回两个RDD的交集,并进行去重操作
返回
父RDD一致
源码
def intersection(other: RDD[T]): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)))
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did.
*
* @note This method performs a shuffle internally.
*
* @param partitioner Partitioner to use for the resulting RDD
*/
def intersection(
other: RDD[T],
partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)), partitioner)
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did. Performs a hash partition across the cluster
*
* @note This method performs a shuffle internally.
*
* @param numPartitions How many partitions to use in the resulting RDD
*/
def intersection(other: RDD[T], numPartitions: Int): RDD[T] = withScope {
intersection(other, new HashPartitioner(numPartitions))
}union
解释
合并不去重
返回
UnionRDD/PartitionerAwareUnionRDD
源码
def union[T: ClassTag](rdds: Seq[RDD[T]]): RDD[T] = withScope {
val partitioners = rdds.flatMap(_.partitioner).toSet
if (rdds.forall(_.partitioner.isDefined) && partitioners.size == 1) {
new PartitionerAwareUnionRDD(this, rdds)
} else {
new UnionRDD(this, rdds)
}
}sample
解释
抽样
返回
父RDD
源码
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = {
require(fraction >= 0,
s"Fraction must be nonnegative, but got ${fraction}")
withScope {
require(fraction >= 0.0, "Negative fraction value: " + fraction)
if (withReplacement) {
new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)
} else {
new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)
}
}
}map
解释
最简单的Transformations方法,在每一个父RDD作用传入的函数,一一对应得到另一个RDD,父类RDD和子类RDD的数量一样。
返回
MapPartitionsRDD
源码
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}mapPartitions
解释
在分区内进行map操作。
返回
MapPartitionsRDD
源码
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}mapPartitionsWithIndex
比mapPartitions多了一个分区索引值可供使用。
返回
MapPartitionsRDD
源码
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}flatMap
解释
先以传入的函数,将元素转变为多个元素,然后进行平铺。
返回
MapPartitionsRDD
源码
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}filter
解释
过滤操作,以filter的条件来过滤父RDD,满足条件的流入子类RDD。
返回
MapPartitionsRDD
源码
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}核心函数combineByKeyWithClassTag
在解释groupByKey,aggregateByKey,reduceByKey等操作(K,V)形式的RDD时,源码中都是用了combineByKeyWithClassTag方法,所以很有必要弄懂该方法。
参考文章:combineByKey
combineByKey
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
核心就是三个函数
- createCombiner:初始化第一个值。
- mergeValue:用第一个值处理剩余其他的值,迭代处理。
- mergeCombiners:如果数据处于不同分区,用该函数进行合并。
该函数式将RDD[(K,V)]转换为RDD[(K,C)]的格式,V为父RDD的value值,K为父RDD的KEY,我们要做的操作是根据K,将V转换为C,C可以理解为任何类型,也包括K类型。
都是根据Key分类后进行的操作,不同key之间是不认识的,以下讲解都是以Key分类后,各个小组的处理方式
第一个函数createCombiner,抽象定义了C的格式,他的定义为V=>C,输入为V,返回为C,这是一个初始化函数,将RDD中分区第一个数据的V值作用到这个函数,变成C。第二个函数mergeValue,抽象形式为(C,V)=>C,其实就是利用初始化后得到的C,与RDD其他数据进行合并操作,最终得到一个C。第三个函数mergeCombiners,只有数据分散在不同分区时,才会调用该函数,来合并所有分区的数据。他的抽象形式是(C,C)=>C,意思就是两个combiner合并为一个combiner。
一个高度的抽象函数,解决了很多上层的不同的逻辑,传入不同的函数,方法的效果和功能就不同。














 6622
6622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









