







 本文详细介绍了LZ77压缩算法的主要思路,包括使用三元组替换重复短语,以及在gzip中应用的优化技巧。通过对gzip源码的分析,特别是deflate.c文件中的关键函数,如lm_init、fill_window和longest_match,揭示了算法的内部运作机制,包括哈希表的特殊实现、lazy match技术和匹配串搜索策略。
本文详细介绍了LZ77压缩算法的主要思路,包括使用三元组替换重复短语,以及在gzip中应用的优化技巧。通过对gzip源码的分析,特别是deflate.c文件中的关键函数,如lm_init、fill_window和longest_match,揭示了算法的内部运作机制,包括哈希表的特殊实现、lazy match技术和匹配串搜索策略。
LZ77 压缩算法
参考资料1(学术味较浓)
参考资料2(较为全面)
gzip源码下载地址
这里的图都是自己做的,所以很抱歉,可能在文章页面看起来不怎么清楚,想仔细看细节的话,可以
在新页面打开图片,会清晰很多的。
I. 主要思路
LZ77算法压缩的是输入中重复出现的那些短语,每读到一个新字符,就向前扫描,看是否有重复出现的短语。若搜索出来有重复出现的短语,就用形如
(charactor(匹配串的起始字符), distance, length)的三元组来代替该匹配串,如图
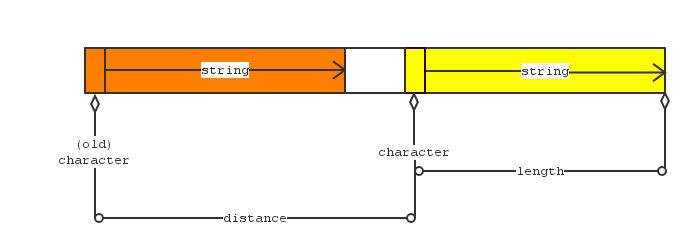
为了保证压缩速度,LZ77 限制了向前搜索的范围,所有查重匹配工作都在一个“滑窗”内进行。
gzip在LZ77算法的基础上增加了不少的优化技巧。该过程主要在c文件deflate.c中(这整个算法就叫做deflate算法,deflate意为“放气”, 有种把车胎放气弄瘪的意思在里面,不知道这个理解对不对(⊙v⊙))。
II. deflate.c源码分析
源码的分析我打算分段来写,并且为了逻辑清晰起见,顺序与源码不同。
(i.)先贴上代码首部的注释:(好歹我也是全英班的,就当练练英语吧。)
/*
* PURPOSE 目的
*
* Identify new text as repetitions of old text within a fixed-
* length sliding window trailing behind the new text.
* 这里的主要活动是在一个定长滑动窗口内进行字符串匹配并初次压缩输出的工作。
*
* DISCUSSION
*
* The "deflation" process depends on being able to identify portions
* of the input text which are identical to earlier input (within a
* sliding window trailing behind the input currently being processed).
* “deflation”算法依靠前后文中相同的字符串达到压缩的目的。
*
* The most straightforward technique turns out to be the fastest for
* most input files: try all possible matches and select the longest.
* 查找所有匹配的串并且选出匹配长度最长的哪一个串进行压缩---
* 这种最直接粗暴的压缩技术,被证明在绝大多数输入情形下都是最快的。
* The key feature of this algorithm is that insertions into the string
* dictionary are very simple and thus fast, and deletions are avoided
* completely.
* 该算法的主要特性是对字典区块(就是滑动窗口中已经处理过的那部分
* 字符组成的字典,由哈希表实现)插入(新词条)的操作简洁且快速,
* 同时还完全地避免了删除(词条)的操作。
* Insertions are performed at each input character, whereas
* string matches are performed only when the previous match ends. So it
* is preferable to spend more time in matches to allow very fast string
* insertions and avoid deletions.
* 每读到一个新字符都会进行一次(字典区块的)插入操作,而匹配操作仅当
* 之前的一次操作完成时才会开始进行。所以总是希望可以通过适当增加匹配操作
* 时间来减少插入操作的时间。
* The matching algorithm for small
* strings is inspired from that of Rabin & Karp. A brute force approach
* is used to find longer strings when a small match has been found.
* A similar algorithm is used in comic (by Jan-Mark Wams) and freeze
* (by Leonid Broukhis).
* A previous version of this file used a more sophisticated algorithm
* (by Fiala and Greene) which is guaranteed to run in linear amortized
* time, but has a larger average cost, uses more memory and is patented.
* However the F&G algorithm may be faster for some highly redundant
* files if the parameter max_chain_length (described below) is too large.
* (此处为介绍各种技巧思路的来源以及同之前版本的对比,无太大意义,故不译。)
*
* ACKNOWLEDGEMENTS
*
* The idea of lazy evaluation of matches is due to Jan-Mark Wams, and
* I found it in 'freeze' written by Leonid Broukhis.
* Thanks to many info-zippers for bug reports and testing.
*
* REFERENCES
*
* APPNOTE.TXT documentation file in PKZIP 1.93a distribution.
*
* A description of the Rabin and Karp algorithm is given in the book
* "Algorithms" by R. Sedgewick, Addison-Wesley, p252.
*
* Fiala,E.R., and Greene,D.H.
* Data Compression with Finite Windows, Comm.ACM, 32,4 (1989) 490-595
* (此处亦为介绍各种技巧思路的来源以及同之前版本的对比,无太大意义,故不译。)
*
* INTERFACE
* 2个接口函数
* void lm_init (int pack_level, ush *flags)
* Initialize the "longest match" routines for a new file
* 初始化函数,启动LZ77压缩进程;
* ulg deflate (void)
* Processes a new input file and return its compressed length. Sets
* the compressed length, crc, deflate flags and internal file
* attributes.
* LZ77压缩主进程都在该函数里。
*/
*(ii.)接下来开始分析函数 void lm_init (int pack_level, ush flags):
这里对哈希表的初始化可能有些令人疑惑,实际上,此处的哈希表并非由链接法或开域法实现,
而是由2个数组构成的,这样做的原因是节约空间,避免node的空间申请与删除。
(看不清楚请点右键在新选项卡中打开)
如图,哈希表由2个数组head[WSIZE]与prev[WSIZE]构成,WSIZE = ox8000 = 32k,
这两个数组构成了许多条链,所有由一个特定哈希函数取到相同哈希码的字符串们组成一条链。
head[]装载所有链头串的地址,prev[]则记录串与串之间的链接关系。链的具体实现方式稍后会解释。
顺便一提,这种链的构造方式与boost库的内存池很相似。
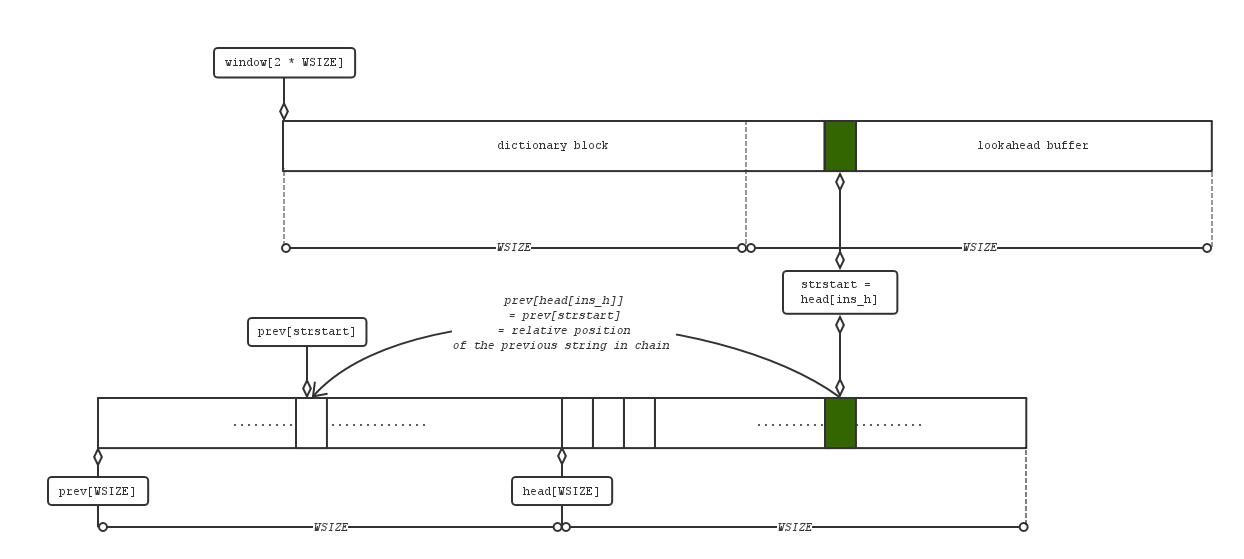
其次,在查找匹配串的时候使用了lazy match技术,就是说如果当前这对匹配串不够长,就把
strtsart指针继续右移一个字符,看看接下来找到的匹配串是不是更好。
/* ===========================================================================
* Initialize the "longest match" routines for a new file
*/
void lm_init (pack_level, flags)
int pack_level; /* 0: store, 1: best speed, 9: best compression */
ush *flags; /* general purpose bit flag */
{
register unsigned j;
if (pack_level < 1 || pack_level > 9) error("bad pack level");
compr_level = pack_level;
/* Initialize the hash table.
* 将head数组初始化
*/
#if defined(MAXSEG_64K) && HASH_BITS == 15
for (j = 0; j < HASH_SIZE; j++) head[j] = NIL;
#else
memzero( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









