







是一种数据存储格式,特点是可以在保存数据时同时保存和处理数据之间的关系
可以自定义标签,利用这些标签来保存数据,利用标签之间的嵌套关系来保存数据的层级关系
利用跨平台的特性,在不同的系统和开发语言之间传输数据---android和服务器之间传输数据
利用可以保存数据关系的特点,用来作为配置文件来使用
xml格式的数据可以保存在一个文件中,文件名通常后缀取为.xml这样的文件称为xml文件
浏览器可以解析xml格式的数据,我们可以利用浏览器来校验xml是否正确
二、xml语法
1.文档声明:用来声明xml的基本属性的,xml解析器通过xml的文档声明了解xml的基本属性,从而决定如何解析xml
通常来说,xml中必须有且只能有一个文档声明,并且这个文档声明要求出现在整个xml的最前面,在他之前不能有任何其他内容
如果一个xml没有文档声明,有些时候也是可以使用的,但是这样的xml我们称之为格式不良好的xml,应该避免这样去做
(1)<?xml version="1.0" ?> version属性用来声明xml所遵循的规范的版本,目前就是写1.0即可.version属性是必须存在的属性
(2)<?xml version="1.0" encoding="gbk" ?>encoding属性表明当前xml所使用的编码,encoding属性是可选的默认值是iso8859-1
(3)<?xml version="1.0" encoding="gbk" standalone="yes" ?>standalone属性用来声明文档是否是一个独立的文档,如果当前文档不是独立的文档则standalone要赋值为no 如果是独立的文档,则赋值为yes ,默认值是yes.standalone是可选的属性
*不同的浏览器在实现xml规范是有时会由细微的差别,我们不要太纠结于这些差别,应该按照标准去学习
2.元素:xml中自定义的标签就叫做元素
自闭标签
标签的合理嵌套
一个格式良好的xml,要求有且仅有一个根标签,其他所有的标签应该是这个根标签的子孙标签
xml中元素的命名规范:
区分大小写,例如,<P>和<p>是两个不同的标记。
不能以数字或标点符号或"_"开头。
不能以xml(或XML、或Xml 等)开头。
不能包含空格。
名称中间不能包含冒号(:)。
一个元素上可以自定义多个属性
属性是由名值组成,其中值要用双引号或单引号引起来
属性的名称在定义的过程中也要遵循xml的命名规范
4.注释
<!-- 注释内容 -->
注释不能嵌套注释
注释不能出现在文档声明之前
5.CDATA区、转义字符
CDATA区:放在CDATA区内的内容不会被浏览器解析,会原样输出到浏览器上
<![CDATA[
大段内容
]]>
转义字符:
& --- &
< --- <
> --- >
" --- "
' --- '
6.处理指令 PI
通知解析引擎如何处理xml中的内容
三、DTD
约束
DTD约束
Schema约束
0*.写一个js代码,校验DTD
1.如何在xml中引入DTD校验
(1)外部引入:将dtd文件中的约束引入xml
本地文件引入:
在xml的任意位置,但是推荐就在文档声明之下,写
<!DOCTYPE 根元素的名称 SYSTEM "文件URL">
公共位置上的文件:
<!DOCTYPE 根元素的名称 PUBLIC "dtd的名" "dtd文件的URL">
(2)内部引入:在xml内部直接书写dtd规则
<!DOCTYPE 根元素的名称 [
....
]>
2.dtd语法
(1)约束元素
<!ELEMENT 元素的名称 元素的约束>
元素的约束:
~1.存放类型
EMPTY:表明当前标签中不能包含任何东西
ANY:表明当前标签中可以存放任何东西
~2.子元素的列表:用小括号括起来的子元素的声明
子元素如果用逗号进行分割,表明必须按顺序出现
子元素如果用竖线进行分割,表明只能出现其中一个
+:表明出现一次或多次
*:表明出现零次或多次
?:表明出现零次或一次
还可以使用小括号进行组的操作
#PCDATA 在其中象征标签体
<!ELEMENT MYFILE ((TITLE*, AUTHOR?, EMAIL)* | COMMENT)>
(2)约束属性
<!ATTLIST 元素名
属性名 属性类型 属性约束
....>
~1.属性类型
CDATA:表示属性值为普通文本字符串
ENUMERATED (科技类|文学类|....)
ID : ID 属性的值只能由字母,下划线开始,不能使用数字,不能出现空白字符
ENTITY
~2.属性约束
#REQUIRED 当前属性是必须存在的属性
#IMPLIED 当前属性是一个可选的属性
#FIXED "固定值" 当前的属性取值是一个固定值,可以不给属性赋值,则属性的值就是这个固定值,如果明确的给这个属性赋值,而值又和固定值不同,则校验不通过
"默认值" 如果属性没有赋值,则取值自动为默认值,如果给了值则取给的值
(3)ENTITY(实体)
~1.引用实体:在xml中引用
<!ENTITY 实体名称 '实体的内容'>
在xml中可以通过 &实体名称; 的方式进行引用
~2.参数实体:在dtd中引用
<!ENTITY % 实体名称 '实体内容'>
在dtd中可以通过 %实体名称; 的形式进行引用
四、xml编程
1.两种解析思想:dom sax
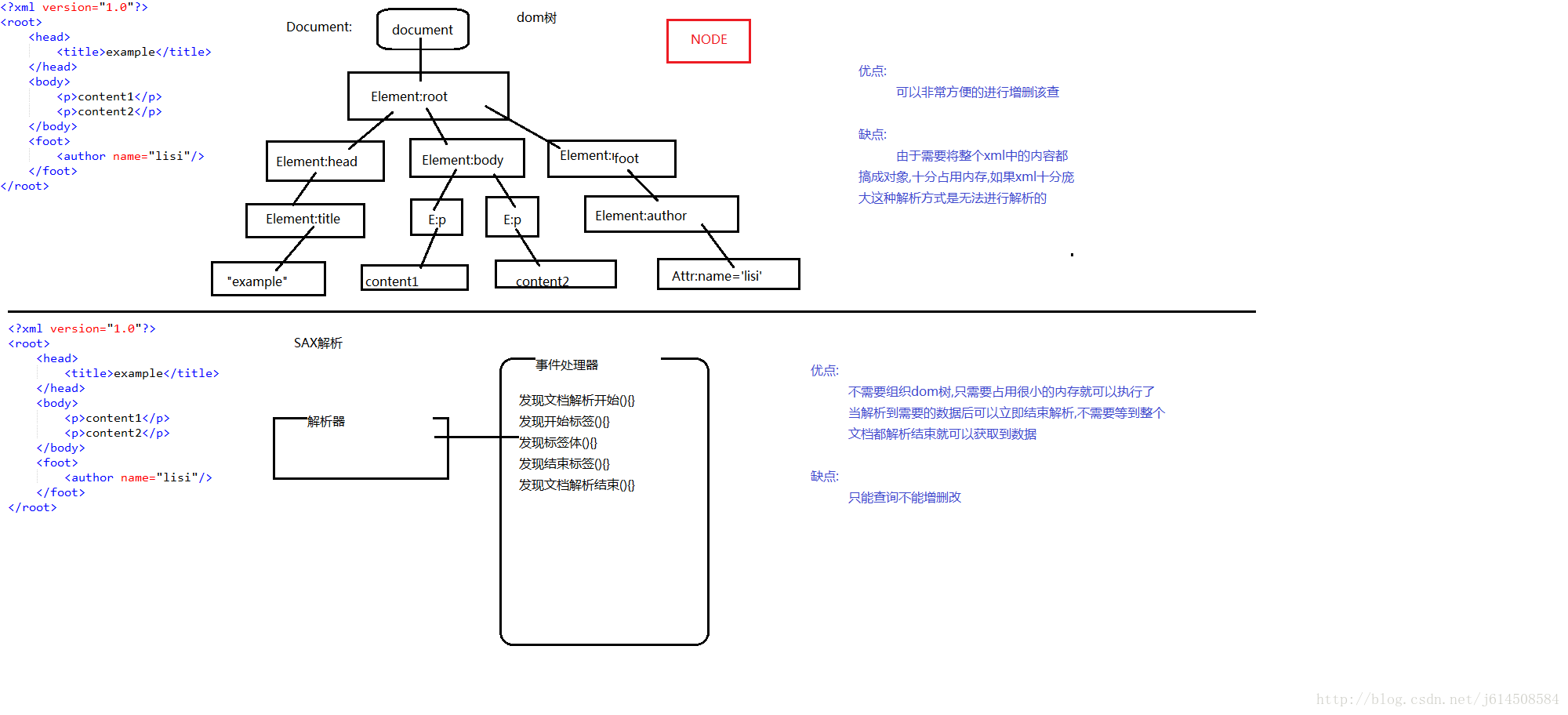
2.JAXP DOM4J
JAXP:sax dom
DOM4J:
你所应该知道的Dom4J
创建解析器:
SAXReader reader = new SAXReader();
利用解析器读入xml文档:
Document document = reader.read(new File("input.xml"));
获取文档的根节点:
Element root = document.getRootElement();
接口继承结构:
Node ---
Branch
--Document
--Element
----
Attribute
Node接口
| String | asXML() 将一个节点转换为字符串 |
| String | getName() 获取节点的名称,如果是元素则获取到元素名,如果是属性获取到属性名 |
| short | getNodeType() 获取节点类型,在Node接口上定义了一些静态short类型的常量用来表示各种类型 |
| Element | getParent() 获取父节点,如果是根元素调用则返回null,如果是其他元素调用则返回父元素,如果是属性调用则返回属性所依附的元素。 |
| String | getText() 返回节点文本,如果是元素则返回标签体,如果是属性则返回属性值 |
| List | selectNodes(String xpathExpression) 利用xpath表达式,选择节点 |
| void | setName(String name) 设置节点的名称,元素可以更改名称,属性则不可以,会抛出UnsupportedOperationException 异常 |
| void | setText(String text) 设置节点内容,如果是元素则设置标签体,如果是属性则设置属性的值 |
| void | write(Writer writer) 将节点写出到一个输出流中,元素、属性均支持 |
Branch接口(实现了Node接口)
| void | add(Element element) 增加一个子节点 |
| Element | addElement(QName qname) 增加一个给定名字的子节点,并且返回这个新创建的节点的引用 |
| int | indexOf(Node node) 获取给定节点在所有直接点中的位置号,如果该节点不是此分支的子节点,则返回-1 |
| boolean | remove(Element element) 删除给定子元素,返回布尔值表明是否删除成功。 |
Element接口(实现了Branch, Node接口)
| void | add(Attribute attribute) 增加一个属性 |
| Element | addAttribute(QName qName, String value) 为元素增加属性,用给定的属性名和属性值,并返回该元素 |
| Element | addAttribute(String name, String value) 为元素增加属性 |
| Attribute | attribute(int index) 获取指定位置的属性 |
| Attribute | attribute(QName qName) 获取指定名称的属性 |
| Iterator | attributeIterator() 获取属性迭代器 |
| List | attributes() 获取该元素的所有属性,以一个list返回 |
| String | attributeValue(QName qName) 获取指定名称属性的值,如果不存在该属性返回null,如果存在该属性但是属性值为空,则返回空字符串 |
| Element | element(QName qName) 获取指定名称的子元素,如果有多个该名称的子元素,则返回第一个 |
| Element | element(String name) 获取指定名称的子元素,如果有多个该名称的子元素,则返回第一个 |
| Iterator | elementIterator() 获取子元素迭代器 |
| Iterator | elementIterator(QName qName) 获取指定名称的子元素的迭代器 |
| List | elements() 获取所有子元素,并用一个list返回 |
| List | elements(QName qName) 获取所有指定名称的子元素,并用一个list返回 |
| String | getText() 获取元素标签体 |
| boolean | remove(Attribute attribute) 移除元素上的属性 |
| void | setAttributes(List attributes) 将list中的所有属性设置到该元素上 |
Attribute接口(实现了Node接口)
| QName | getQName() 获取属性名称 |
| String | getValue() 获取属性的值 |
| void | setValue(String value) 设置属性的值 |
DocumentHelper 类
| static Attribute | createAttribute(Element owner, QName qname, String value) 创建一个Attribute | |
| static Document | createDocument() 创建一个Document | |
| static Document | createDocument(Element rootElement) 以给定元素作为根元素创建Document | |
|
| static Element | createElement(QName qname) 以给定名称创建一个Element |
| static Document | parseText(String text) 将一段字符串转化为Document |
将节点写出到XML文件中去
方法1:
调用Node提供的write(Writer writer) 方法,使用默认方式将节点输出到流中:
node.write(new FileWriter("book.xml"));
乱码问题:
Dom4j在将文档载入内存时使用的是文档声明中encoding属性声明的编码集进行编码, 如果在此时使用writer输出时writer使用的内部编码集与encoding不同则会有乱码问题。
FileWriter默认使用操作系统本地码表即gb2312编码,并且无法更改。
此时可以使用OutputStreamWriter(FileOutputStream("filePath"),"utf-8");的方式自己封装 一个指定码表的Writer使用,从而解决乱码问题。
方式2:
利用XMLWriter写出Node:
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(node);
writer.close();
乱码问题:
(1)使用这种方式输出时,XMLWriter首先会将内存中的docuemnt翻译成UTF-8 格式的document,在进行输出,这时有可能出现乱码问题。
可以使用OutputFormat 指定XMLWriter转换的编码为其他编码。
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
(2)Writer使用的编码集与文档载入内存时使用的编码集不同导致乱码,使用字节流 或自己封装指定编码的字符流即可(参照方法1)。
你所应该知道的XPATH
1.从根路径开始的绝对路径方式获取/AAA
例子:获取所有AAA下的BBB下的所有CCC:/AAA/BBB/CCC
2.所有指定名称的元素//AAA
例子:获取所有名称为AAA的元素
3.使用*号匹配福获得所有满足条件的元素
例子:获取AAA下BBB下所有的元素:/AAA/BBB/*
4.使用中括号,获取多个匹配元素中的某一个,可以使用last()函数获取最后一个
例子:获取AAA下所有BBB的第二个:/AAA/BBB[2]
例子:获取AAA下所有BBB的最后一个:/AAA/BBB[last()]
5.指定某一属性:@AttName,可以配合中括号使用
例子:获取所有id属性://@id
例子:获取所有具有id属性的BBB元素://BBB[@id]
例子:获取所有不具有属性的BBB元素://BBB[not(@*)]
例子:获取属性的值为某一个固定值的BBB元素://BBB[@id='b1']














 7750
7750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









