







1. 什么是数据不平衡问题
当数据集中样本类别不均衡时我们就说发生了数据不平衡问题。
2. 解决数据不平衡问题的方法
为了方便起见,把数据集中样本较多的那一类称为“大众类”,样本较少的那一类称为“小众类”。
2.1. 采样法
采样法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集。
采样法分为过采样(Over Sampling)和欠采样(Under Sampling),过采样是把小众类复制多份,欠采样是从大众类中选取部分样本。
过采样的缺点:训练数据集中会反复出现一些相同的样本,训练出来的模型容易表现出过拟合现象。为了解决过采样的弊端,可以在新生成的数据点中加入轻微的随机扰动,经验表明这种做法非常有效。
欠采样的缺点:训练数据集中部分信息丢失,训练出来的模型容易表现出欠拟合现象。由于欠采样会丢失信息,解决此弊端的方法有两种:EasyEnsemble和BalanceCascade。
EasyEnsemble:使用自助采样法在大众类数据集中采出多个采样集,将小众类样本分别和大众类采样集结合,训练出多个模型,组合多个模型的结果,得到最终的结果。
BalanceCascade:先通过一次欠采样产生训练集,训练一个分类器,然后使用该分类器对大众类中的样本进行分类,在分类错误的样本集中再次使用欠采样产生训练集,训练第二个分类器,以此类推,最后组合所有分类器的结果得到最终结果。
2.2. 数据合成法
数据合成方法是利用已有样本生成更多样本,这类方法在小数据场景下有很多成功案例,比如医学图像分析等。
SMOTE(Synthetic MinorityOversampling Technique)即合成少数类过采样技术,其思想是:对每个少数类样本a,从与它的最近邻的k个样本中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
对于小众类样本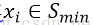
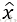
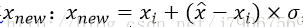
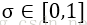
SMOTE缺点:增加了类之间重叠的可能性;生成一些没有提供有效信息的样本。
解决SMOTE算法的弊端,改进的方法为Borderline-SMOTE。
Borderline-SMOTE的思想是只为小众类的边界样本生成新样本,即那些周围大部分是大众类样本的小众类样本生成新样本。
为每个小众类样本找出其最近邻的k个样本,若k个样本中有一半以上都是大众类样本,则为该小众类样本生成新样本。生成新样本时使用SMOTE。
2.3. 代价敏感学习法
采样算法从数据层面解决了数据不平衡的学习问题,而在算法层面上解决数据不平衡的方法主要是代价敏感学习法(Cost-SensitiveLearning)。
代价敏感学习法的核心要素是代价矩阵,由类别误判的惩罚系数构成。基于代价矩阵,可将数据不平衡问题简化为:在当前数据集和代价矩阵下,使所有样本分类后的结构风险最小化的最优化问题。
3. 如何选择解决数据不平衡问题的方法
在正负样本都非常之少的情况下,应该采用数据合成的方式;在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样法或代价敏感学习法。
4. 数据不平衡问题模型评估
正确率、F度量、ROC曲线














 2742
2742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









