







想要体验一下的强大功能,手头的资源各种受限,无奈只能配置个伪分布的自己耍耍,不过对于学习简单地使用hadoop还是没有问题的。下面列出操作的步骤:
ps: 本操作都是在root用户下进行的
1. 安装JDK和Hadoop2.6.4
去oracle的官网下载恰当版本的jdk,建议jdk7 或者jdk 8,这里以jdk-8u91-linux-x64.tar.gz 为例。下载完之后,将其解压到/usr/local/installed 目录的下
tar -zxvf jdk-8u91-linux-x64.tar.gz -C /usr/local/installed/
去hadoop官网下载hadoop 2.6.4,下载完成之后,也将其解压到/usr/local/installed目录下
tar -zxvf hadoop-2.6.4.tar.gz -C /usr/local/installed
2. 配置HADOOP_HOME和JAVA_HOME
我这里主要将环境配置root用户目录下的,所以按照如下操作
vim ~/.bash_profile
在其中加入如下内容
HADOOP_HOME=/usr/local/installed/hadoop-2.6.4
JAVA_HOME=/usr/local/installed/jdk-8u91
将其添加到PATH中
PATH= PATH: HADOOP_HOME/bin:$JAVA_HOME/bin
保存退出后,将配置生效
source ~/.bash_profile
3. 修改hadoop-env.sh
进入hadoop的安装目录中的#HADOOP_HOME/etc/hadoop目录下,设置一下JAVA_HOME
export JAVA_HOME=/usr/local/installed/jdk-8u91
4. 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/installed/hadoop-2.6.4/tmp</value>
</property>
</configuration>上面的主机名称,请根据自己的主机配置一下,另外值得提醒一下的是临时目录的配置,需要实现创建/usr/local/installed/hadoop-2.6.4/tmp 目录
5. 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> 其中,副本数必须设置为1,因为是伪分布式,就一台机器
其次,访问namenode的hdfs使用的是50070端口,访问datanode的webhdfs使用50075端口。
如果想不区分端口,直接使用namenode的IP和端口来进行所有的webhdfs操作,就需要在所有的datanode上都设置hdfs-site.xml中的dfs.webhdfs.enabled为true。 当然这项配置不是必须的,可根据需要自行加入
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>6. 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 这里配置为yarn是方便后续的与spark进行集成的
7. 配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 至此,准备工作已经完成,下面开始格式化hdfs文件系统,并测试
8. 格式化hdfs 并启动hdfs
在命令行中运行如下
hdfs namenode -format
如果格式化,成功会有提示信息,出错的话则自己根据Log排除一下,主要的错误原因就是在配置的时候误写导致的。
启动hdfs:进入hadoop按照目录下的sbin中。即
cd $HADOOP_HOME/sbin
./start-dfs.sh
成功启动后,使用jps可以查看到如下的进程的信息:

至此,你就可以对hdfs 文件系统的进行各种操作了,如查看根目录下的文件内容
hdfs dfs -ls /
其他的操作使用 hdfs dfs 回车后查看帮助信息
还可以浏览器中输入http://localhost:50070进行查看
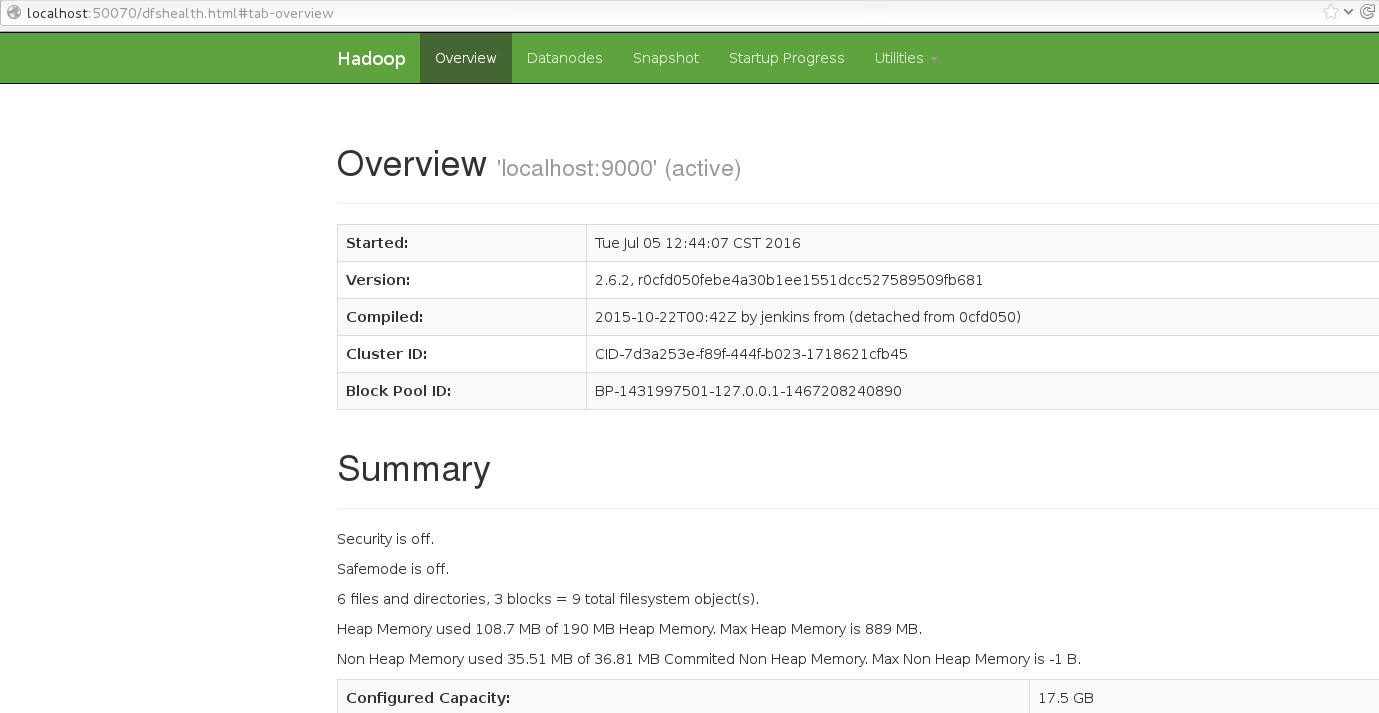
9. 启动yarn集群
上面的操作已经成功的配置并启动的hdfs文件系统,下面启动yarn并查看其web界面
进入hadoop的安装目录下的sbin目录,即
cd $HADOOP_HOME/sbin
./start-yarn.sh
成功启动后,使用jps可以查看到如下的新增加的进程的信息

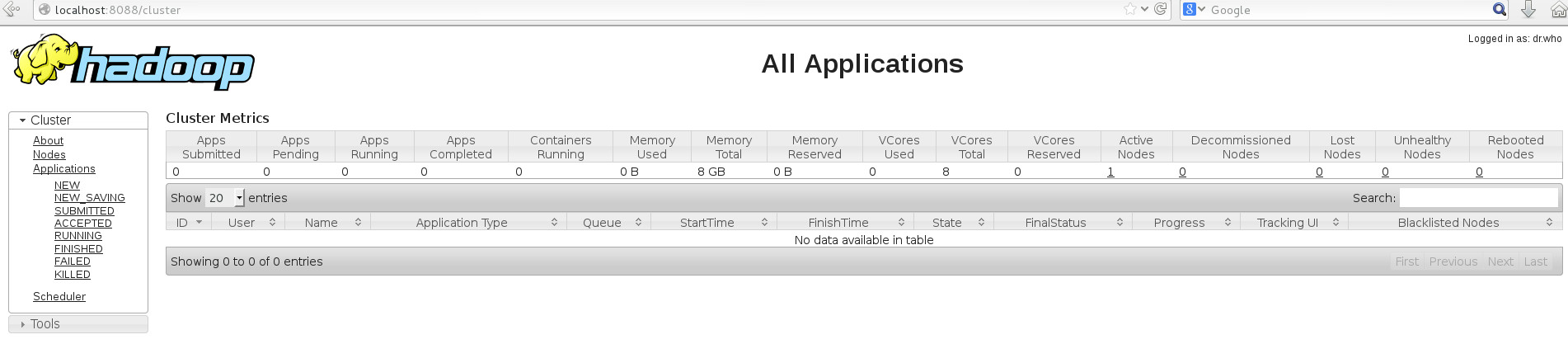
看上以上信息,则说明yarn也成功启动了
这时候可以在浏览器中输入http://localhost:8088进行查看yarn的监控界面















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









