







java.util
类Properties是hashtable的子类, (集合中涉及到IO流的对象)
也就是说它具备map集合的特点,而且它里面存储的键值对都是字符串.
是集合中和IO技术相结合的集合容器
该对象的特点,可以用于键值对形式的配置文件
在加载数据时,需要数据有固定格式:键=值(#开头的都是注释)
将一文件中的数据存储到Properties集合中.
思路:1,用一个流和文件关联
2读取一行数据将改行数据用”=”进行切割
3,等号左边作为键,右边作为值.存入到Properties集合中.


实例:
import java.io.*;
import java.util.*;
class PropertiesDemo{
public static void main(String[] args)throws IOException{
BufferedReader bure=new BufferedReader(new FileReader("Blog.txt"));
Properties pro=new Properties();
String line=null;
while((line=bure.readLine())!=null){
String[] str=line.split("=");//将字符串以”=”分开存放到数组
pro.setProperty(str[0],str[1]);
}
System.out.println(pro);
}
}
替代以上方法,上面方法的封装版:
第二个,参数为字符流的第而个load方法,是1.6版本开始的.

实例:
public static void main(String[] args)throws IOException{
Properties pro=new Properties();
FileReader fr=new FileReader("Blog.txt");
pro.load(fr);
System.out.println(pro);
}
将一Properties集合中的数据,存储到指定文件中:
第二个,参数为字符流的第而个store方法,是1.6版本开始的.comments为注释.(支持英文)

实例:
class PropertiesDemo{
public static void main(String[] args)throws IOException{
Properties pro=new Properties();
FileWriter fr=new FileWriter("Blog.txt");
pro.setProperty("颜色","红色");
pro.store(fr,"hiahia");
System.out.println(pro);
}
}
练习:
/*需求:编写一个用于记录应用程序运行次数的程序.
如果使用次数达到规定次数,那么就发出注册提示
*/下面是毕老师的分析:

实例代码:
class PropertiesDemo{
public static void main(String[] args)throws IOException{
Properties prop=new Properties();//建立properti集合,存储数据对
File file=new File("blog.txt");//用File封装日志文件
if(!file.exists())//判断日志文件是否存在,不存在就创建一个
file.createNewFile();
FileInputStream fis=new FileInputStream(file);//建立输入流,把日志文件数据读取到流中
prop.load(fis);//将流中的日志文件数据读取到properties集合中.
int count=0;//定义计数器
String value=prop.getProperty("lock");//获取lock键值
if(value!=null){//判断该键是否为空
count=Integer.parseInt(value);//不为空,就将该值转为int类型.赋给计数器.
if(count>=5)//判断该值是否超过次数
{
System.out.println("您的次数已到,请注册");//超出后,发出警告.
return;
}
}
//如果,value不为空,证明,该软件第一次启动,就将计数器0+1,先存储到Properties集合中.
count++;
prop.setProperty("lock",count+"");
//建立输出流,指定好文件
FileOutputStream fos=new FileOutputStream(file);
//调用,store方法,将properties中的数据赋到制定日志文件.永久保存.....
prop.store(fos,"");
fos.close();
fis.close();
}
}打印流,可以直接操作输入流和文件
字符PrintWriter打印流很吊的对象一般和文件有联系的都很吊
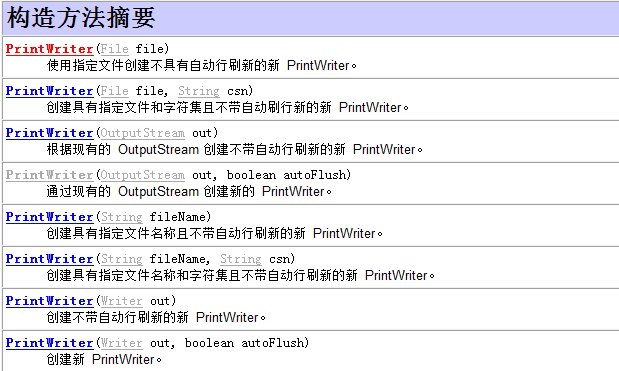
该流提供了打印方法,可以将各种数据类型的数据都原样打印
字节打印流: PrintStream
构造函数可以接受的参数类型:
1,file对象File
2,字符串路径String
3,字节输出流OutputStream
字符打印流:
PrintWriter
构造函数可以接受的类型:
1,file对象File
2,字符串路径String
3,字节输出流OutputStream
5,字符输出流Writer
很给里的构造方法………(OutputStream out,boolean autoFlush)
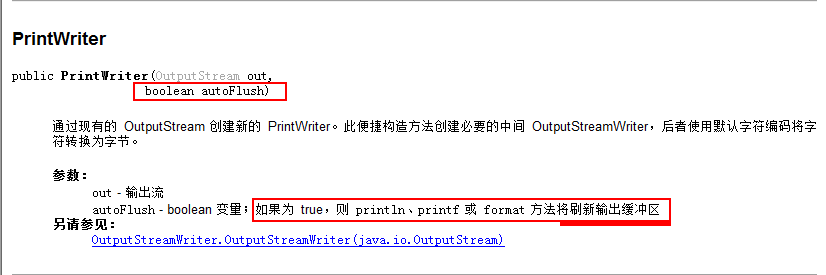
即要望文件中高数据又想自动刷新,,,,直接把文件封装到流中就搞定………..
PrintWriter out =new PrintWriter(new FileWriter(“a.txt”),true)
java.io
类 序列流SequenceInputStream
public class SequenceInputStream extends InputStream
对多个流进行合并
SequenceInputStream [数][计] 序列表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。

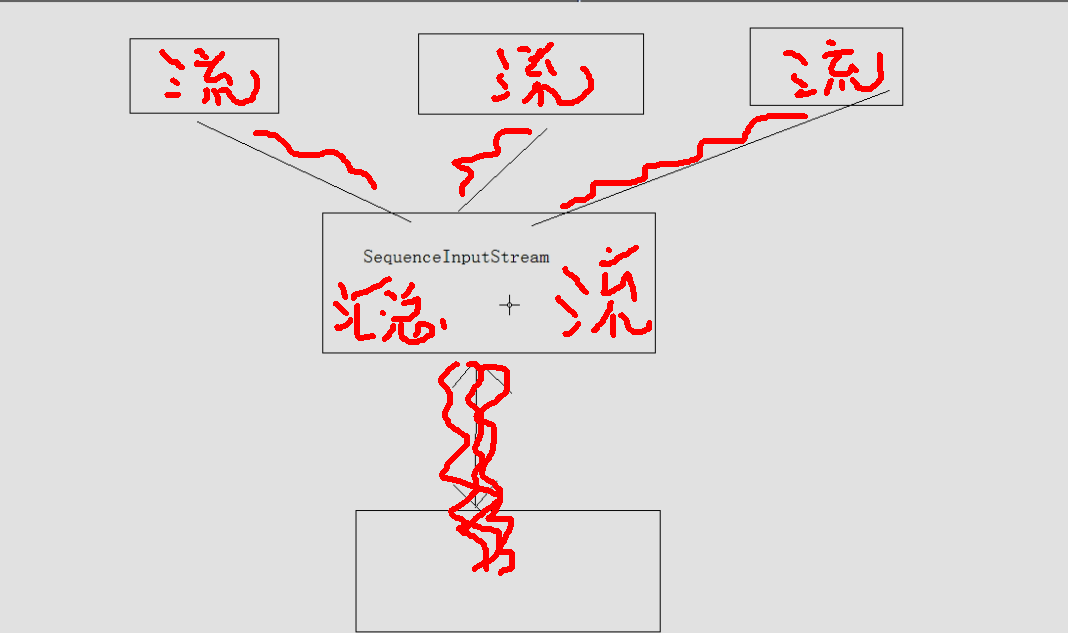
实例:
SequenceInputStream[序列](Enumeration<? extends InputStream> e)
想汇总更多流需要,涉及到Enumeration枚举.只有Vector中有………
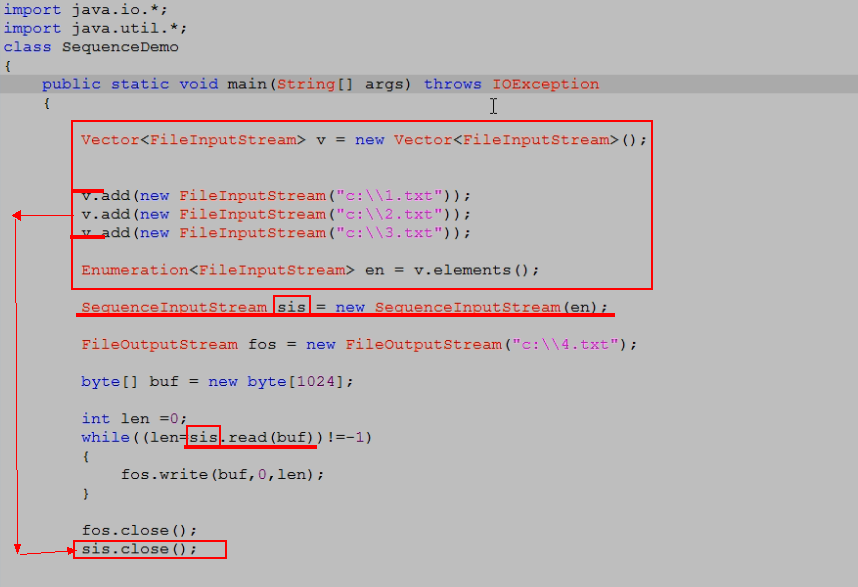
Vector是线程同步的效率不怎么高,看看换成ArrayList是如何,最后用上枚举的:
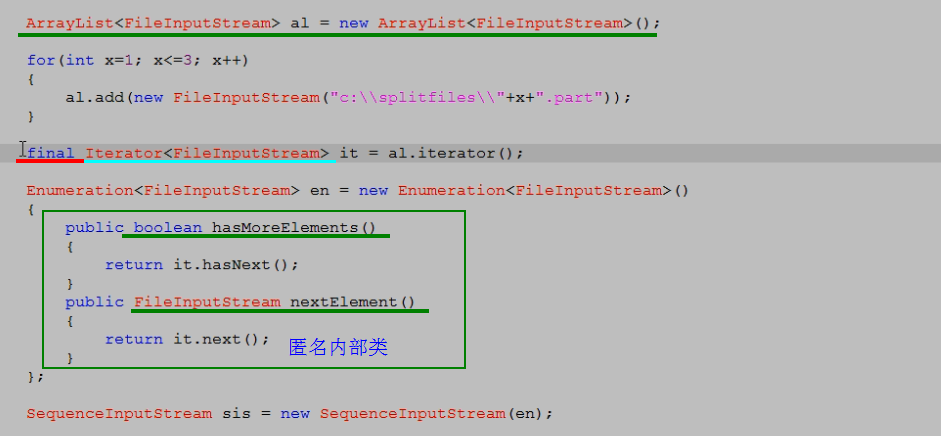
关掉总流,其他三个小流也就随之关掉……
切割文件

切txt文件
public static void main(String[] args)throws IOException{
FileWriter fw=new FileWriter("Test.txt");
fw.write("你好啊我好啊他好啊");
fw.close();
//建立一个字节流,将文件输入到流中操作
FileInputStream fis=new FileInputStream("Test.txt");
FileOutputStream fos=null;
byte[] by=new byte[6];//规定三个文字分成一个txt文件...
int i=0;
int count=1;//计数器....
while((i=fis.read(by))!=-1){
fos=new FileOutputStream((count++)+"split.txt");
fos.write(by,0,i);
fos.close();
}
fis.close();
}














 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









