







Python中关于“中文乱码”的问题,现规整如下,并统一回答
同学问:
jacky:我在爬取XX网站信息的时候,中文怎么总是显示的乱码?
jacky:UTF-8与GBK到底是个啥?
jacky:我用的是Mac系统,网上说Python3中默认的编码是UTF-8,可我显示中文时怎么还是乱码?
(一)逻辑导图
(二)基础铺垫
1.计算机的底层逻辑
2.字符编码
计算机只认二进制的“0”和“1”
ASCII
这个世界的规则就是谁发起,谁定规则。计算机是美国人发明的,在开发计算机的时候,美国人只考虑到了英文的兼容性,并没有考虑包括中文在内的其他语言。
英语构成计算机最底层的元素就是:26个英语字母,加上特殊字符,加上数字。
(1)发明计算机时,字符编码使用的是ascii码,包括Python2默认的字符编码就是ascii码(Python3默认使用的是UTF-8,详见下文);
(2)ascii码为1字节(8位)
8位二进制(例如:01010101)有多少种排列组合? 28 =256种可能
对于英文来说,8位二进制足够用了,所有python2还默认ascii码也不足为奇。
Unicode(万国码)
- 全球化和科技共享,让计算机的开发者认识到,要开发一种各国语言都能兼容的编码,就有了unicode,也叫万国码。
(1)unicode 包含各国所有的语言文件和符号,对于中文来说,8位已经不够用了,unicode规定:一个中文汉字最少用3个字节来表示。
- 一个字节是8位,1byte=8bit=01010101,一个汉字最少有2的24次方种组合
(2)Python中可以用bin函数将十进制转化为二进制
bin(82)
'0b1010010' #b表示的R是二进制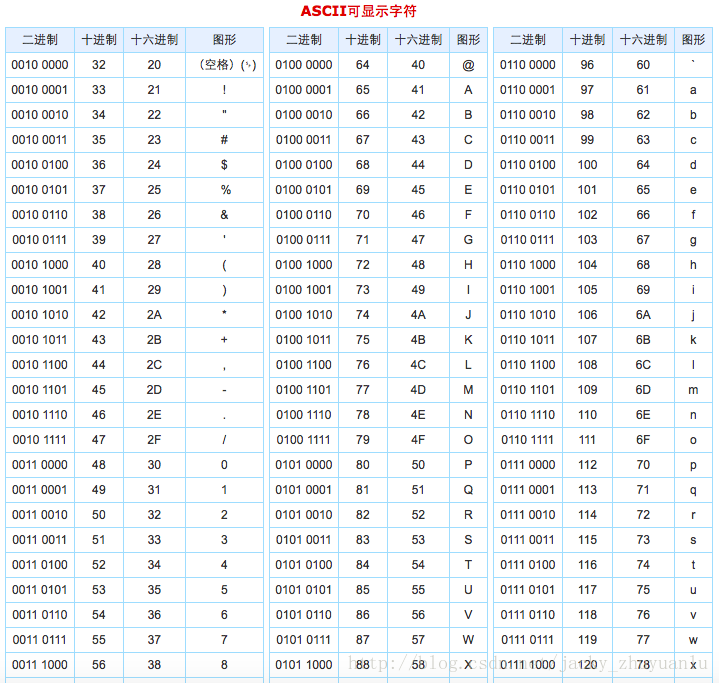
(3)万国码的弊端
占内存和硬盘
- 用英文字母R举例:如何用ascii码表示为’0b1010010’,如何用万国码表示为
‘000000000b1010010’,因为万国码,最少是2个字节,与ascii相比,万国码白白浪费了1个字节的空间。
- 用英文字母R举例:如何用ascii码表示为’0b1010010’,如何用万国码表示为
针对unicode的弊端,如今的开发者,又对unicode进行了精简,开发了UTF-8编码
(4)特别说明(读完下文在回来看,就好理解了)
- Unicode是Python的内部编码,也是编码和解码的中间编码。
UTF-8编码
- UTF-8编码是对unicode 的一个再加工
- 对unicode 的编码进行了划分和整理,用8位的就划分为用8位的,不额外在用空间
- 规则:
- 英文:8位
- 欧洲:16位
- 中文:24位
- 特别说明:在Unicode编码方式下,才存在 utf-8,utf-16,utf-32的编码方式,这句话对于解释下文的解码与编码特别重要
GBK编码
| UTF-8 | GBK(@数据分析-jacky) |
|---|---|
| 外国人开发 | 中国人开发 |
| 外国人看不会乱码 | 外国人看会乱码 |
| 一个汉字占3个字节 | 一个汉字占2个字节 |
(三)编码与解码
1、基础内容
编码:将字符转化为二进制字节的过程
解码:将二进制字节转化为字符的过程
2、解码和编码的实现方法
(1) 基本逻辑
字符串在Python内部的表示是Unicode编码。
因此在做编码转换时,通常需要以Unicode作为中间编码,即先将其他编码的字符串解码(decode)成Unicode,再从Unicode编码(encode)成另一种编码。
(2) encode与decode
decode的作用是将其他编码的字符串转换成Unicode编码,如str1.decode(‘gbk’),表示将gbk编码的字符串str1转换成Unicode编码;
encode的作用是将Unicode编码转换成其他编码的字符串,如str2.encode(‘UTF-8’),表示将Unicode编码的字符串str2转换成UTF-8编码因此,使用Python转码的时候一定要先搞明白,字符串str是什么编码,然后decode成Unicode,然后再encode成其他编码。
特别注意:
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断:
用非unicode编码形式的string来encode也会报错
(3)支持字符串类型的两种数据模型
python编码有两种数据模型来支持字符串类型 :
- 一种是str ;
- 一种是unicode
(四)解决Python乱码的思路
代码的实现方式:
decode()->unicode->encode转化为需要的格式实战案例:
content为从文件中读取的gbk编码的内容,我们通过以上方法输出该内容。
content.decode('gbk').encode('utf-8') - decode方法将content内容转为unicode格式
- encode方法将unicode格式的数据转化为自己所需要的编码方式。
(五)数据科学领域需注意的问题
作为数据分析(挖掘)师,python与数据库的关联是最常见的,我们用python连接数据库后,将数据写到数据库里的中文有时会是乱码
解决办法是在python文件中加上这样几句话:
conn.set_character_set('utf8')
cur.execute('SET CHARACTER SET utf8')
cur.execute('SET character_set_connection=utf8')- conn是数据库的connection,cur是connection的光标cursor















 7682
7682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











