







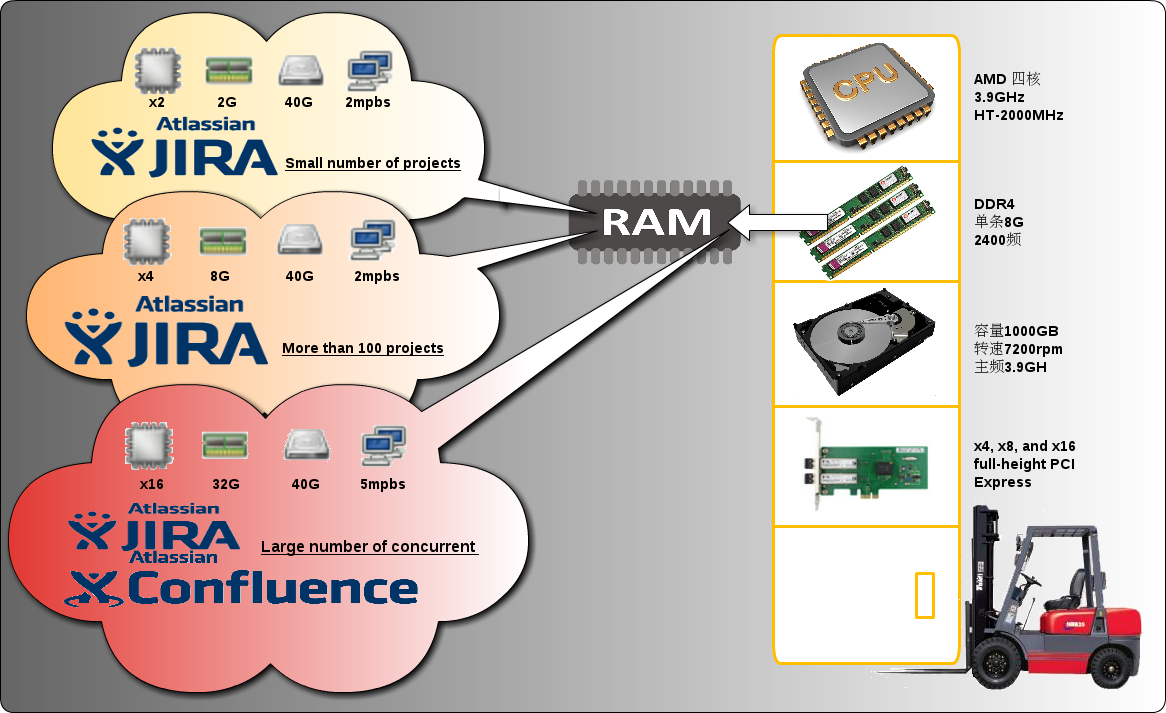
Atlassian server-side 云端规格
云端规格它算是逻辑规格,而不是物理规格。以 IaaS 云端供应商来说,不外乎就是针对 CPU/內存/硬盤 这三个主要资源的规格在作区别,Atlassian 全系列产品都需要运行在操作系统的平台上,每个产品所需要的资源又不尽相同,在这里就以 jira/confluenc 所需要的最小规格需求,還有大型环境所需要的规格来作个剖析,进而了解开发平台软件,所依赖的操作系统,规格的定义确实不容易。在依据原厂即有的准则,我们又该如何提供适当的资源,来满足客户端的规模。
逻辑规格还是物理规格 (Specifications)
物理规格的定义是可以很明确的,比如 内存(DDR4/单条8G/2400频)CPU(AMD四核/3.9GHz/HT-2000MHz)硬盘(容量1000GB/转速7200rpm/主频3.9GHz)。
云端的逻辑规格就没这么详述了,尤其针对 内存 及 CPU 的频率,供应商并不会明定频率,因为这部份其实就是一个池(pool),但也因为如此,让我们可以很简单的,只针对CPU及内存的数量与容量跟云端供应商购买。
如下圖顯示,在雲實例中的邏輯規格,其實整個都是在內存中運行,也因此同樣的 CPU 核心數及 內存 容量,虛擬主機跟物理主機比較起來,其實虛擬主機的效能是會高一些的。
中央处理器(CPU,Central Processing Unit)
CPU是运算负载的重要引擎,运算的能力决定着 AP 反应时间的快慢,云端上的逻辑规格并没有频率可以选择,也因此你只能增加核心数量来提升CPU的运算能力,交付给 CPU 处理的程序如果愈复杂,就愈吃运算资源,程序员可利用编程的技巧,来优化运算吃重的程序。但多用户针对同一个程序运行,所带来的运算负载,我们除了请程序员再进一步优化外,另一个更简单的作法就是增加 CPU 核心数量。
(Concurrent Users) 并发用户与CPU的关系
一颗 CPU 核心数加上一个用户运行一支程序,所表现出的性能取决于程序员的撰写技巧。我们假定条件不变的情况下,性能还会受到两个因素影响,一个是提供给程序运算的数据量大小,及呼叫程序的次数(requests)。对性能而言,这些因素只能控制,比如运算数据大的部份就批量处理(batch),呼叫次数多的部份就以排队处理(queue),这些都是针对单一用户,但多用户呢?
以下为用户数与核心数,及AP反应时间的对等关系图:
在多用户数量的运行条件下,上图以群集化来说明这样的关系。
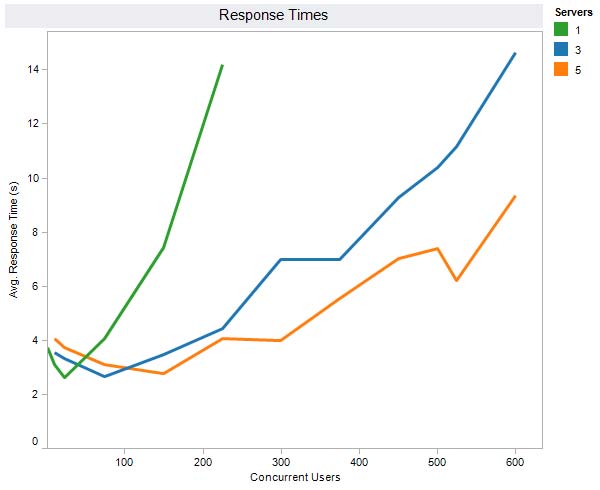
在多用户的执行环境来看,增加服务器数量或是核心数,确实是可以缩短 AP 的反应时间,我们可以看到单核心数的反应时间曲线是非常陡峭的,核心数愈多,愈能维持住 AP 较短的反应时间。
(Jira & CPU) Jira 与 CPU 的关系
jira 算是一个运算型的AP,最小需求的规格,官方建议<=100个项目1000~5000 issues,大概100~200个用户数量,CPU核心数建议是多核心(Multicore CPU)!多核心那到底是几核心呢?只能肯定不是单核心,依原厂的说明,我们知道核心的数量可以改善用户对于 AP 过慢的反应时间,使用的用户数量愈多,并发用户(Concurrent Users)的机率就愈大,并发需求(Concurrent requests)也会跟着增加。
(Confluence & CPU) Confluence 与 CPU 的关系
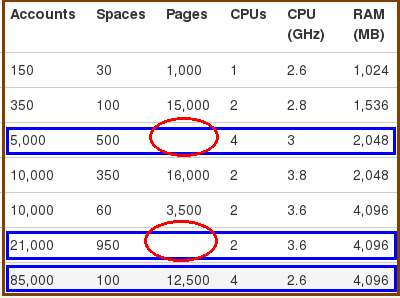
Confluence 其实就是一种可以衡跨(cross) globe 的 KM 知识库管理(Knowledge Management),以各种媒体型态的组合,呈现本身想要表达的意境及概念,一般大都的使用习惯就是插入一些片段的压缩图片,及说明文字和图表,也因此对于 Confluence 的使用上,一般来说运算负担应该不大才对。但为了配合使用者的操作习惯,能够不作任何改变的把他个人的知识,搬到这个平台上分享给大家,confluence 的核心,或是一些插件就为了呈现这些文件格式,不管是 word 的 doc 或是 excel 的 xls 甚至是 for viso 的 vsd 这些其实是会吃运算资源的,如果为了表现更出色的画面让概念更能传达,也不排除有开发者进而研发协同创作的插件。因此如 (表A) 红色圈部份的两笔规格,正是满足有这样需求的知识入口。
有红色圈的内存是针对 java env 进行分配,不是操作系统
(表A)
Confluenc 会因为插件的协同创作功能加强,而让运算吃重。
內存(RAM,Random Access Memory)
我们知道内存的速度大于硬盘的速度,在虚拟环境还未如当下普遍时,它主要是数据存取频繁所放置的地方,又因为 CPU 工艺水平的提升,多核多工的个人电脑所增量的运算能力,让用户可以同一时间运行多个AP,但是价格昂贵的内存,是无法塞进全部的 AP 的。基于这样限制,分页档(page file)/切换档(swap file)內存分页技术的问世,便可以处理这样的问题。
当内存吃紧甚至不足时,背景作业的 AP 便切换至硬盘,把空出来的内存空间提供给当下(前景)要运行的 AP 使用。
下图显示硬盘与内存之间分页技术的运作原理
目前虚拟环境普及,整个虚拟机全部都是运行在物理内存里面,此图是指物理内存里面的虚拟机,虚拟机本身所拥有的内存。
提醒:有些云端供应商会以 kswap 程序来运作分页档,内存在吃紧时,CPU单颗核心有时会满载。
](https://img-blog.csdn.net/20160402135829849)
(More memory if required) 内存与用户数的关系
先定义好用户数再来定义内存的容量吗?这样似乎很难下定义,但如果以需求导向的切入点(比如 Jira 预估要有多少个项目来进行,或是 Confluence 大概需要维护多少个 spaces),来定义内存的需求量,似乎比较是个行得通的方式。
(Jira & memory) Jira 与内存的关系
如以下的简表,我们来看一下小规模的需求,原厂有提及大约的使用人数,但到了大型以上的规模,用户人数就未提列,只提列负载量的相关数据,比如 issues 及 comments 的数量。我们可以发现 Jira 的逻辑规格并不是用户数量 。
| Small | Big | Large |
|---|---|---|
| <=100 Projects | >100 Projects | More than 100 projects |
| 1,000~5,000 issues | 145,000 issues | |
| About 100-200 users | 255,000 comments |
(Confluence & memory) Confluence 与内存的关系
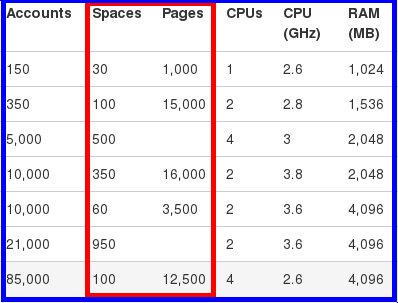
Confluence 本身其实就是一个 wiki 属性的入口(potal),有大量的数据需要去管理及维护,原厂有提供一个列表让我们参考,在特定的用户数量区间,会使用多少的空间数(Spaces)及页数(Pages)才是一般的合理范围,这个参考值应该是大量且不同规模的在线用户,他们所反馈回来的总平均数。
软件的逻辑规格确实是不好定义,但这个表至少让我们在购买云端虚擬机时,有一个参考的依据。
特定的 內存 及 CPU 核心數,一般處理 Spaces/Pages 的數量
(表B)
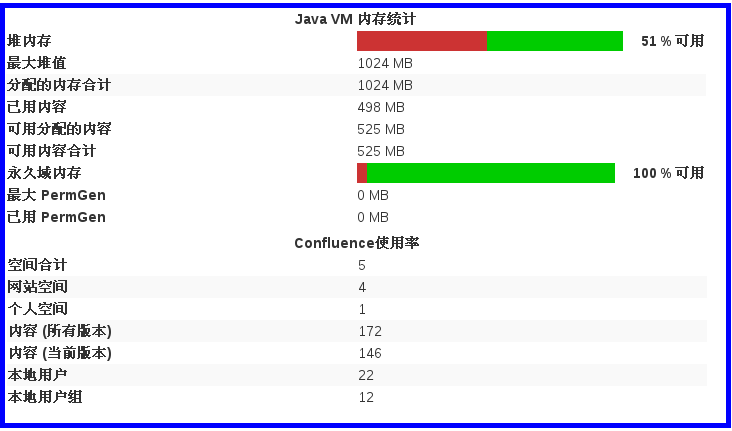
下图为 Confluence 进入一般配置的系统信息截图
可以依实际的使用率来比对数据列表(表B),供应适量的内存空间给这样的团队规模。
硬盘的存储空间 (Data Pool)
Atlassian 系列的 AP 本身所需要的存储空间不大,但有两个部份会产生硬盘空间的增量需求,一个是 Local Home 一个是数据库。针对这两个需求来说,Local Home 的增量需求会大些,怎么说呢?因为不管是插件的安装,或是档案的附加及数据的备份等等,都会直接在 Local Home 上即时反应出增量,也会因为不同产业别类型的用户,或是使用不同的 AP(jira/confluence),增量的大小会有差异,比如说 jira 上面的使用者可能都是讨论原代码,贴来贴去也尽是些截图,或是一些片段的原码,而 Confluence 上传的都是形形色色的档案媒体及各种格式,增量必定较为明显。
Atlassian 系列产品主要空间增量需求的两个位置。
再次提醒! Home Space 的硬盤空間需求,增量是會較明顯的。

网路资源 (Network resource)
不同的 AP 彼此在网络之间互动,因为转输的数据格式或本质不同,所以传输量是会有差异的,就整体而言 Atlassian 系列的产品,在网路上 AP 彼此之间的传输量并不吃重,在这里我们以 Crowd/Confluence/Jira 这三个产品,在网络之间互动的数据性质,来分别说明他们的关系。
Atlassian AP 在 internet 上串接沟通的示意图
Confluence/Jira 会因为用户不同的上传行为,而改变网络的传输量。
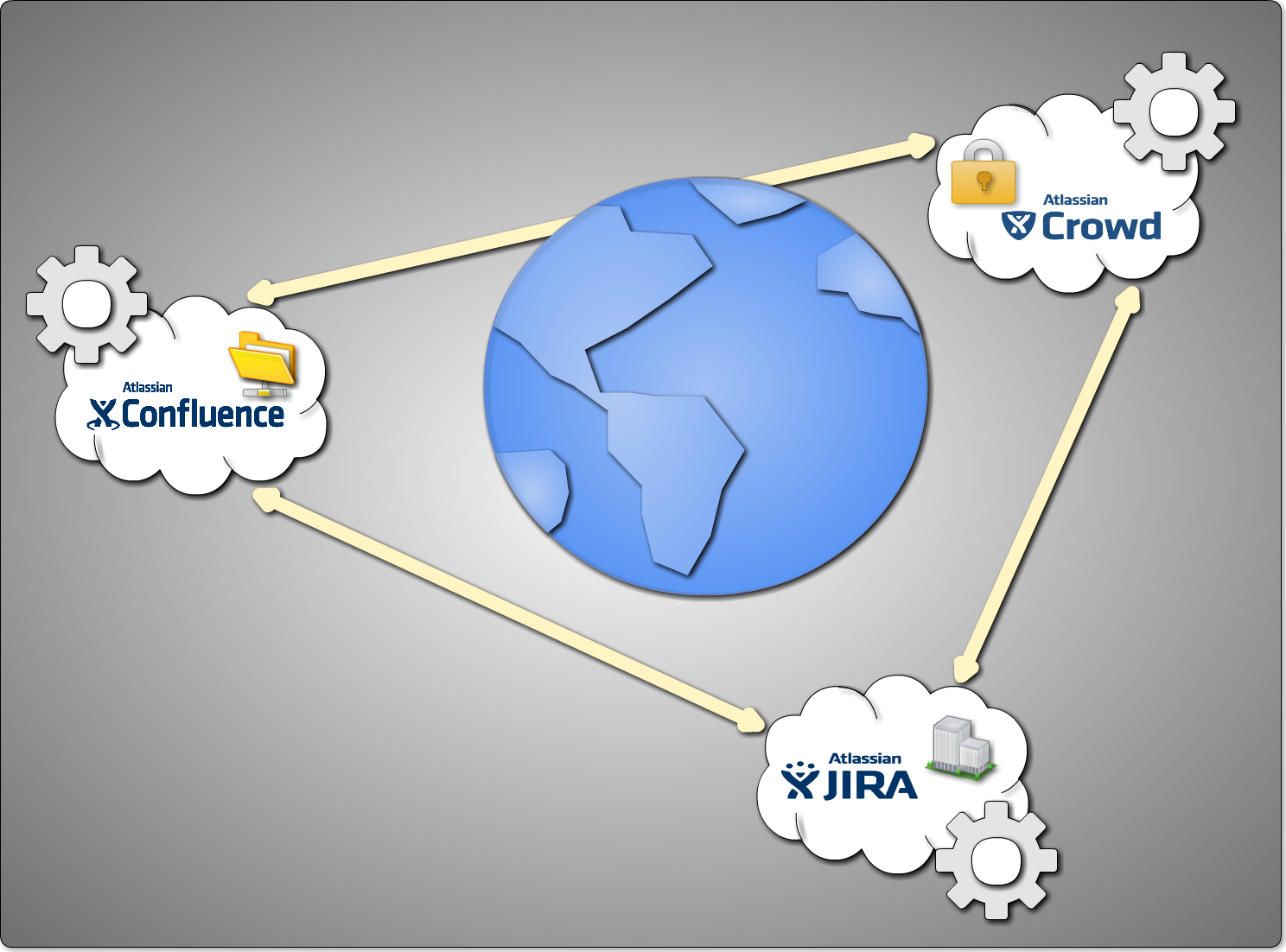
- 我们就先从 Crowd 这个产品开始,Crowd 担任的是整合所有跟用户认证有关的数据库来源(类LDAP数据库,或Jira内部帐号),让 Atlassian 系列的 AP,可以轻易的调度各个领域的成员,不管是临时性的组成一个项目来收集信息也好,或是长期性的组织一个开发团队,都不用改变原有的用户管理机制,在网路上所传送的数据就很单纯的只是用户的相关数据,因此就网络所传输的数据量算是最小的了。
- 紧接着我来看 Jira 的信息传递量,Jira 在互动的过程中,难免会有附加档及一些贴图,所以针对网络的传输量来看,会较 Crowd 来的高一些。
- 最后我们来看看网络传输量较吃重的 Confluence,由于这是个 wiki 型态的知识库,为了方便用户不改变编辑习惯来上传电子文件,达到快速完整的呈现知识内容,在网络的传输量就会受到形形色色的文件格式影响,因而传输量较高 。
资源监控 (Resource Monitor)
当 云端AP实例 开始营运之后,数据持续增长,运算负担也会跟着愈来愈大,资源总有吃紧或不足的时候,云端AP这时候以电子邮件提出预警,告知使用端是应该增量空间的时候了,或是运算开始延迟,是不是需要增加 CPU 的核心数量之类的信息。
供应商透过 AP 邮件告知资源吃紧,供应商主动跟客户预告,资源有增量的需求产生。
由系统提出的预警邮件,事实上只是建立一个诊断的信道,跟企业体制内的商务资讯是没有什么关联的 。
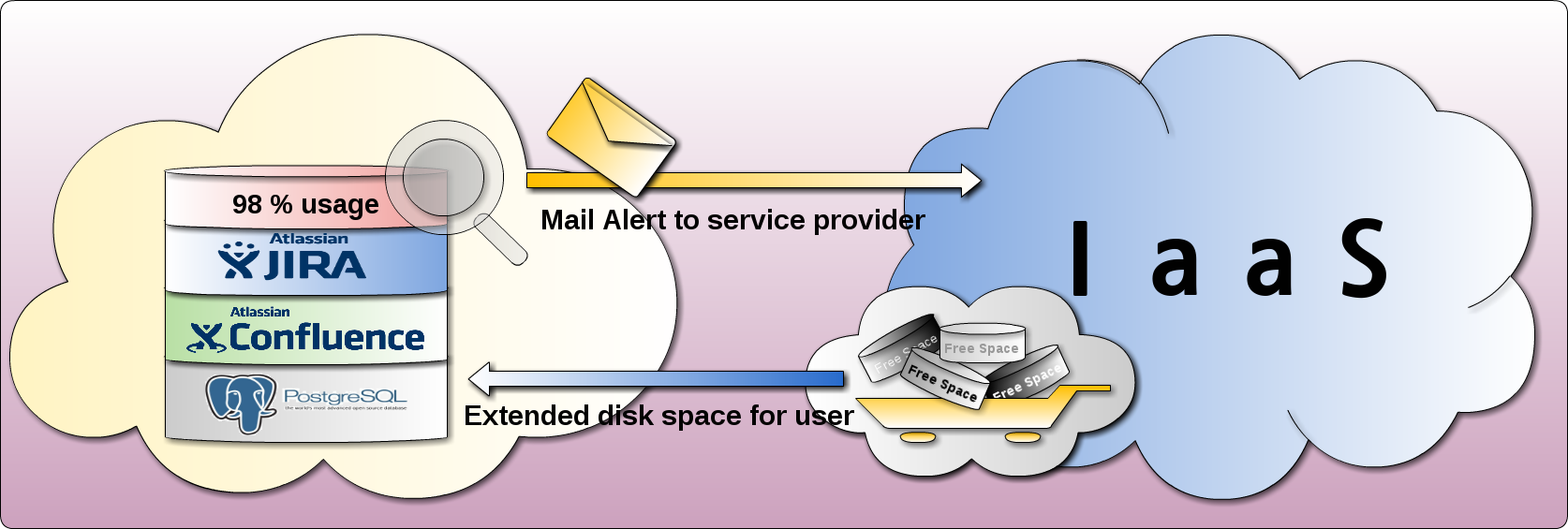
这只是一个认知上的问题,由企业内部的一个 AP 本身邮件收发机制,透过中继代理,发送一个 AP系统相关 的健康状况或是诊断报告(Health Report),有时会被误认为是有信息安全问题,但其实这个信息内容,无非只是跟 AP 本身的健康状况有关而已,要是强加限制甚而不允许这样的维护通道存在,那 AP 本身就会处于自生自灭的风险当中。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









