







第2章 系统的分层结构
![]()
2.1.简述
我们在解决一个复杂的问题的时候,通常使用的一个技巧就是分解,把复杂的问题分解成为若干个简单的问题,逐步地、分别地解决这几个小问题,最后就把整个问题解决掉。在设计一个复杂的软件系统的时候,同样的,为了简化问题,我们也通常使用的一个技术就是分层,每个层完成自身的功能,最后,所有的层整合起来构成一个完整的系统。
分层是计算机技术中的常用方法,一个典型的例子就是TCP/IP技术的OSI七层模型。在应用软件开发中,典型的就是N层应用软件模型。N层的应用软件系统,由于其众多的优点,已经成为典型的软件系统架构,也已经为广大开发人员所熟知。
在一个典型的三层应用软件系统中,应用系统通常被划分成以下三个层次:数据库层、应用服务层和用户界面层。如下图(图2.1)所示:

图2.1
其中,应用服务层集中了系统的业务逻辑的处理,因此,可以说是应用软件系统中的核心部分。软件系统的健壮性、灵活性、可重用性、可升级性和可维护性,在很大程度上取决于应用服务层的设计。因此,如何构建一个良好架构的应用服务层,是应用软件开发者需要着重解决的问题。
为了使应用服务层的设计达到最好的效果,我们通常还需要对应用服务层作进一步的职能分析和层次细分。很多开发者在构建应用服务层的时候,把数据库操纵、业务逻辑处理甚至界面显示夹杂在一起,或者,把业务逻辑处理等同于数据库操纵,等等,这些,都是有缺陷的做法。我们将就在这个方面进行设计时可采用的方案进行一些探讨。
在一个分布式应用系统中,整个系统会部署在不同的物理设备上,如上面所示的三层体系,用户界面和应用服务器可能在不同的设备上,这就涉及到不同机器之间的通信问题,也就是层间的通信和交互问题。我们已经有了很多可以用于分布式远程访问的技术,如CORBA,在Java平台上,我们还有Java RMI、EJB,在Windows平台上,从DCOM到COM+,再到.Net下的Web Service和.Net Remoting等。如何选用合适的远程访问技术,也是我们在系统框架中需要考虑的问题。[6]
为了使讨论更具有针对性,本文也会讨论一些比较流行的系统架构,例如J2EE架构,以及JDO,然后,我们会讨论Websharp在这个方面的一些设计理念。
2.2.设计的原则和评判标准
同软件工程的原则一样,应用服务层的设计,必须遵循的最重要的原则就是高内聚和低耦合[7]。软件分层的本来目的,就是提高软件的可维护性和可重用性,而高内聚和低耦合正是达成这一目标必须遵循的原则。尽量降低系统各个部分之间的耦合度,是应用服务层设计中需要重点考虑的问题。
内聚和耦合,包含了横向和纵向的关系。功能内聚和数据耦合,是我们需要达成的目标。横向的内聚和耦合,通常体现在系统的各个模块、类之间的关系,而纵向的耦合,体现在系统的各个层次之间的关系。
系统的框架,通常包含了一系列规范、约定和支撑类库、服务。
对于如何判断一个软件的系统框架的优劣,笔者认为,可以从以下几个方面来评判:
◆ 系统的内聚和耦合度
这是保证一个系统的架构是否符合软件工程原则的首要标准。
◆ 层次的清晰和简洁性
系统每个部分完成功能和目标必须是明确的,同样的功能,应该只在一个地方实现。如果某个功能可以在系统不同的地方实现,那么,将会给后来的开发和维护带来问题。
系统应该简单明了,过于复杂的系统架构,会带来不必要的成本和维护难度。在尽可能的情况下,一个部分应该完成一个单独并且完整的功能。
◆ 易于实现性
如果系统架构的实现非常困难,甚至超出团队现有的技术能力,那么,团队不得不花很多的精力用于架构的开发,这对于整个项目来说,可能会得不偿失。简单就是美。
◆ 可升级和可扩充性
一个系统框架,受设计时技术条件的限制,或者设计者本人对系统认识的局限,可能不会考虑到今后所有的变化。但是,系统必须为将来可能的变化做好准备,能够在今后,在目前已有的基础上进行演进,但不会影响原有的应用。接口技术,是在这个方面普遍应用的技巧。
◆ 是否有利于团队合作开发
一个好的系统架构,不仅仅只是从技术的角度来看,而且,它还应该适用于团队开发模型,可以方便一个开发团队中各个不同角色的互相协作。例如,将Web页面和业务逻辑组件分开,可是使页面设计人员和程序员的工作分开来同步进行而不会互相影响。
◆ 性能
性能对于软件系统来说是很重要的,但是,有的时候,为了能让系统得到更大的灵活性,可能不得不在性能和其他方面取得平衡。另外一个方面,由于硬件技术的飞速发展和价格的下降,性能的问题往往可以通过使用使用更好的硬件来获得提升。
2.3.应用服务层的内容
应用服务层,通常也被称为业务逻辑层,因为这一层,是应用软件系统业务逻辑处理集中的部分。然而,我将这一层称为应用服务层,而不称业务逻辑层,因为,这一层需要处理的不仅仅是业务逻辑,还包含了其他方面的内容。
从完整的角度来说,应用服务层需要处理以下内容:
◆ 数据的表示方式
数据,是软件处理的对象。从某种程度上来说,"软件,就是数据结构加算法"的说法,是有一定意义的。在面向对象的系统中,数据是用类来表示的,代表了现实世界实体对象在软件系统中的抽象。考虑所谓的MVC模式,这个部分的类属于M--实体类的范畴。由于应用软件通常会使用数据库,数据库中的数据,可以看成是对象的持久化保存。由于数据库一般是关系型的,因此,这个部分,还需要考虑类(对象)同关系型数据的映射,即通常所说的O-R MAP问题。
◆ 数据的存取方式
如同上述所说,软件系统处理的实体对象数据需要持久化保存数据库中,因此,我们必须处理系统同数据库的交互,以及数据的存取和转换方式的问题。
◆ 业务逻辑的组织方式
在面向对象的系统中,业务逻辑表现为对象之间的交互。有了上述的实体对象,以及对象的保存策略,就可以将这些对象组合起来,编写我们的业务逻辑处理程序。在业务逻辑的处理中,必须保证处理的正确性和完整性,这将会涉及到事务处理。通常,我们也会把业务逻辑封装成组件的形式,以得到最大的可重用性。
◆ 业务服务的提供方式
在我们完成系统的功能后,如何向客户提供服务,是我们需要考虑的问题。这里的客户,不仅仅是指软件的使用者,也包括调用的界面、其他程序等。例如,在一个基于Web的ASP.Net或JSP系统中,业务逻辑功能的客户便是这些ASP.Net页面或JSP页面。业务逻辑组件应该通过什么方式,直接的,或间接的,向这些客户提供服务,是这一层需要完成的任务。
◆ 层的部署和层间交互
对于一个多层的应用软件系统来说,尤其是大型的应用软件系统,通常需要把不同的部分部署在不同的逻辑或物理设备上。特别是一些基于Web的应用软件系统,其部署工作将涉及到Web服务器、组件服务器、数据库服务器等不同的服务设备。在进行应用软件架构的设计的时候,必须考虑各种不同的部署方案。 当系统需要进行分布式访问的时候,如何统一和简化分布式系统的开发,便成了系统框架需要考虑的内容。
综上所述,一个完整的基于Web的应用软件系统,其架构可以用图2.2来表示(Websharp的应用软件系统架构):

图2.2
对于以上各个方面来说,每个问题都可以有很多种策略和方案,但是,在一个系统中,应该尽可能的统一这些策略和方案。也就是说,在一个系统,或者一个项目中,应该统一每个解决每个问题所采用的方法。软件的开发方法是灵活的,可以用不同的方法解决相同的问题,这会诱使开发人员采用他们认为能够表现自己的方法,但是,从整个系统来看,这将会是灾难性的。我们应该尽可能统一,就是,采用统一的数据表示方式、统一的数据存取方式、统一的业务逻辑处理方式等。
下面,将就这些部分的设计策略和可用方案进行一些比较详细的论述。
2.4.数据实体的表示
应用软件系统,从本质上来说,是计算机对现实世界的模拟。现实世界中的实体对象,在软件系统中,表现为需要处理的数据。在面向对象的系统中,这是通过“类"和”对象"来表示的。
参考著名的“MVC”模式[8],类可以分成实体类(M)、控制类(C)、和边界类(V),分别代表了实体对象、控制和界面显示。系统中需要处理的数据,在面向对象的系统中,属于实体类部分。
在考虑数据实体层的设计策略的时候,需要把握以下要点:
◆ 一致的数据表示方式。在一个系统中,数据的表示方式必须尽可能统一,同时,在处理单个数据和多个数据的时候,处理方式尽可能一致。
◆ 因为数据通常是需要存储到数据库中,因此,良好的映射方法是必需的。
◆ 处理好对象的粒度,即所谓的粗粒度对象、细粒度对象。
一般例子
考虑一个现实的例子,一个仓库中的产品(Product),在系统中可以使用如下定义:
|
public class Product { public string Name; //名称 public decimal Price;//价格 public int Count;//数量 } 可以按照如下方法使用Product类: Product p=new Product(); //……处理Product |
这是一个包含了三个属性的Product类的定义。为了便于说明,在这里,我们尽量将问题简化了。
又例如,一张入库单可以使用如下定义:
| public class Form { public string ID; //入库单编号 public DateTime AddTime; //入库时间 public FormDetail[] FormDetails; //入库单明细 } public class FormDetail { public Product InProduct; //入库产品 public int Count; //入库数量 } |
对于处理单个对象,通常采用上述的方法,但是,当我们需要处理相同类的一组对象,也就是处理一个对象集合的时候,就会有一些小小的麻烦。
如前所述,我们希望在处理单个对象和对象集合的时候,处理的方式尽量统一,这对于软件开发的意义是很大的。常用的处理对象集合的方法有:
◆数组表示的方法
例如,上面的例子中当一张入库单包含多条入库单明细的时候采用的方法。为了灵活性,也可以使用容器来,如Java中的Vector或C#的ArrayList(C#)。只是,在处理对象的时候,需要一个类型转换的操作。这个问题,在支持泛型的语言中不会存在,如使用C++的标准库的容器类。
◆ ObjectCollection方法。
这个方法同上面的方法类似,不同之处在于,为每个实体类设计一个Collection类。例如,可以为FormDetail设计一个FormDetailsCollection类(C#):
| public class FormDetailsCollection: ArrayList { public void Add(FormDetail detail) { base.Add(detail); } public new FormDetail this[int nIndex] { get { return (FormDetail)base[nIndex]; } } } |
这么做的好处在于,在操作集合中的对象时,不必进行类型转换的操作。
◆数据集的表示方法。
采用这种方法,通常是直接把从数据库查询中获取的数据集(Recordset)作为数据处理对象。这种方法在ASP应用程序中是非常常见的做法。这种做法简单,初学者很容易掌握,但是他不是一种面向对象的方法,弊病也很多。
EJB的方法
在J2EE体系中,对实体对象的处理的典型方法是Entity Bean。J2EE中使用Entity Bean来表示数据,以及封装数据的持久化储存(同数据库的交互)。由于Entity Bean比较消耗资源,而且采用的是远程调用的方式来访问,因此,在需要传递大量数据,或者在不同的层次之间传递数据的时候,往往还会采用一些诸如"值对象"(Value Object)的设计模式来提升性能。关于J2EE中的设计模式的更多内容,可以参考《J2EE核心模式》一书。 [9]
JDO的方法
相对于J2EE这个昂贵的方法来说,JDO提供了一个相对"轻量级"的方案。在JDO中,你可以采用一般的做法,编写实体类,然后,通过一些强化器对这些类进行强化,以使其符合JDO的规范,最后,你可以通过PersistenceManager来实现对象的持久化储存。 [10]
无论是EJB还是JDO,在同数据库进行映射的时候,都选用了XML配置文件的方式。这是一种灵活的方式。由于XML强大的表达能力,我们可以很好的用它来描述代码中的实体类和数据库之间的映射关系,并且,不用在代码中进行硬编码,这样,在情况发生变化的时候,有可能只需要修改配置文件,而不用去修改程序的源代码。关于EJB和JDO的配置文件的更多的信息,各位可以参考相关的文档,这里不再赘述了。
然而,使用XML配置文件的方式并不是唯一的方法,在微软提供的一些案例中,如Duwamish示例[11],就没有采用这种方式。至于开发人员在开发过程中具体采用哪种方式,是需要根据具体情况进行权衡和取舍的。
Websharp的方法
Websharp在数据的表现上,充分利用了.Net Framework类库中DataSet和特性(Attribute)的功能。我们设计了一个EntityData类,这个类继承了DataSet,并增加了一些属性和方法。
在Websharp中,当表示一个实体类的时候,需要定义一个抽象类,这个抽象类继承PersistenceCapable。例如,一个Schdule类可以表示如下:
| [TableMap("Schdule","GUID")] [WebsharpEntityInclude(typeof(Schdule))] public abstract class Schdule : PersistenceCapable { [ColumnMap("GUID",DbType.String,"")] public abstract string GUID{get;set;}
[ColumnMap("UserID",DbType.String,"")] public abstract string UserID{get;set;}
[ColumnMap("StartTime",DbType.DateTime)] public abstract DateTime StartTime{get;set;}
[ColumnMap("EndTime",DbType.DateTime)] public abstract DateTime EndTime{get;set;}
[ColumnMap("Title",DbType.String,"")] public abstract string Title{get;set;}
[ColumnMap("Description",DbType.String,"")] public abstract string Description{get;set;}
[ColumnMap("RemidTime",DbType.DateTime)] public abstract DateTime RemidTime{get;set;}
[ColumnMap("AddTime",DbType.DateTime)] public abstract DateTime AddTime{get;set;}
[ColumnMap("Status",DbType.Int16,0)] public abstract short Status{get;set;} } |
类的TableMap 特性指明了同Schdule实体类相映射的数据库表,以及关键字,ColumnMap特性指明了同某个属性相映射的数据库表字段,以及数据类型和默认值。
在实际的应用中,定义了这样一个Schdule抽象类后,要获取一个实体对象,因为Schdule类是抽象的,所以你不可以直接使用new操作来初始化Schdule对象,应当通过如下方式取得:
| Schdule schdule = EntityManager.CreateObject(typeof(Schdule)) as Schdule; |
EntityManager会即时编译出一个Schdule的实现类,并且返回一个对象。
在这种方式下,实体类同数据库表的映射是通过Attribute来实现的。
可以使用另外一种方法来表示一个实体类。在这种方式下,需要编写一个XML映射文件,然后,可以使用如下方式取得一个实体对象:
| EntityData schdule =EntityManager.GetEntityData("Schdule"); |
然后,可以通过如下方式来访问这个对象的属性:
| string Title = schdule["Title"] |
可以看到,这种方式同传统的方式有点不同。在这种方式下,数据的表现形式只有一个,那就是EntityData。其好处是明显的,不用为每个实体都单独编写一个类,能够大大减少代码的编写量。其缺点也很明显,那就是不能利用编译器类型检测的功能,如果在调用对象的属性的时候,写错了属性的名称,就可能出错,这需要更加仔细的测试工作。但是,这个问题可以通过工具生成代码来解决。
2.5.数据的存取方式
数据存取的目的,是持久化保存对象,以备后来的使用,如查询、修改、统计分析等。存取的对象,可以是数据库、普通文件、XML甚至其他任何方式,只要保证数据能够长久保存,并且,不会受断电、系统重起等因素的影响。在这个部分,最理想的状况,自然是能够支持除了数据库以外的各种类型的存取方式,或者,至少留有接口,能够比较方便的扩充。
因为数据库是最常用,也是最有效的数据存储方法,因此,支持数据库存储是最首先必须支持的。在不同的平台下,有不同的数据库访问的手段。例如,在Java平台下,有JDBC,在Windows平台下,可以使用ADO、ADO.Net等。但是,这些手段还比较接近底层,在实际操纵数据库的时候,需要编写大量的代码,并且,我们还需要通过手工的方式来完成将程序中的面向对象的数据存储到关系型数据库的工作。这么做,自然编程的效率不高,并且非常容易出错。但是,不可否认,这也是一种可以选用的方式。
从另外一个方面来看,由于我们前面已经解决了数据的映射问题,因此,在数据的存取方面是非常有规律的,我们完全可以让这个工作通过框架来执行。这样,我们一方面可以简化很多同数据库交互方面的代码编写工作量,能够减少出现Bug的几率,另一方面,由于框架封装了不同数据库之间的差异,使得我们在编写程序的时候,不用考虑不同数据库之间的差异,而将这个工作交给框架去做,实现软件的后台数据库无关性。
在这个部分,以下两个部分的类会显得特别重要:
◆对象--关系映射的分析类,能够通过既定的方案完成对象--关系的映射,确定数据存取方案
◆数据库操纵类:根据映射关系,将数据准确的存储到数据库中,并且封装不同数据库之间的差异。
这个部分的操作过程,可以用图(图2.3)大概的表示如下:
图2.3 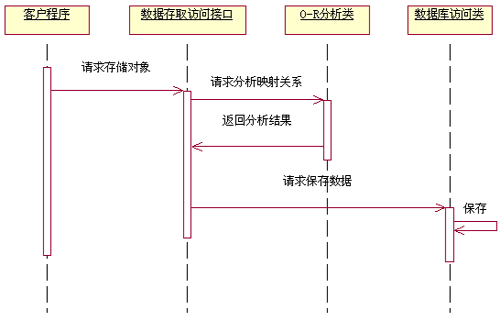
在J2EE中,这个部分比较典型的就是EntityBean中的CMP。由于在BMP中,同数据库的交互部分需要通过手工编写代码的方式来实现,因此,很难享受到容器带来的便利,只是由于EJB2.0以前的标准,CMP的功能,包括映射能力、实体关系模式等方面的功能比较弱,所以,在很多时候,我们不得不使用BMP。现在,EJB2.0,在这个方面的功能已经非常强大了,我们完全可以享受容器带来的便利,而将大部分精力放在实现更加复杂的业务逻辑方面了。
在JDO中,您同样可以通过PersistenceManager来实现同样的目标,例如,您想把一个Customer对象保存到数据库中,可以采用类似于下面的代码:
| Schdule schdule=new Schdule(……); PersistenceManager PM=PMFactory.initialize(……); Pm.persist(schdule); |
代码同样非常简明和直观,没有一大堆数据库操纵的代码,也不容易发生差错。
Websharp的方案
同JDO类似,Websharp定义了PersistenceManager接口,这个接口的定义在后面的章节中会给出,这里,我们先看看其使用方式。
当我们有了某个实体对象后,需要保存到数据库中的时候,我们可以使用下面的代码来实现:
| public bool AddSchdule(Schdule schdule) { PersistenceManager pm = PersistenceManagerFactory.Instance().CreatePersistenceManager(); try { pm.PersistNewObject(schdule); return true; } catch { return false; } finally { pm.Close(); } } |
在这里,我们不需要关心具体的数据库版本,框架会封装不同数据库之间的差异,保证数据可以正确的存储到不同的数据库中。
在这个部分,另外需要注意的是,为了保证数据存储的完整性,应当考虑事务处理的功能。J2EE、JDO和Websharp都支持在数据存储的时候使用事务处理














 4158
4158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









