







问题:
用好压打开同事给发的压缩包后,打开查看和解压的文件夹里面文件名都是乱码。截图如下:

原因:
1.编码方式不一样。像linux下文件名是用UTF-8编码,win32下文件名是用GBK编码。
2.使用不同压缩软件压缩的,比如你打开的这个压缩包是winrar压缩的,用好压打开就会文件名乱码
解决:

用好压软件打开压缩包,在“选项——Language——设置代码页——更多代码页与设置”选择UTF-8,在后面两个复选框上打勾;这时有时可能在压缩包内查看文件名仍然是乱码,但是解压后文件名已正常了(可以关掉好压,在重新用好压打开)。操作图解:

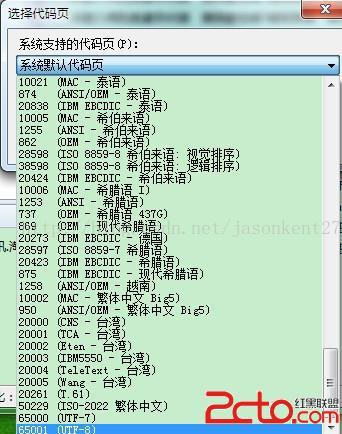
结果:

转自:http://www.2cto.com/os/201401/271901.html














 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









