






 本文介绍了Hadoop使用过程中常见的三个错误及其解决方案:1.找不到winutils.exe文件;2.buildArtifacts时报内存溢出错误;3.run时报内存溢出错误。针对这些问题提供了具体的步骤和设置方法。
本文介绍了Hadoop使用过程中常见的三个错误及其解决方案:1.找不到winutils.exe文件;2.buildArtifacts时报内存溢出错误;3.run时报内存溢出错误。针对这些问题提供了具体的步骤和设置方法。
错误一
null>bin>winutils.exe not found
这种情况下只是需要winutils.exe文件即可,不需要下载所有hadoop
winutils.exe下载链接
然后放在hadoop/bin文件夹下,环境变量加上HADOOP_HOME
错误二
build Artifacts时报错java.lang.outofmemoryerror
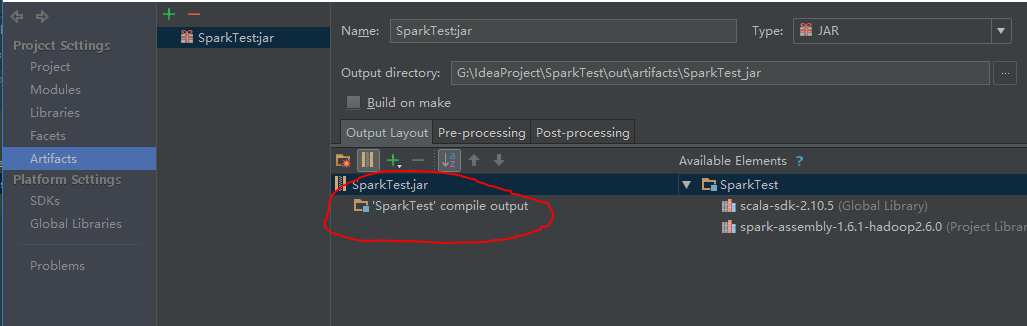
配置时output,因为运行环境中已经有相关包,所以其他包删除,只保留’compile output’那一项,这时再build就不会内存溢出
错误三
run时报错java.lang.outofmemoryerror
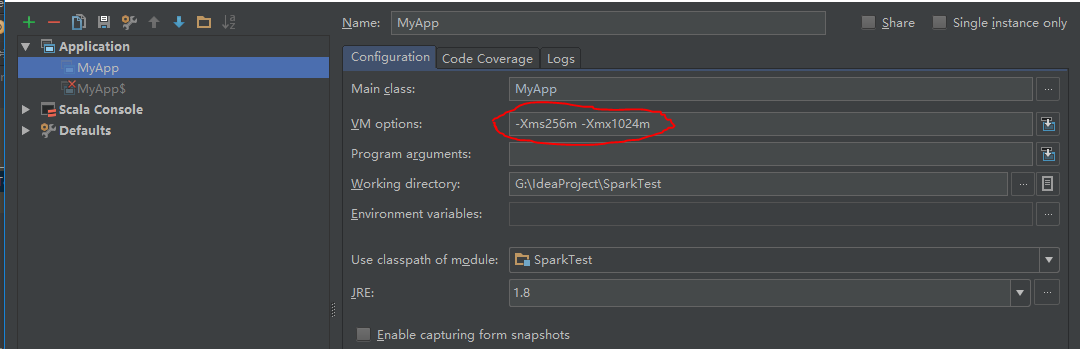
在run configuration中的VM options中-Xms256m -Xmx1024m
这时再build就不会内存溢出

















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









