







在浏览网页过程中,我们会遇到一些让人心动的图片,这时我们需要将它保存在本地。一般我们用BeautifulSoup可以解析静态网页,但很多时候我们遇到的都是动态加载的图片,无法再利用urllib模块操作了。
本次分享将讲述如何利用PhantomJS来下载动态图片。我们的示例网址为:http://comic.kukudm.com/comiclist/43/395/4.htm ,该网页只有一张动漫,读者不难发现,该图片是动态加载的。
我们解决问题的思路为:利用PhantomJS加载网页,然后利用page_source获取加载后网页的源代码,里面就有我们需要的图片的下载网址!接着运行BeautifulSoup解析得到图片网址,再用urllib.request.urlretrieve()函数下载图片即可。
以下为示例代码:
# -*- coding: utf-8 -*-
import bs4
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
#利用PhantomJS加载网页
browser = webdriver.PhantomJS()
browser.set_page_load_timeout(30) # 最大等待时间为30s
#当加载时间超过30秒后,自动停止加载该页面
try:
browser.get('http://comic.kukudm.com/comiclist/43/395/4.htm')
except TimeoutException:
browser.execute_script('window.stop()')
source = browser.page_source #获取网页源代码
browser.quit()
#解析网页,获取下载图片的网址
soup = BeautifulSoup(source,'lxml')
image = soup.find('img')
url =image.get('src')
#下载图片
urllib.request.urlretrieve(url,"G:\\爬虫图片\浪客剑心.jpg")
print("Download picture successfully!") 查看文件夹,我们发现图片已经下载完毕了。
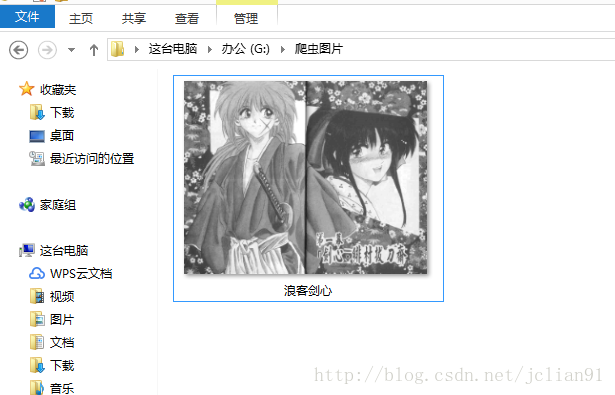
这样我们就能下载我们喜欢的动态图片啦~~
本次分享到此结束,如有不足之处,还请批评指正,欢迎交流~~
期待下一次分享^o^
注意:本人现已开通两个微信公众号: 因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~















 2068
2068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









