







Web of Science爬虫实战(Post方法)
一.概述
本次爬虫主要通过论文的标题来检索出该论文,从而爬取该论文的被引量,近180天下载量以及全部下载量。这里使用的是Web of Scienece 核心合集,并且使用python的requests 库中post方法进行爬取,此外为了加快爬取速度2.0版本采取了多线程的技术
二.网站及爬取策略分析
这个链接进入相应页面然后按下F12点击右侧的network页面,如下图所示:
图1:检索页面
然后在右侧红框内选择web of science 核心合集 以及标题按钮,然后输入标题我这里以Blackcarbon in soils from different land use areas of Shanghai, China: Level,sources and relationship with polycyclic aromatic hydrocarbons为例,下图中右侧红框内内容即为需要用post方法提交的数据。
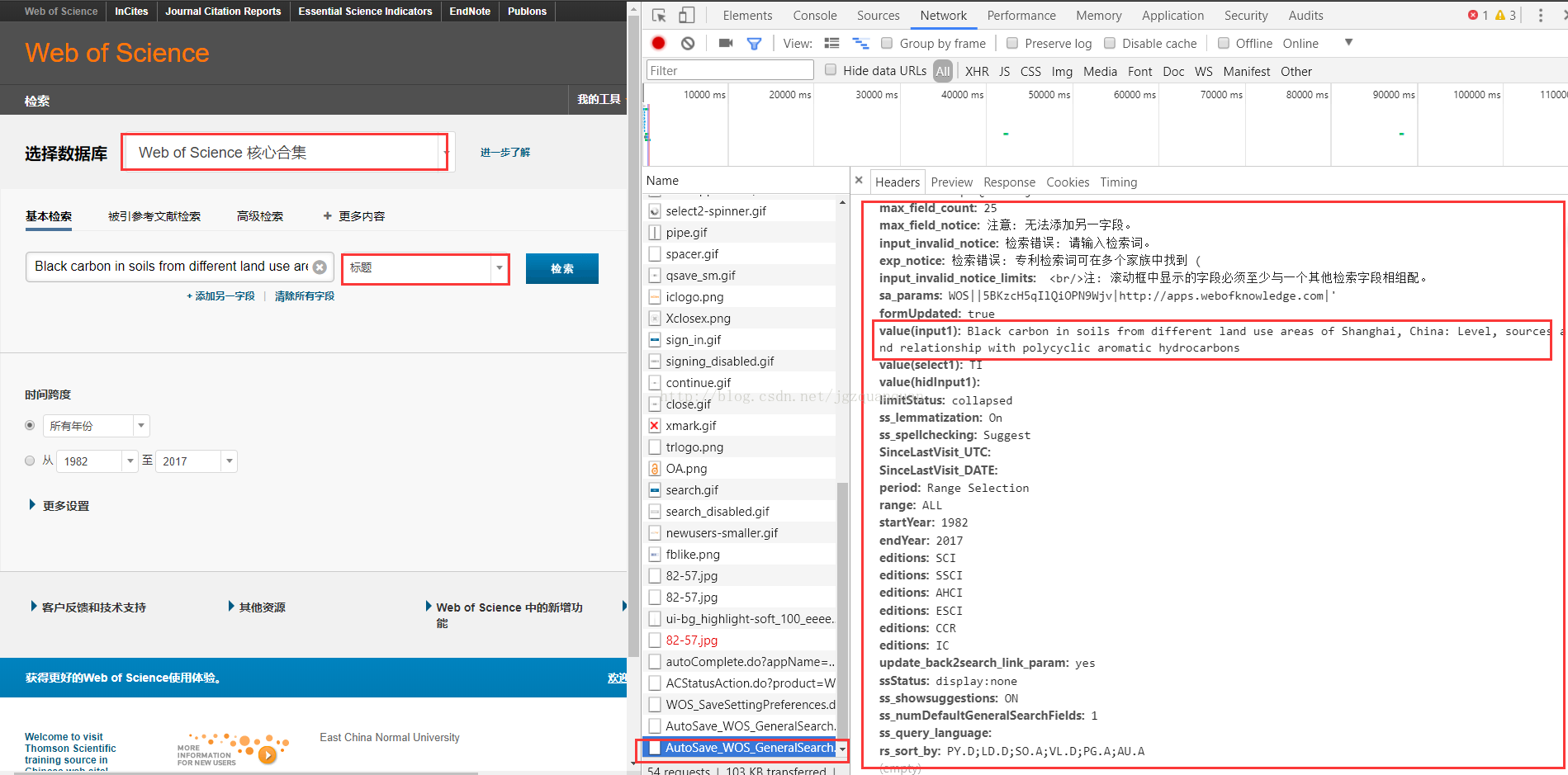
图2.post提交数据来源
点击检索即可进入我们需要爬取的页面如下

图3.爬取页面
看到右侧用红框标出的页面鼠标移到上面右键检查即课打开该开发者页面,具体分析里面的html
三.爬虫代码
下面即是完整的python代码,也可以访问我的github https://github.com/jgzquanquan/Spyder_wos
title_wos_1.0版本
import re
# from threading import Thread
from multiprocessing import Process
from multiprocessing import Manager
import requests
import time
import xlrd
from bs4 import BeautifulSoup
from lxml import etree
class SpiderMain(object):
def __init__(self, sid, kanming):
self.hearders = {
'Origin': 'https://apps.webofknowledge.com',
'Referer': 'https://apps.webofknowledge.com/UA_GeneralSearch_input.do?product=UA&search_mode=GeneralSearch&SID=R1ZsJrXOFAcTqsL6uqh&preferencesSaved=',
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36",
'Content-Type': 'application/x-www-form-urlencoded'
}
self.form_data = {
'fieldCount': 1,
'action': 'search',
'product': 'WOS',
'search_mode': 'GeneralSearch',
'SID': sid,
'max_field_count': 25,
'formUpdated': 'true',
'value(input1)': kanming,
'value(select1)': 'TI',
'value(hidInput1)': '',
'limitStatus': 'collapsed',
'ss_lemmatization': 'On',
'ss_spellchecking': 'Suggest',
'SinceLastVisit_UTC': '',
'SinceLastVisit_DATE': '',
'period': 'Range Selection',
'range': 'ALL',
'startYear': '1982',
'endYear': '2017',
'update_back2search_link_param': 'yes',
'ssStatus': 'display:none',
'ss_showsuggestions': 'ON',
'ss_query_language': 'auto',
'ss_numDefaultGeneralSearchFields': 1,
'rs_sort_by': 'PY.D;LD.D;SO.A;VL.D;PG.A;AU.A'
}
self.form_data2 = {
'product': 'WOS',
'prev_search_mode': 'CombineSearches',
'search_mode': 'CombineSearches',
'SID': sid,
'action': 'remove',
'goToPageLoc': 'SearchHistoryTableBanner',
'currUrl': 'https://apps.webofknowledge.com/WOS_CombineSearches_input.do?SID=' + sid + '&product=WOS&search_mode=CombineSearches',
'x': 48,
'y': 9,
'dSet': 1
}
def craw(self, root_url,i):
try:
s = requests.Session()
r = s.post(root_url, data=self.form_data, headers=self.hearders)
r.encoding = r.apparent_encoding
tree = etree.HTML(r.text)
cited = tree.xpath("//div[@class='search-results-data-cite']/a/text()")
download = tree.xpath(".//div[@class='alum_text']/span/text()")
flag = 0
print(i,cited, download,r.url)
flag=0
return cited, download, flag
except Exception as e:
if i == 0:
print(e)
print(i)
flag = 1
return cited, download, flag
def delete_history(self):
murl = 'https://apps.webofknowledge.com/WOS_CombineSearches.do'
s = requests.Session()
s.post(murl, data=self.form_data2, headers=self.hearders)
root_url = 'https://apps.webofknowledge.com/WOS_GeneralSearch.do'
if __name__ == "__main__":
# sid='6AYLQ8ZFGGVXDTaCTV9'
root = 'http://www.webofknowledge.com/'
s = requests.get(root)
sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
data = xlrd.open_workbook('2015年研究生发表论文.xlsx')
table = data.sheets()[2]#具体是取哪个表格
nrows = table.nrows
ncols = table.ncols
ctype = 1
xf = 0
for i in range(2, nrows):
csv = open('2015_3.csv', 'a')
fail = open('fail.txt', 'a')
if i % 100 == 0:
# 每一百次更换sid
s = requests.get(root)
sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
kanming = table.cell(i, 5).value#取第i行第6列的数据
obj_spider = SpiderMain(sid, kanming)
cited,download,flag = obj_spider.craw(root_url,i)
if flag==1:
fail.write(str(i)+'\n')
else:
if len(cited)==0:
cited.append(0)
print(cited)
if len(download)==0:
download.append(0)
download.append(0)
print(download)
csv.write(str(i) + ',' + str(cited[0]) + ',' + str(download[0]) + ',' + str(download[1]) +'\n')
csv.close()title_wos_2.0
import re
# from threading import Thread
from multiprocessing import Process
from multiprocessing import Manager
import requests
import time
import xlrd
from bs4 import BeautifulSoup
from lxml import etree
class SpiderMain(object):
def __init__(self, sid, kanming):
self.hearders = {
'Origin': 'https://apps.webofknowledge.com',
'Referer': 'https://apps.webofknowledge.com/UA_GeneralSearch_input.do?product=UA&search_mode=GeneralSearch&SID=R1ZsJrXOFAcTqsL6uqh&preferencesSaved=',
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36",
'Content-Type': 'application/x-www-form-urlencoded'
}
self.form_data = {
'fieldCount': 1,
'action': 'search',
'product': 'WOS',
'search_mode': 'GeneralSearch',
'SID': sid,
'max_field_count': 25,
'formUpdated': 'true',
'value(input1)': kanming,
'value(select1)': 'TI',
'value(hidInput1)': '',
'limitStatus': 'collapsed',
'ss_lemmatization': 'On',
'ss_spellchecking': 'Suggest',
'SinceLastVisit_UTC': '',
'SinceLastVisit_DATE': '',
'period': 'Range Selection',
'range': 'ALL',
'startYear': '1982',
'endYear': '2017',
'update_back2search_link_param': 'yes',
'ssStatus': 'display:none',
'ss_showsuggestions': 'ON',
'ss_query_language': 'auto',
'ss_numDefaultGeneralSearchFields': 1,
'rs_sort_by': 'PY.D;LD.D;SO.A;VL.D;PG.A;AU.A'
}
self.form_data2 = {
'product': 'WOS',
'prev_search_mode': 'CombineSearches',
'search_mode': 'CombineSearches',
'SID': sid,
'action': 'remove',
'goToPageLoc': 'SearchHistoryTableBanner',
'currUrl': 'https://apps.webofknowledge.com/WOS_CombineSearches_input.do?SID=' + sid + '&product=WOS&search_mode=CombineSearches',
'x': 48,
'y': 9,
'dSet': 1
}
def craw(self, root_url,i):
try:
s = requests.Session()
r = s.post(root_url, data=self.form_data, headers=self.hearders)
r.encoding = r.apparent_encoding
tree = etree.HTML(r.text)
cited = tree.xpath("//div[@class='search-results-data-cite']/a/text()")
download = tree.xpath(".//div[@class='alum_text']/span/text()")
flag = 0
print(cited, download,r.url)
flag=0
return cited, download, flag
except Exception as e:
# 出现错误,再次try,以提高结果成功率
if i == 0:
print(e)
print(i)
flag = 1
return cited, download, flag
def delete_history(self):
murl = 'https://apps.webofknowledge.com/WOS_CombineSearches.do'
s = requests.Session()
s.post(murl, data=self.form_data2, headers=self.hearders)
class MyThread(Process):
def __init__(self, sid, kanming, i, dic):
Process.__init__(self)
self.row = i
self.sid = sid
self.kanming = kanming
self.dic=dic
def run(self):
self.cited, self.download, self.fl = SpiderMain(self.sid, self.kanming).craw(root_url, self.row)
self.dic[str(self.row)]=Result(self.download, self.cited, self.fl, self.kanming, self.row)
class Result():
def __init__(self, download, cited, fl, kanming, row):
super().__init__()
self.row = row
self.kanming = kanming
self.fl = fl
self.cited = cited
self.download = download
def runn(sid, kanming, i, d):
ar, ref, fl = SpiderMain(sid, kanming).craw(root_url, row)
d[str(i)]=Result(ar, ref, fl, kanming, i)
print(d)
root_url = 'https://apps.webofknowledge.com/WOS_GeneralSearch.do'
if __name__ == "__main__":
# sid='6AYLQ8ZFGGVXDTaCTV9'
root = 'http://www.webofknowledge.com/'
s = requests.get(root)
sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
data = xlrd.open_workbook('2015年研究生发表论文.xlsx')
table = data.sheets()[0]
nrows = table.nrows
ncols = table.ncols
ctype = 1
xf = 0
threads = []
threadnum = 5
d = Manager().dict()
csv = open('2015_3.csv', 'a')
fail = open('fail2015.txt', 'a')
for i in range(2, nrows):
if i % 100 == 0:
# 每一百次更换sid
s = requests.get(root)
sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
kanming = table.cell(i, 5).value
t = MyThread(sid, kanming, i, d)
threads.append(t)
if i % threadnum == 0 or i == nrows - 1:
for t in threads:
try:
t.daemon = True
t.start()
except requests.exceptions.ReadTimeout:
continue
for t in threads:
t.join()
for t in threads:
rst = d[str(t.row)]
cited,download,flag = rst.cited,rst.download,rst.fl
if flag==1:
fail.write(str(i)+'\n')
else:
if len(cited)==0:
cited.append(0)
print(cited)
if len(download)==0:
download.append(0)
download.append(0)
print(download)
csv.write(str(i) + "," + str(cited[0]) + ',' + str(download[0]) + ',' + str(download[1]) +'\n')
threads = []
csv.close()
fail.close()














 5114
5114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









