







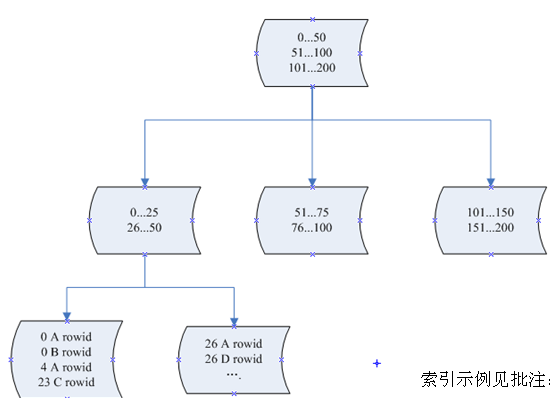
单一索引是指索引列为一列的情况,即新建索引的语句只实施在一列上。
用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引)。复合索引的创建方法与创建单一索引的方法完全一样。但复合索引在数据库操作期间所需的开销更小,可以代替多个单一索引。当表的行数远远大于索引键的数目时,使用这种方式可以明显加快表的查询速度。
同时有两个概念叫做窄索引和宽索引,窄索引是指索引列为1-2列的索引,如果不特殊说明的话一般是指单一索引。宽索引也就是索引列超过2列的索引。
设计索引的一个重要原则就是能用窄索引不用宽索引,因为窄索引往往比组合索引更有效。拥有更多的窄索引,将给优化程序提供更多的选择余地,这通常有助于提高性能。
在这里实验复合索引的效果
创建数据库,自动插入数据
create table test
(a int ,
b int,
c int);
--创建序列
create sequence test_seq
maxvalue 99999
start with 1
increment by 1
cache 50;
创建存储过程填充表格
create or replace procedure test_trigger(
a in integer, --定义in模式的变量,它存储部门编号
b in integer, --定义in模式的变量,它存储部门名称
c in integer) is
begin
insert into test
values(a,b,c); --向test表中插入记录
end;
begin
while test_seq.currval <=99998
loop
test_trigger(test_seq.nextval,test_seq.currval,test_seq.currval); --调用test_trigger存储过程,传入参数
commit;
end loop; --提交数据库
end;无索引查询行数:
select count(*) from test;
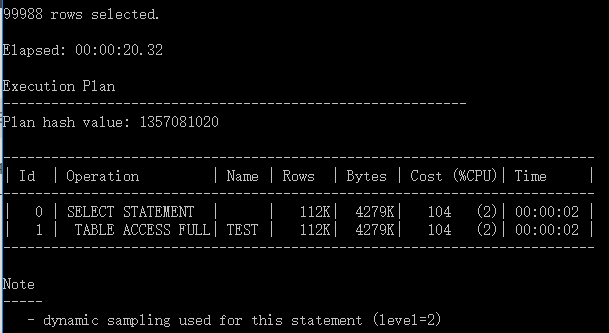
创建复合索引
create index in_test1 on test (a,b,c)
alter system flush buffer_cache;–清除缓存
select count(*) from test;
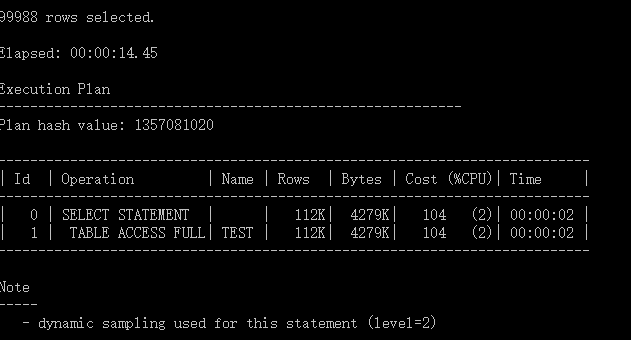
where条件查询
select * from test where a=33333 and b=33333 and c=33333; 250ms
select * from test where c=33333 and b=33333 and a=33333; 313ms
几乎无差别!
而以下查询相差较大:
select * from test where a=33333; 90ms
select * from test where b=33333; 180ms
select * from test where c=33333; 203ms
实验复合索引内部和外部联系问题
删除原复合索引drop index in_test1;重建新的索引create index in_test1 on test (a,b);
select * from test where a=33333; 47ms
select * from test where b=33333; 141ms
select * from test where c=33333; 219ms
select * from test where a=22222 and b=22222; 100ms
select * from test where a=22222 and c=22222; 172ms
select * from test where b=22222 and c=22222; 203ms
单索引和复合索引的比较
create index in_test_a on test (a);
create index in_test_b on test (b);
select * from test where a=33333; 40ms
select * from test where b=33333; 40ms
select * from test where a=33333 and b=33333;
1.何时是用复合索引
在where条件中字段用索引,如果用多字段就用复合索引。一般在select的字段不要建什么索引(如果是要查询select col1 ,col2, col3 from mytable,就不需要上面的索引了)。根据where条件建索引是极其重要的一个原则。注意不要过多用索引,否则对表更新的效率有很大的影响,因为在操作表的时候要化大量时间花在创建索引中.
2.对于复合索引,在查询使用时,最好将条件顺序按找索引的顺序,这样效率最高。如:
IDX1:create index idx1 on table1(col2,col3,col5)
select * from table1 where col2=A and col3=B and col5=D
如果是”select * from table1 where col3=B and col2=A and col5=D”
或者是”select * from table1 where col3=B”将不会使用索引,或者效果不明显
从以上试验中,我们可以看到如果仅用聚集索引的起始列作为查询条件和同时用到复合聚集索引的全部列的查询速度是几乎一样的,甚至比用上全部的复合索引列还要略快(在查询结果集数目一样的情况下);而如果仅用复合聚集索引的非起始列作为查询条件的话,这个索引是不起任何作用的。当然,语句1、2的查询速度一样是因为查询的条目数一样,如果复合索引的所有列都用上,而且查询结果少的话,这样就会形成“索引覆盖”,因而性能可以达到最优。同时,请记住:无论您是否经常使用聚合索引的其他列,但其前导列一定要是使用最频繁的列。














 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









