







本文转自:http://blog.sina.com.cn/s/blog_6ae183910101gily.html
---------------------------------------------------------------
昨天,百度上线了新的相似图(similar image search)搜索,试了风景、人物、文字等不同类型query的效果,感觉效果非常赞。尤其对于人物搜索,返回的结果在颜色、以及姿态方面具有非常大的相似性。特别是在输入某个pose的美女图片时,会搜到一系列相近pose的美女图片,真的是宅男之福啊。
我们知道这个产品底层的技术是余凯老师领导的百度多媒体图像组做的,但是到底是如何做到的,我相信大家一定都非常好奇。在这里,我按照自己的理解,讲讲我认为其背后的具体技术方案,更希望能和大家进行更深入的讨论,我们共同进步。
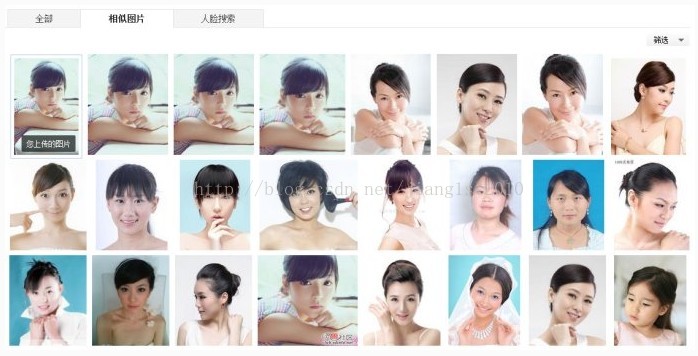
而如果query的图片中没有人脸,则只会有前两个tab“全部”和“相似图片”。
而实际上,底层的图像相关的技术(content based)支持的是三个不同的功能,分别是相同图片搜索(near duplicate search)、相似图片搜索(similar image search)和人脸搜索(face search),而这三个功能对应的技术也有比较大的区别。从功能角度,“全部”tab里面主要包含了两部分功能,上面是相同图片搜索(以及对应的图片周围的文本,把图片看作是信息载体)以及下面的相似图片搜索功能。
下面我会一一剖析一下相同图片搜索(near duplicate search)、相似图片搜索(similar image search)和人脸搜索(face search)这三个不同功能背后可能用到的技术。
对于图片搜索而言,一种最直观的思路就是对图像进行表示(表示为特征),然后计算query图像和库中索引的所有图像的特征之间的相似度(或距离)度量,然后排序就可以得到搜索结果了。在早期的image retrieval学术中,大家一般这样处理就够了。但是,这样做的问题是,只能处理数据规模小的数据库(比如百万量级以下),否则速度将十分难以接受。
为了提高搜索速度,一个可以借鉴的思路来自于文字搜索。在文字搜索里面,基本的框架是基于tf-idf表示以及倒排的索引结构来处理的。所谓tf是文章中的词频,idf是逆文档频率。如果将图像和文章对应,visual word和词(term)对应,则图像也存在对应的tf和idf。所以,真正实用的大规模图像搜索系统一般都是采用类似文本搜索的框架,首先通过visual word表示为视觉词频表示,或者采用某种hash的方法转化为binary code的方法来处理,提高搜索速度。这是最基本最核心的思路。
对于相同图片搜索,做的最早的应该算tineye.com,国内搜狗和百度识图都有这个功能,当然,之前我觉得做的最好的是image.google.com。这个技术主要目标是找到同一张图像的不同变形版本(亮度变化、部分裁剪、加水印等),衡量其效果的一个重要因素就是抗击上述变形大小的能力,此外,为了能够提供召回,所以索引量一定要非常大。这块的应用,主要是用来找到同一张图片的更高质量版本或者可以用来做图片版权追踪。
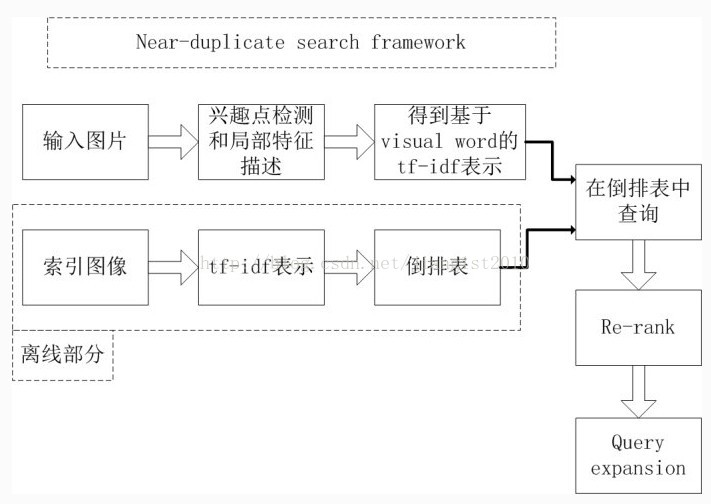
其中,兴趣点检测和局部特征描述有很多方法可以选择,SIFT特征是大家比较常用的特征。将图像表示为很多兴趣点上定义的sift特征之后,离线训练一个词表(一般采用层次型kmean等方法,当然还有其他类似random projection的方法),总之,就是一个vector quantization,从而,能够得到一幅图像的关于词的频率统计(也可以看作是一种直方图累积)。于是,后面的流程就可以借鉴文本里面用到的方法了。由于上述过程中,没有考虑到兴趣点的位置,因此,为了过滤掉误检结果,一般在re-rank模块,会采用基于兴趣点位置约束的过滤方法过滤掉兴趣点位置和query图像不同的结果,当然,由于此时,返回的结果已经远远小于所有的索引量,因此可以采用运算复杂度更高的方法来进一步重新排列结果。
为了,提高召回率,一个比较好的方法是采用query expansion的方法,采用query得到的结果中选择相似度最高的几项(相似度大于某个阈值),得到和query最相近的结果,然后将这些结果和query组合成为新的query,重新到索引中搜素。一种简单的方式是做feature级别的平均。这样,可以得到更高的召回率。
当然,上述只是相同图像检测框架的综述,具体的处理方式可能会不同,也可能采用一些特别的trick来提高响应速度和精度以及召回率。这方面可以参考的两篇文献是[1]、[2]。
下面来接着聊相似图搜索的技术方案。相似图相对相同图的难度更高,相似图本身的定义就不是非常确定,目前,在百度推出相似图之前,google的相似度检测是做得比较好的。不过百度新推出的相似图搜索确实非常惊艳。目前,大家所做的都是视觉上面的相似,而不是真正语义上的相似。
相同图检测可以算作是比较成熟的技术,而相似度搜索的方法则具有不确定性。下面,我猜测一下百度的方案。
首先,百度的相似图检测应该是基于全图特征的,和相同图检测不同的是,相似图前面没有采用兴趣点检测,而是直接将全图分辨率归一化之后,直接表示为某种特征(feature representation)。而这个特征直接决定了后续搜索结果的优劣。由于一幅图像就表示为一个定长的feature,因此,没办法采用visual word的方法进行表示(或者说我不知道如何做)。为了快速搜索,我猜测其后面应该是将这个特征转化为hash序列,然后根据hash值将其映射到多个区间,只处理落在同一个区间的图像,从而减少需要处理的索引量而提高了搜索速度。具体的,一种比较容易想到的方式是采用类似minhash等LSH方法进行处理,将特征表示为K个独立的hash,并根据hash结果映射到M个不同的区间上,然后只需要处理和输入query落在某一个区间中的索引,这样,可以大大降低搜索的运算量。这样做的依据是,两幅图像之间的相似度,可以转化为minhash所度量的相似度,通过调整上述的hash函数数目,以及划分的区间的数目,如果两个图片对应的minhash相似度大于某个阈值,则两者必然会落在至少一个共同的区间中,从而保证了召回率。具体原理可以google simhash了解。
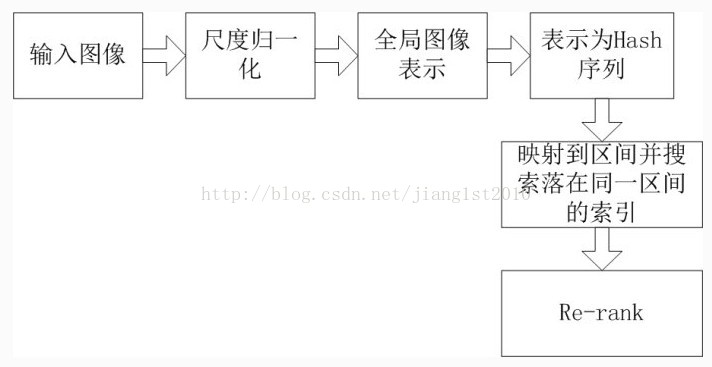
由于上述处理过程中存在近似以及hash可能产生的碰撞,因此,在获取到候选索引后,需要进一步采用re-rank的方法来重新排列结果。此时,由于待处理的数据量已经降低,因此,可以采用更原始的特征表示来进行处理(当然,猜测这一步里面也有很多trick,是决定效果的十分重要的因素)。
让我们回头来猜测相似图搜索的全局表示。对于图像的全局表示,有很多传统方法,诸如颜色直方图、纹理、边缘、形状等,但是,百度的相似图搜索应该是采用了深度学习(deep learning)技术,原因呢?一个是因为效果实在是非常赞,感觉传统方法很难达到这样的结果(原谅我作为深度学习粉的脑残程度吧),另外一个重要原因是余凯老师自己承认了,哈哈。当然,在看到他承认之前,很多同学已经高度怀疑是用深度学习做的了。
那么具体是用什么方法实现的呢?我能明确的是:首先输入一定是用了彩色图像(不是灰度图像),因为一看结果就能看到颜色的相似性;其次,由于其对形状出现的位置具有较好的鲁棒性和位置相关性,因为,在逐层抽特征时,一方面,在全局上,用了图像位置相关的结构,同时,在小局部,用了能提高局部鲁棒性的pooling技术。当然,在相似图片搜索中不存在类别概念,因此,可以推测其deep learning是采用了非监督(unsupervised learning)的方法得到的对图像更抽象更具有区分度的表示。至于具体方案,我想是可以有不同选择的。我们不妨猜测是用了深层cnn的结构吧。对上层的输入和当前层链接时,抽取了重叠的很多区域来进行处理,局部小块共用了权重,然后采用pooling逐层降低特征的维度。当然,在顶层也可以采用其它DNN结构,这应该都是可行的。
对于相似图搜索而言,如果只需要做到视觉的相似性(不考虑语义上的相似),如果你能搞定全局的表示问题,那么后面的快速搜索应该可以用相对成熟的技术去搞定。而深度学习是进行全局表示的非常有前途的方法。当然,在具体实现中,一定有很多技巧和困难,做了的人才知道,我没做过,只好yy一下。
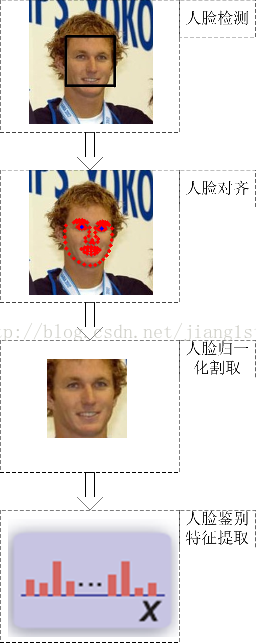
关于人脸检测、特征点定位都具有比较成熟的算法,比如可以参考文献[4][5]。而对于人脸表示,值得一提的是,按照余凯老师在公开场合讲的,百度也采用了具有深度结构(deep structure)的方法做的,也就是说也是应用了深度学习的方法做的。关于人脸识别领域的深度学习方法应用,我看到的一篇最好结果[3]是在LFW数据上4种特征融合达到92%的结果,其实这个结果并不足够好,比如最新的MSRA的工作单种特征可以达到93%的结果[6]。而百度的方法属于自创,在公开的文献中是找不到参考的。不过,我认为条条大路通罗马,其它deep learning的框架也应该可以达到很好的效果,只是,还需要我们大家摸索一段时间。
在得到人脸的表示之后,下面要讨论的是如何快速的搜索到人脸。和相似图像搜索类似,人脸搜索得到的特征,对于每个人脸都是定长的一个feature,容易想到的方法也是采用类似minhash的lsh方法进行处理。由于,在query名人照片时,得到的返回结果中存在很多和输入人脸差别较大的结果,所以我比较倾向于认为在人脸搜索中也用了query expansion的方法来提高召回率。下面给出我心目中的人脸搜索处理流程图:
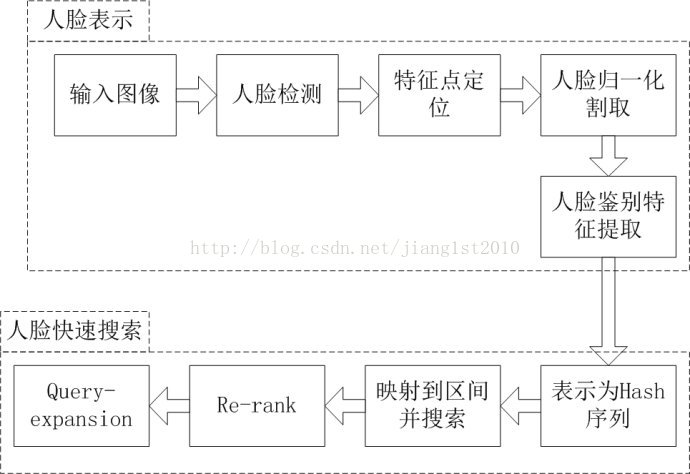
同样,在re-rank环节可以采用运算量较大的处理手段提高结果的精度。
好了,猜测时间结束。如果大家认为我猜测的是错误的或者有更好的思路,请提出来讨论,帮助我提高。
多yy几句。
我们看到,其一,在图像搜索领域,以百度为代表的国内工业界做到了非常高的水准,可以和世界上的最高水平进行pk(这句话我是认真比较过说的);其二,深度学习方法在图像理解各个领域(人脸识别、OCR、以及相似图搜索)的应用以及所取得了非常赞的结果;其三,在大规模图像处理方面的方法,具有很多相通之处,比如文字搜索的方法可以对图像搜索的方法有所启发,进一步,可以对人脸搜索的方法进行启发;其四,大规模图像数据和深度学习给传统的图像理解带来了新的思路和方法。
从技术角度,一方面,这个时期对于搞计算机视觉的人而言,这是个令人激动的时间点,大规模数据以及深度学习,使得很多原本进展缓慢的应用都取得了明显的提高。而另外一方面,我们也需要看到基于智能图像的应用还没有非常成功的先例,即使是百度新推出的人脸搜索和相似图像搜索,在应用上也没有找到非常成功的应用。所以,革命尚未成功,做计算机视觉的各位同志还需要努力。
在应用方面,我觉得后面可以关注的几个点包括:一个是关于移动方面的图像应用,语音已经成为移动的一个重要交互手段,图像是否能抢得一点入口呢?另外一个是和硬件结合的智能图像技术已经成为非常重要的交互设备,由于有硬件传感器/光源的帮助,在技术上可以做到相对成熟,能够大规模产品化,这其中的代表包括kinect、leap motion等,未来是否能出现和手机、智能电视结合更好的交互设备呢?
参考论文:
1.
2.
3.
4.
5.
6.














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









