







为无为,事无事,味无味。大小多少。报怨以德。
图难于易,为大于其细;
天下难事,必作于易;天下大事,必作于细。
----老子
最近在学习爬虫,遇到了一个烦人的问题-----博客上的代码,十个有六个编译通过不了,特别忧愁。只能把程序模块化,分步调试,明白了这其中的原委:第一:网页的排版有了更新,以前能够使用正则表达式或者beautiful soup等提取相关内容,由于现在网页版本格式变了,以至于提取不出来相关的信息(主要原因);二:如果你使用的是scrapy框架,这是一个开源项目,版本一直在更新,有些函数已经被弃用了(查查最近文档,比较好解决)。
当然,无论学习什么,总是不抱着一口吃成一个胖子的心态是最好的,遇到问题,要会拆解和调试,最主要的是,通过问题来入门。如果一开始爬虫的路是顺畅的,估计里面的原理我也不会去深究了。这是开源中国社区里面的一篇文章:使用scrapy建立一个网页抓取器,里面的文档翻译的很详细,下面是我的一些自己的理解,以及对代码的更新改进。
首先使用下面命令来创建一个名为hn的scrapy项目
scrapy startproject hn
使用cd命令,你就可能看到下图所示的文件分布,其中hn与scrapy.cfg是同一目录下的内容:
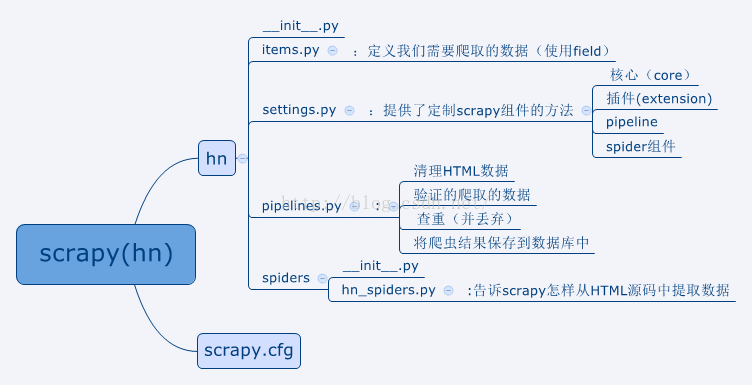
在这个图中,我把每个需要自己添加代码的.py文件的功能标注了出来,所以使用scrapy来爬虫的大致流程是:
定义爬取数据-->写爬虫程序-->处理爬虫数据(展示或者存入数据库)
在这个过程中,网页解析和数据库是两个相对来说难一点的地方。
在这篇文章中,由于所https://news.ycombinator.com/网页的html的格式发生了变化,所以需要我们自己修改一下解析式。不信我们对第一条新闻下按右键,选择审查元素,出现下面的内容:
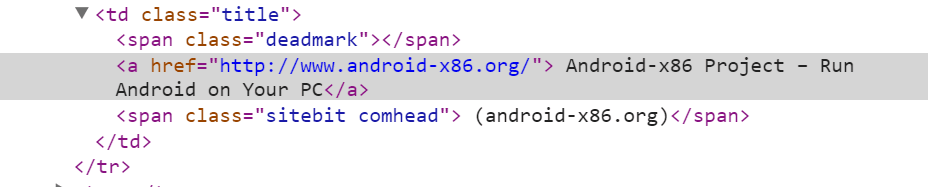
而它的解析式所下所示:

仔细推导,发现新的网页多了<span clasa...>这一块,所以在学习爬虫阅读别人的代码时候,需要注意到这一点,生搬别人的程序,往往不一定有结果。
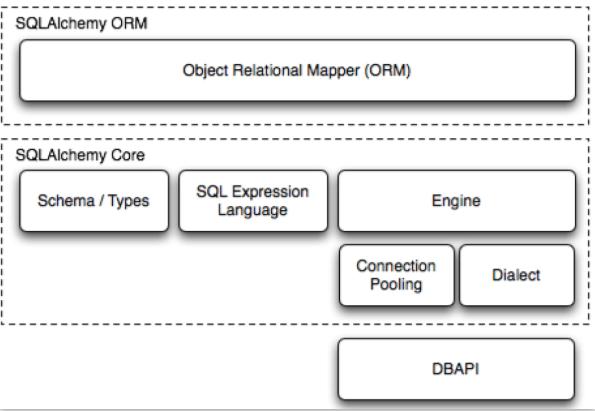
此文中,还使用了sqlalchemy数据库,下面是官网上的图片,sqlalchemy主要包括以下两部分:
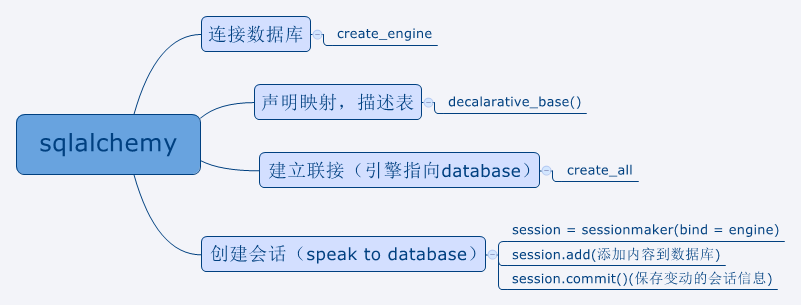
下面是我提取出来的一个框架,我们在pipeline.py处理数据库的内容,下图展示了一个sqlalchemy数据库程序应该包含的模块及相应模块需要使用到的函数,具体内容看其官方文档。
修改后的代码可以在此处下载:
参考资料:
http://docs.sqlalchemy.org/en/rel_1_0/orm/tutorial.html
http://scrapy-chs.readthedocs.org/zh_CN/1.0/search.html
http://www.zouyesheng.com/sqlalchemy.html#toc1
http://wangye.org/blog/archives/722/















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









