







Spark 2.0.0发布已经有一段时间了,目前公司生产环境还是使用1.6系列版本。为了测试Spark 2.0.0各方面的稳定性和计算性能,我基于CDH集群环境,搭建了Spark On Yarn集群环境。
环境信息:
CDH版本:CDH-5.7.0
其中,Hadoop版本:2.6.0
Java版本:1.7.0_80
Scala版本:2.11.7
Spark版本:spark-2.0.0-bin-hadoop2.6
Spark集群规划:
IP地址 | 主机名 | 角色 |
10.20.24.199 | SZB-L0029554 | Master/Worker |
10.20.24.196 | SZB-L0029556 | Worker |
10.20.24.198 | SZB-L0029557 | Worker |
10.20.24.200 | SZB-L0029558 | Worker |
10.20.24.201 | SZB-L0029559 | Worker |
安装步骤如下:
1. Spark集群的每个节点的/etc/hosts添加所有的集群主机信息
127.0.0.1 localhost
10.20.24.199 SZB-L0029554
10.20.24.196 SZB-L0029556
10.20.24.198 SZB-L0029557
10.20.24.200 SZB-L0029558
10.20.24.201 SZB-L0029559
2. 给Spark单独规划用户和用户组
groupadd -g 8888myspark
useradd -m -d /var/lib/myspark -g spark -u 5888 myspark
passwd myspark
3. Spark集群所有节点部署Java
Java部署好之后要记得配置环境变量(/etc/profile)并source生效,如下:
export JAVA_HOME=/usr/java/latest
export JRE_HOME=/usr/java/latest/jre
export PATH=$PATH:$JAVA_HOME/bin
exportCLASSPATH=./:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
验证:
[root@SZB-L0029554 ~]# echo$JAVA_HOME
/usr/java/latest
[root@SZB-L0029554 ~]# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment(build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixedmode)
4. Spark集群所有节点部署Scala
Scala部署好之后,配置环境变量并source生效,如下:
export SCALA_HOME=/usr/local/scala
export PATH=.:$SCALA_HOME/bin:$PATH
[root@SZB-L0029554 ~]# echo$SCALA_HOME
/usr/local/scala
[root@SZB-L0029554 ~]# scala-version
Scala code runner version 2.11.7 -- Copyright 2002-2013,LAMP/EPFL
5. Spark集群的节点间创建信任关系
6. Spark集群的每个节点关闭防火墙等服务
7. Spark的Master节点安装部署
解压缩并设置软链接,安装后的目录如下:
[myspark@SZB-L0029554 ~]$ ll
total 4
lrwxrwxrwx 1 myspark spark 25 Aug 8 14:20 spark -> spark-2.0.0-bin-hadoop2.6
drwxr-xr-x 13 myspark spark 4096 Aug 8 15:03 spark-2.0.0-bin-hadoop2.6
配置环境变量(myspark用户家目录的.bashrc):
exportSPARK_HOME=/var/lib/myspark/spark
export PATH=.:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
使环境变量生效:
[myspark@SZB-L0029554 ~]$ source .bashrc
8. Spark的Master节点配置
8.1 创建目录并修改属组和属主
mkdir -p /hadoopdata1/sparkdata/local
mkdir -p /var/lib/myspark/spark/logs
mkdir -p /hadoopdata1/sparkdata/work
chown -R myspark:myspark/hadoopdata1/sparkdata
8.2 配置conf/spark-env.sh
export SPARK_HOME=/var/lib/myspark/spark
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
SPARK_MASTER_HOST=10.20.24.199
#web页面端口
SPARK_MASTER_WEBUI_PORT=28686
#Spark的local目录
SPARK_LOCAL_DIRS=/hadoopdata1/sparkdata/local
#worker目录
SPARK_WORKER_DIR=/hadoopdata1/sparkdata/work
#Driver内存大小
SPARK_DRIVER_MEMORY=4G
#Worker的cpu核数
SPARK_WORKER_CORES=16
#worker内存大小
SPARK_WORKER_MEMORY=64g
#Spark的log日志目录
SPARK_LOG_DIR=/var/lib/myspark/spark/logs
8.3 配置slaves
SZB-L0029554
SZB-L0029556
SZB-L0029557
SZB-L0029558
SZB-L0029559
8.4 配置spark-defaults.conf
#建议开启,可以对已完成的任务记录其详细日志
spark.eventLog.enabled true
#eventLog的文件存放位置
spark.eventLog.dir hdfs://SZB-L0023776:8020/myspark/eventLog/applicationHistory
其他值保持默认即可。
9. 将Master的Spark整个目录拷贝到Worker节点
scp -r spark-2.0.0-bin-hadoop2.6 myspark@SZB-L0029556:/var/lib/myspark/
scp -r spark-2.0.0-bin-hadoop2.6 myspark@SZB-L0029557:/var/lib/myspark/
scp -r spark-2.0.0-bin-hadoop2.6 myspark@SZB-L0029558:/var/lib/myspark/
scp -r spark-2.0.0-bin-hadoop2.6 myspark@SZB-L0029559:/var/lib/myspark/
另外将Master节点的.bashrc环境变量也拷贝到所有的Worker节点并执行source命令使环境变量生效。
10. 启动Spark集群环境
在Master节点上启动Spark集群:
[myspark@SZB-L0029554 ~]$ start-all.sh
查看Master节点的进程:
[myspark@SZB-L0029554 ~]$ jps
29593 Master
29709 Worker
29970 Jps
再查看其他Worker节点的进程:
[myspark@SZB-L0029556 ~]$ jps
25276 Jps
24754 Worker
11. 通过Web UI查看
我们访问http://szb-l0029554:28686/页面,查看内容:
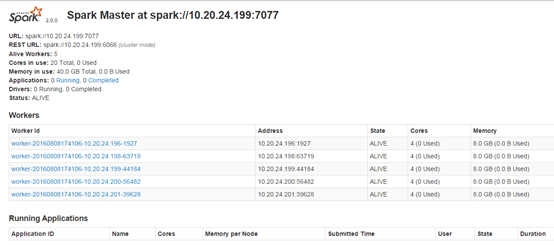
可以看到有5个Workers。
12. Spark环境验证
我们先执行官网自带的计算Pi的例子:
[myspark@SZB-L0029554 ~]$ spark-submit --masterspark://SZB-L0029554:7077 --class org.apache.spark.examples.SparkPi --nameSparkPI /var/lib/myspark/spark/examples/jars/spark-examples_2.11-2.0.0.jar
输出结果为:
Pi is roughly 3.1383756918784593
下面我们通过Yarn资源调度平台来执行相关操作:
[myspark@SZB-L0029554 ~]$ spark-shell --master yarn
Spark context Web UI available athttp://10.20.24.199:4040
Spark context available as 'sc'(master = yarn, app id = application_1469373167347_0106).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version2.0.0
/_/
Using Scala version 2.11.8 (JavaHotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have themevaluated.
Type :help for more information.
scala> val textFile =sc.textFile("/myspark/testdata/README.md")
textFile:org.apache.spark.rdd.RDD[String] = /myspark/testdata/README.mdMapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.filter(line =>line.contains("Spark")).count()
res0: Long = 19
我们上面执行的是统计HDFS文件系统上的/myspark/testdata/README.md文件里面包含Spark的行数。
可以根据上面日志提示的网址http://10.20.24.199:4040来查看作业执行情况,当我们使用浏览器访问http://10.20.24.199:4040时会自动调整到Yarn的管理页面,比如我这里是
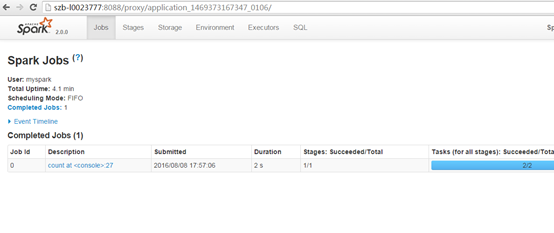














 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









