







常用排序算法的复杂度分析整理
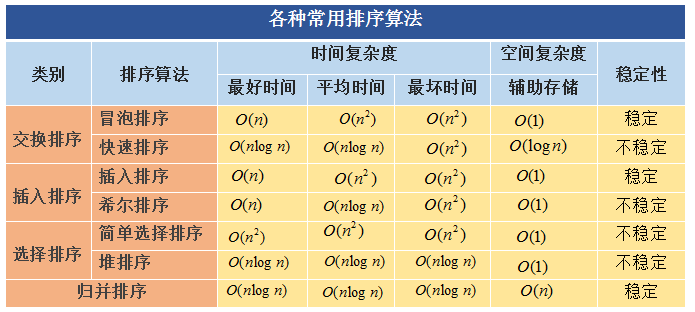
具体分析如下:
1 冒泡排序(BubbleSort)
冒泡排序是最慢的排序算法。在实际运用中它是效率最低的算法。它通过一趟又一趟地比较数组中的每一个元素,使较大的数据下沉,较小的数据上升。它是O(n^2)的算法。
步骤:
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
(3)针对所有的元素重复以上的步骤,除了最后一个。
(4)持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
详细原理及实现参照:冒泡排序原理及Java实现
2 选择排序(SelectSort)
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。
这种排序方法效率是 O(n2)。在实际应用中处于和冒泡排序基本相同的地位。它们只是排序算法发展的初级阶段,在实际中使用较少。
详细原理及实现参照:选择排序原理及Java实现
3 插入排序(InsertSort)
插入排序(Insertion Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。
步骤:
(1)从第一个元素开始,该元素可以认为已经被排序
(2)取出下一个元素,在已经排序的元素序列中从后向前扫描
(3)如果该元素(已排序)大于新元素,将该元素移到下一位置
(4)重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
将新元素插入到该位置中
(4)重复步骤2
详细原理及实现参照:插入排序原理及Java实现
4 Shell排序(ShellSort)
希尔排序,也称递减增量排序算法,是插入排序的一种高速而稳定的改进版本。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
(1)插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
(2)但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。
Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。
详细原理及实现参照:希尔排序原理及Java实现
5 堆排序(HeapSort)
堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
详细原理及实现参照:堆排序原理及Java实现
6 归并排序(MergeSort)
归并排序(Merge sort,台湾译作:合并排序)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用.
归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。
步骤:
(1)申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
(2)设定两个指针,最初位置分别为两个已经排序序列的起始位置
(3)比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
(4)重复步骤3直到某一指针达到序列尾
(5)将另一序列剩下的所有元素直接复制到合并序列尾
详细原理及实现参照:归并排序原理及Java实现
7 快速排序(QuickSort)
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要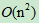
快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。
(1) 如果不多于1个数据,直接返回。
(2) 一般选择序列最左边的值作为支点数据。
(3) 将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。
(4) 对两边利用递归排序数列。
快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。
详细原理及实现参照:快速排序原理及Java实现














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









