







chapter 2: lambda表达式
2.1 lambda表达式不同形式
//实现Runnable接口
Runnable noArguments = ()->System.out.println("hello girl");
// 一个参数省略括号
ActionListener oneArgument = event -> System.out.println("button clicked");
Runnable multiStatement = () -> {
System.out.println("hello");
System.out.println(" girl");
};
// 不是两个数的相加, 而是创建了一个函数,用了计算两数相加的结果
// 参数类型可以由编译推断出来
BinaryOperator<Long> add = (x + y) -> x + y;
BinaryOperator<Long> addExplict = (Long x, Long y) -> x + y;
Lambda表达式中引用的局部变量必须是final或既成事实上的final变量。
既成事实的意思是这个变量没有被改变过。
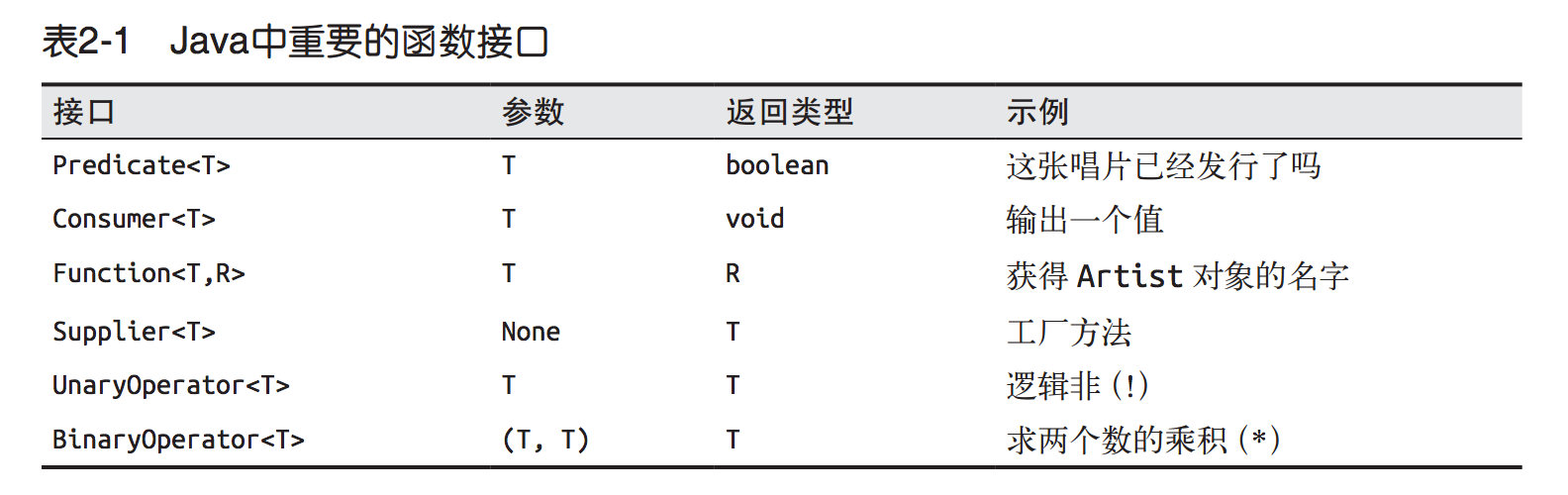
2.2 函数接口
函数接口是只有一个抽象方法的接口,用作Lambda表达式的类型。
2.3 类型推断
可以省略Lambda表达式上下文信息就能推断出参数的正确类型。
Predicate<Integer> atLeast = x -> x > 5;
System.out.println(atLeast.test(6)); // true
图示:
public interface Predicate<T> {
boolean test(T t);
}
public interface function<T, R> {
R apply(T t);
}
/**
* 指定参数和返回值都是Long类型的
*/
BinaryOperator<Long> addLongs = (x, y) -> x + y;
System.out.println(addLongs.apply(4l, 5l)); // 9 chapter3: 流
3.1 小demo
找出所有London街区的艺术家,计算他们的总人数:
int count = 0;
for (Artist artist : allArtists) {
if (artist.isFrom("London")) {
count++;
}
}
//流式的写法
long count = allArtists.stream().filter(artists -> artist.isFrom("London")).count();filter只描述stream, 最终不产生新集合的方法叫做 惰性求值方法,而像count这样最终会从stream产生值得方法叫做 及早求值方法。返回值是stream的就是惰性求值,返回值是另一个值或为空就是及早求值的情况。
整个过程和建造者设计模式有共通之处,建造者模式使用一系列操作设置属性和配置,最后调用一个build方法,这时,对象才被真正创建。
3.2 collect(toList())
collect(toList())方法由Stream里的值生成一个列表,是一个及早求值操作。
List<String> collected = Stream.of("a", "b", "c").collect(Collectors.toList());collect(toList())方法从Stream中生成一个列表。
3.3 map
有一个函数可以将一种类型的值转换成另外一种类型,map操作就可以使用该函数,将一个流中的值转换成一个新的流。
/**
* map
*/
List<String> collected1 = Stream.of("a", "b", "hello").map(stringArg -> stringArg.toUpperCase()).collect(Collectors.toList());
System.out.println(collected1); map()中的参数是一个Funcion的函数式的接口, 这个接口就是将一个数转换成另一个数。
3.4 filter
/**
* filter
*/
List<String> beginWithNumbers = Stream.of("a", "1hello", "dd2").filter(value -> Character.isDigit(value.charAt(0))).
collect(Collectors.toList()); for循环中的if判断条件就可以使用对应filter方法来替代。
filter()中的lambda表达式的函数式接口就是Predicate。
3.5 flatMap
flatMap方法可用Stream替换值,然后将多个Stream连接成一个Stream。
/**
* flatMap
*/
List<Integer> together = Stream.of(Arrays.asList(1, 3), Arrays.asList(3, 4)).flatMap(numbers -> numbers.stream())
.collect(Collectors.toList());
System.out.println(together); //[1, 3, 3, 4] 包含多个列表的流,通过flatMap得到所有数字的序列。
flatMap的函数接口和map方法一样,都是Function接口,只是其返回值为Stream类型罢了。
3.6 max和min
/**
* max min
*/
List<Track> tracks = Arrays.asList(new Track("Bakai", 524),
new Track("Violets for your Furs", 378), new Track("Time Was", 451));
Track shortTrack = tracks.stream().min(Comparator.comparing(track -> track.getLength())).get();
assertEquals(tracks.get(1), shortTrack); comparing接受一个函数并返回另一个函数,调用空Stream的max方法,返回去Optional对象。Optional对象表示一个可能存在也可能不存在的值。如果Stream为空,那么该值不存在,如果不为空,则该值存在。可以调用get方法取出Optional对象中的值。
3.7 reduce
reduce 操作可以实现从一组值中生成一个值。上述中用到的count、min和max方法因为常用而被纳入标准库中,实际上这些方法都是reduce操作。
/**
* reduce
*/
int count = Stream.of(1, 2, 3).reduce(0, (acc, element) -> acc + element);
System.out.println(count); // 6 以0作起点——一个空Stream的求和结果,每一步都将Stream中的元素累加至acc,遍历至Stream中的最后一个元素时,acc的值就是所有元素的和。
将reduce操作展开如下:
BinaryOperator<Integer> accumulator = (acc, element) -> acc + element;
int sum = accumulator.apply(
accumulator.apply(
accumulator.apply(0, 1), 2
), 3
); 3.8 整合例子
找出专辑中是乐队的表演者的国籍:
1. Album类有个getMusicians方法,该方法返回一个Stream对象,包含整张专辑中所有的表演者;
2. 使用filter过滤只保留乐队;
3. 使用map方法将乐队隐射为其所属国家;
4. 使用collect(Collectors.toList())方法将国籍放入一个列表。
Set<String> origins = album.getMusicians()
.filter(artist -> artist.getName().startWith("The"))
.map(artist -> artist.getNationality())
.collect(toSet());filter和map方法都返回Stream对象,因此都属于惰性求值,collect方法属于及早求值。map方法接受一个Lambda表达式,使用该Lambda表达式对Stream上的每个元素做隐射,形成一个新的Stream。
3.9 重构遗留代码
从一组专辑(Album)中找出找出所有长度大于1分钟的曲目(Track)名称。
老代码:
public Set<String> findLongTracks(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
for (Album album : albums) {
for (Track track : album.getTrackList()) {
if (track.getLength() > 60) {
String name = track.getName();
trackNames.add(name);
}
}
}
return trackNames;
}重构第一步,修改for 循环,使用Stream的forEach方法替换掉for循环。
/**
* 重构第一步 forEach替换掉for循环
* getTracks()方法本身就返回一个Stream
*/
public Set<String> findLongTracks1(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream().forEach(album -> {
album.getTracks().forEach(track -> {
if (track.getLength() > 60) {
String name = track.getName();
trackNames.add(name);
}
});
});
return trackNames;
}重构第二步:
/**
* 重构第二步, 加入filter 和 map
* @param albums
* @return
*/
public Set<String> findLongTracks2(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream().forEach(album -> {
album.getTracks().filter(track -> track.getLength() > 60)
.map(track -> track.getName())
.forEach(name -> trackNames.add(name));
});
return trackNames;
}使用filter过滤集合元素后返回过滤后的集合Stream,然后map重组元素生成一个新的Stream,然后再次调用forEach将曲目名添加入集合。其中trackNames 这个变量是既成事实上必须是final的。
重构第三步:
/**
* 重构第三步, flatMap将多个Stream合成一个Stream返回
* @param albums
* @return
*/
public Set<String> findLongTracks3(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream().flatMap(album -> album.getTracks())
.filter(track -> track.getLength() > 60)
.map(track -> track.getName())
.forEach(name -> trackNames.add(name));
return trackNames;
}
重构第四步:
/**
* 重构第四步, flatMap将多个Stream合成一个Stream返回
* @param albums
* @return
*/
public Set<String> findLongTracks4(List<Album> albums) {
return albums.stream().flatMap(album -> album.getTracks())
.filter(track -> track.getLength() > 60)
.map(track -> track.getName())
.collect(Collectors.toSet());
}map重构一个Stream后调用及时求值方法collect即可生成一个Set集合。map中是一个Function函数式接口,map(track -> track.getName()) 这样的传一个track, 返回一个String类型的数据,最后map将这些Sting类型的数据组装成一个Stream返回。
3.10 高阶函数
高阶函数是指接受另外一个函数作为参数,或返回一个函数的的函数。如果函数的参数列表里包含函数接口,或该函数返回一个函数接口,那么函数就是高阶函数。
map是一个高阶函数,它的mapper参数是一个函数。还有如comparing函数,他接受一个函数作为参数,获取相应的值,同时返回一个Comparator,Comparator可能会被误认为是一个对象,但它有且只有一个抽象方法,实际是一个函数接口。
3.11 正确使用Lambda
使用lambda表达式获取值而不是变量,通过使用一段lambda表达式代码快速计算出自己想要的结果,编写没有副作用的代码。另外forEach方法是一个终结方法。
Chapter 4 类库
4. 1 使用lambda表达式
Logger logger = new Logger();
if (logger.isDebugEnabled()) {
logger.debug("Look at this: " + expensiveOperation());
}
// 使用lambda表达式简化代码
Logger logger = new Logger();
logger.debug(() -> "Look at this: " + expensiveOperation());
// 上面使用的lambda表达式实现的日志记录器
public void debug(Supplier<String> message) {
if (logger.isDebugEnabled()) {
logger.debug("Look at this: " + expensiveOperation());
}
}4.2 基本类型
public static void printTrackLengthStatistics(Album album) {
IntSummaryStatistics trackLengthStats = album.getTracks()
.mapToInt(track -> track.getLength()).summaryStatistics();
System.out.printf("Max: %d, min: %d, Ave: %f, Sum: %d",
trackLengthStats.getMax(),
trackLengthStats.getMin(),
trackLengthStats.getAverage(),
trackLengthStats.getSum());
}mapToInt可以从一个基本类型的Stream得到一个装箱后的Stream,Stream< Integer>。
Lambda expressions have the types of their functional interfaces,the same rules apply when passing them as arguments.
4. 3 Lambda表达式作为函数参数类型推导
In summary, Lambda表达式作为参数时,其类型由它的目标类型推导得出,推导过程遵循如下规则:
- If there is a single possible target type, the lambda expression infers the type from the corresponding argument on the functional interface.
- If there are several possible target types, the most specific type is inferred.
- If there are several possible target types and there is no most specific type, you must manually provide a type.
对比例子:
interface IntegerBiFunction extends BinaryOperator<Integer> {
}
public class Chapter4 {
private void overLoadedMethod(BinaryOperator<Integer> lambda) {
System.out.println("ones ");
}
private void overloadedMethod(IntegerBiFunction lambda) {
System.out.println("other ");
}
public static void main(String[] args) {
new Chapter4().overLoadedMethod((x, y) -> x + y); // 对应最具体的类型,打印出ones
}
}4.4 @FunctionalInterface
This is an annotation that should be applied to any interface that is intended to be used as a functional interface.
Using the annotation compels javac to actually check whether the interface meets the criteria for being a functional interface.
Chapter 5 Advanced Collections and Collectors
5.1 集合排序
Set<Integer> numbers = new HashSet<>(Arrays.asList(4, 3, 2, 1, 10));
List<Integer> sameOrder = numbers.stream().sorted().collect(Collectors.toList()); //sorted()排序
/**
* 对集合中的每个元素 +1
*/
Set<Integer> unsorted = numbers.stream().map(x -> x + 1).collect(Collectors.toSet()); //Some operation are more expensive on ordered streams. This problem can be solved by eliminating ordering.To do so, call the stream’s unordered method. Most operations, however, such as filter, map, and reduce, can operate very efficiently on ordered streams.
This can cause unexpected behavior, for example, forEach provides no guarantees as to encounter order if you’re using parallel streams. If you require an ordering guarantee in these situations, then forEachOrdered is your friend!
用特定的集合收集元素:
stream.collect(toCollection(TreeSet::new));5.2 To Values
/*
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
Finding the band with the most members
*/
public Optional<Artist> biggestGroup(Stream<Artist> artists) {
Function<Artist, Long> getCount = artist -> artist.getMembers().count();
return artists.collect(Collectors.maxBy(Comparator.comparing(getCount)));
}It’s also possible to collect into a single value using a collector. There are maxBy and minBy collectors that let you obtain a single value according to some ordering.
minBy, which does what is says on the tin.
找出一组专辑的平均曲目数(Finding the average number of tracks for a list of albums)
public double averageNumber(List<Album> albums) {
return albums.stream().collect(Collectors.averagingInt(album -> album.getTrackList().size()));
}通过调用stream方法让集合生成流,然后调用collect方法收集结果。
the averagingInt method, which take a lambda expression in order to convert each element in the stream into an int before averaging the values.
There are also overloaded operations for the double and long types, which let you convert your element into these type of values. The collectors offer other similar functionality, such as summingInt and friends.
IntStream, had additional functionality for numerical operation, and other SummaryStatistics.
5.3 partitioningBy
将流分成两部分,partitioningBy接受一个流,并将其分成两部分。It users a Predicate to determine whether an element should be part of the true group or the false group and returns a Map from Boolean to a List of values. So, the Predicate returns true for all the values in the true List and false for the other List.
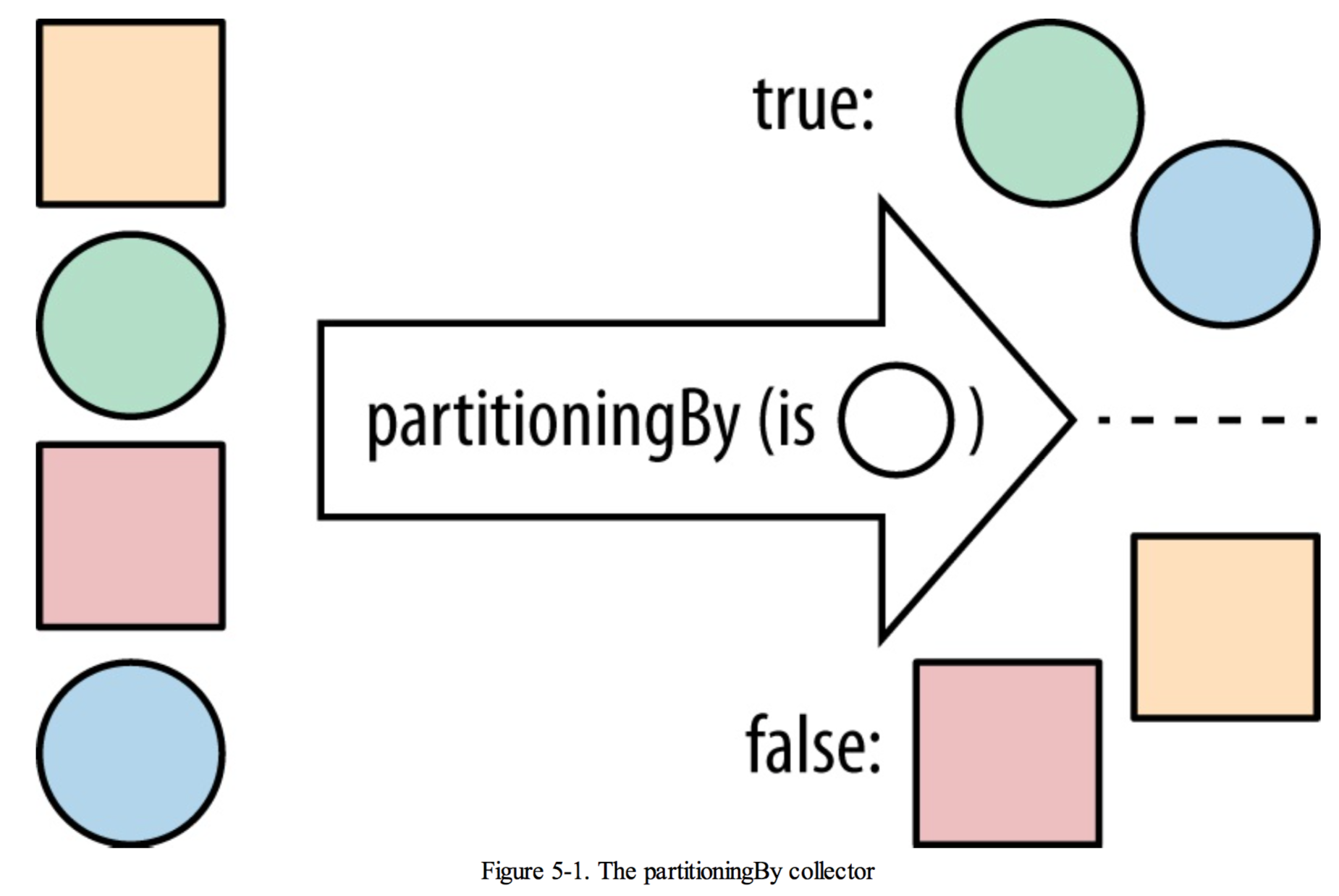
// Partitioning a stream of artist into bands and solo artists
public Map<Boolean, List<Artist>> bandsAndSolo(Stream<Artist> artists) {
return artists.collect(partitioningBy(artist -> artist.isSolo()));
}
// method references
public Map<Boolean, List<Artist>> bandsAndSoloRef(Stream<Artist> artists) {
return artists.collect(partitioningBy(Artist::isSolo));
}
/*
public boolean isSolo() {
return members.isEmpty();
}
*/5.4 groupingBy
对数据进行分组,比如将数据分成true和false两部分,也可以使用任意的值对数据进行分组。
// Grouping albums by their main artist(主唱)
public Map<Artist, List<Album>> albumsByArtist(Stream<Album> albums) {
return albums.collect(groupingBy(album -> album.getMainMusician()));
}
/*
public Artist getMainMusician() {
return musicians.get(0);
}
*/Calling collect on the Stream and passing in a Collector.
The groupingBy collector takes a classifier function in order to partition the data, just like the partitioningBy collector took a Predicate to split it up into true and false values. Here classifier is a Function- the same type that we use for the common map operation.
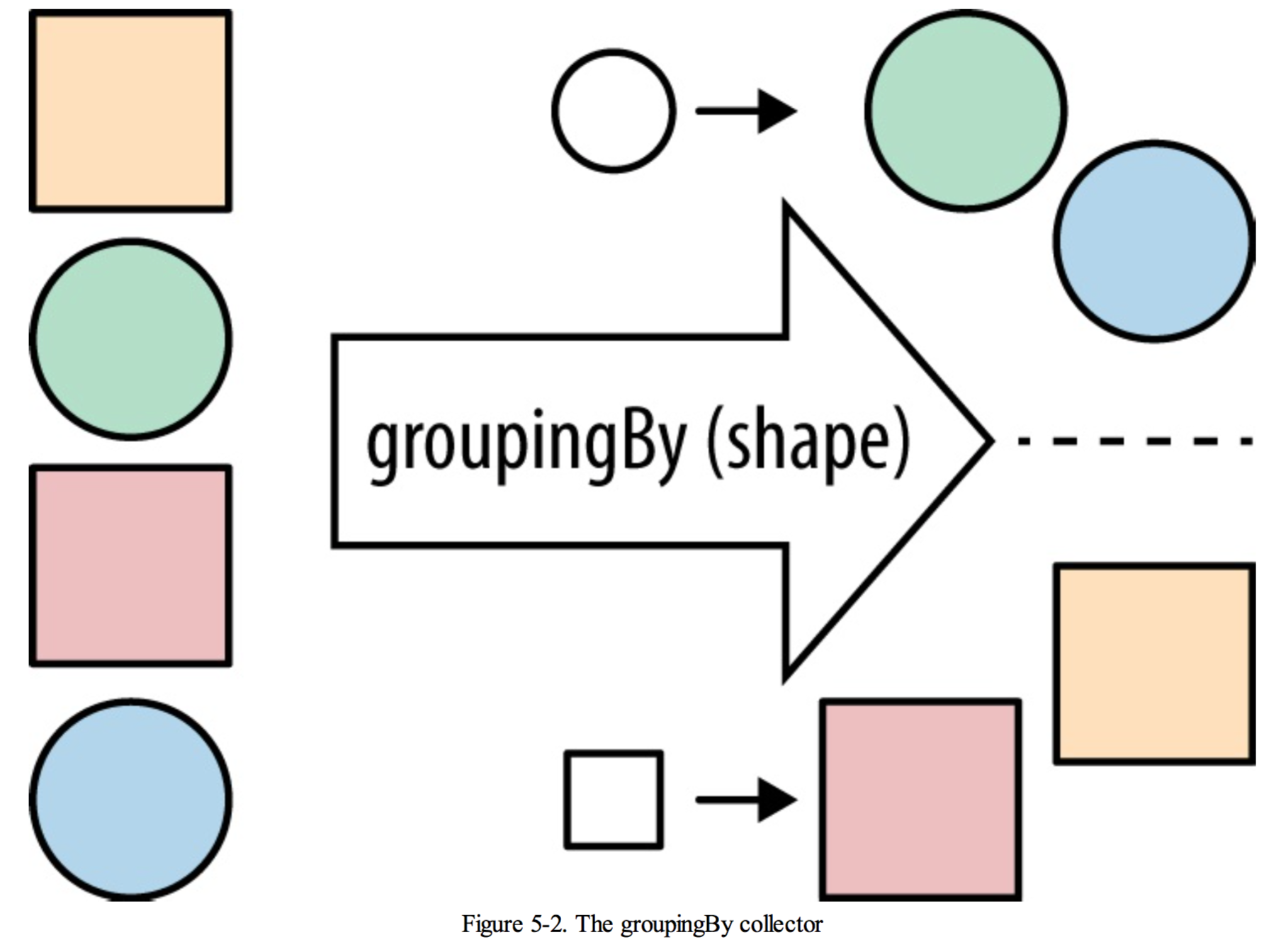
就想SQL中的group by 一样
5.5 To Strings
// Formatting artist names using a for loop
// Look like "[Jack Chou, John Lennon, George Harrison]"
public static String formatArtistsForLoop(List<Artist> artists) {
// BEGIN for_loop
StringBuilder builder = new StringBuilder("[");
for (Artist artist : artists) {
if (builder.length() > 1)
builder.append(", ");
String name = artist.getName();
builder.append(name);
}
builder.append("]");
String result = builder.toString();
// END for_loop
return result;
}Formatting artist names using streams and collectors .
public static String formatArtists(List<Artist> artists) {
// BEGIN collectors_joining
String result =
artists.stream()
.map(Artist::getName)
.collect(Collectors.joining(", ", "[", "]"));
// END collectors_joining
return result;
}Using map to extract artists’ names then collect the Stream using Collectors.joining.This method is convenience for building up strings from streams.It lets us provide a delimiter(which goes between elements[分割元素]), a prefix for our result, and a suffix(后缀) for the result.
5.6 Composing Collectors (组合收集器)
组合Collector,功能会变得很强大,
如下,计算一个艺术家的专辑数量, 每张专辑对应一个艺术家:
// A naive approach to counting the number of albums for each artist.
public Map<Artist, Integer> numberOfAlbumsDumb(Stream<Album> albums) {
// BEGIN NUMBER_OF_ALBUMS_DUMB
Map<Artist, List<Album>> albumsByArtist
= albums.collect(groupingBy(album -> album.getMainMusician()));
Map<Artist, Integer> numberOfAlbums = new HashMap<>();
for(Entry<Artist, List<Album>> entry : albumsByArtist.entrySet()) {
numberOfAlbums.put(entry.getKey(), entry.getValue().size());
}
// END NUMBER_OF_ALBUMS_DUMB
return numberOfAlbums;
}
/*
public Artist getMainMusician() {
return musicians.get(0);
}
*/We could use forEach, it takes a BiConsumer (two values enter, return empty). Such as:
public Map<Artist, Integer> numberOfAlbumsDumb(Stream<Album> albums) {
Map<Artist, List<Album>> albumsByArtist
= albums.collect(groupingBy(album -> album.getMainMusician()));
Map<Artist, Integer> numberOfAlbums = new HashMap<>();
albumsByArtist.forEach((artist, albums) -> {
numberOfAlbums.put(artist, albums.size());
});
return numberOfAlbums;
}Luckily, there is actually another collector that tells groupingBy that instead of building up a List of albums for each artist, it should just count them.
public Map<Artist, Long> numberOfAlbums(Stream<Album> albums) {
return albums.collect(groupingBy(album -> album.getMainMusician(), counting()));
}This form of groupingBy divides elements into buckets.Each bucket gets associated with the key provided by the classifier function:getMainMusician.The groupingBy operation then uses the downstream collector to collect each bucket and makes a map of the results.
求每个艺术家的专辑名, 简单的方式:
public Map<Artist, List<String>> nameOfAlbumsDumb(Stream<Album> albums) {
Map<Artist, List<Album>> albumsByArtist = albums.collect(groupingBy(album ->album.getMainMusician()));
Map<Artist, List<String>> nameOfAlbums = new HashMap<>();
for(Entry<Artist, List<Album>> entry : albumsByArtist.entrySet()) {
nameOfAlbums.put(entry.getKey(), entry.getValue().stream()
.map(Album::getName)
.collect(toList()));
}
return nameOfAlbums;
}使用收集器的方式:
Using Collectors to find the names of every album that an artist has produced.
public Map<Artist, List<String>> nameOfAlbums(Stream<Album> albums) {
return albums.collect(groupingBy(Album::getMainMusician, mapping(Album::getName, toList())));
}
/*
public String getName() {
return name;
}
*/列表由groupingBy生成,需要有一个方法告诉groupingBy将它的值做映射,生成最终结果。Each collector is a recipe for building a final value.What we really want is a recipe to give to our recipe - another collector. That is mapping.
The mapping collector allows you to perform a map-like operation over your collector’s container.这里需要指明使用什么样的Collection to store the results in, which you can do with the toList collector.
Just like map, mapping takes an implementation of Function.
In total:
In both of these cases, we’ve used a second collector in order to collect a subpart of the final result. These collectors are called downstream collectors(下游收集器).
In the same way that a collector is a recipe for building a final value, a downstream collector is a recipe for building a part of that value, which is then used by the main collector.
5.7 Refactoring and Custom Collectors
来看这一段段重构且不断改进的代码:
1)
// Formatting artist names using a for loop
// Look like "[Jack Chou, John Lennon, George Harrison]"
public static String formatArtistsForLoop(List<Artist> artists) {
StringBuilder builder = new StringBuilder("[");
for (Artist artist : artists) {
if (builder.length() > 1)
builder.append(", ");
String name = artist.getName();
builder.append(name);
}
builder.append("]");
String result = builder.toString();
// END for_loop
return result;
}2)
Using a forEach and a StringBuilder to pretty-print the names of artists
public static String formatArtistsRefactor1(List<Artist> artists) {
StringBuilder builder = new StringBuilder("[");
artists.stream()
.map(Artist::getName)
.forEach(name -> {
if (builder.length() > 1)
builder.append(", ");
builder.append(name);
});
builder.append("]");
String result = builder.toString();
return result;
}Unfortunately, there’s still this very large forEach block that doesn’t fit into our goal of writing code that is easy to understand by composing high-level operations.
3) Using a reduce and a StringBuilder to pretty-print the names of artists.
Starting with an empty StringBuilder – the identity of the reduce. Next lambda expression combines a name with a builder. The third argument to reduce takes two StringBuilder instances and combine them.Final step is to add the prefix at the beginning and the suffix at the end.
public static String
formatArtistsRefactor2(List<Artist> artists) {
StringBuilder reduced =
artists.stream()
.map(Artist::getName)
.reduce(new StringBuilder(), (builder, name) -> {
if (builder.length() > 0)
builder.append(", ");
builder.append(name);
return builder;
}, (left, right) -> left.append(right));
reduced.insert(0, "[");
reduced.append("]");
String result = reduced.toString();
return result;
}4) Using a reduce and a custom StringCombiner to pretty-print the names of artists.
// StringCombiner
public class StringCombiner {
private final String delim;
private final String prefix;
private final String suffix;
private final StringBuilder builder;
public StringCombiner(String delim, String prefix, String suffix) {
this.delim = delim;
this.prefix = prefix;
this.suffix = suffix;
builder = new StringBuilder();
}
public StringCombiner add(String element) {
if (areAtStart()) {
builder.append(prefix);
} else {
builder.append(delim);
}
builder.append(element);
return this;
}
private boolean areAtStart() {
return builder.length() == 0;
}
public StringCombiner merge(StringCombiner other) {
if (other.builder.length() > 0) {
if (areAtStart()) {
builder.append(prefix);
} else {
builder.append(delim);
}
builder.append(other.builder, prefix.length(), other.builder.length());
}
return this;
}
@Override
public String toString() {
if (areAtStart()) {
builder.append(prefix);
}
builder.append(suffix);
return builder.toString();
}
}Using reduce in order to combine names and delimiters into a StringBuilder.This time, though, the logic of adding elements is being delegated to the StringCombiner.add() method and the logic of combining two different combiners is delegated to StringCombiner.merge().
add()方法返回一个StringCombiner对象,因为这是传给reduce操作所需要的类型。
public static String formatArtistsRefactor3(List<Artist> artists) {
StringCombiner combined =
artists.stream()
.map(Artist::getName)
.reduce(new StringCombiner(", ", "[", "]"),
StringCombiner::add,
StringCombiner::merge);
String result = combined.toString();
return result;
}5) refactor reduce operation into a Collector, which we can use anywhere in our application. Let’s create our StringCollector.
import java.util.Collections;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
/**
A collector is composed of four different
components.First we have a supplier, which is a
factory for making our container--in this case, a
StringCombiner.
*/
public class StringCollector implements Collector<String, StringCombiner, String> {
private static final Set<Characteristics> characteristics = Collections.emptySet();
private final String delim;
private final String prefix;
private final String suffix;
public StringCollector(String delim, String prefix, String suffix) {
this.delim = delim;
this.prefix = prefix;
this.suffix = suffix;
}
@Override
public Supplier<StringCombiner> supplier() {
return () -> new StringCombiner(delim, prefix, suffix);
}
@Override
public BiConsumer<StringCombiner, String> accumulator() {
return StringCombiner::add;
}
@Override
public BinaryOperator<StringCombiner> combiner() {
return StringCombiner::merge;
}
@Override
public Function<StringCombiner, String> finisher() {
return StringCombiner::toString;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}// Collecting strings using a custom StringCollector
public static String formatArtistsRefactor5(List<Artist> artists) {
String result = artists.stream()
.map(Artist::getName)
.collect(new StringCollector(", ", "[", "]"));
return result;
}Collector is generic, so we need to determine a few types to interact with:
- The type of the element that we’ll be collecting, a String
- Our accumulator type, StringCombiner, which you’ve already seen
- The result type, also a String
1)
public Supplier<StringCombiner> supplier() {
return () -> new StringCombiner(delim, prefix, suffix);
}Collectors can be collected in parallel, we will show a collecting operation where two container objects are used in parallel.
Each of the four components of our Collector are functions, so we’ll represent the as arrows. The values in our Stream are circles, and the final value we’re producing will be an oval.At the start of the collect operation our supplier is used to create new container objects.
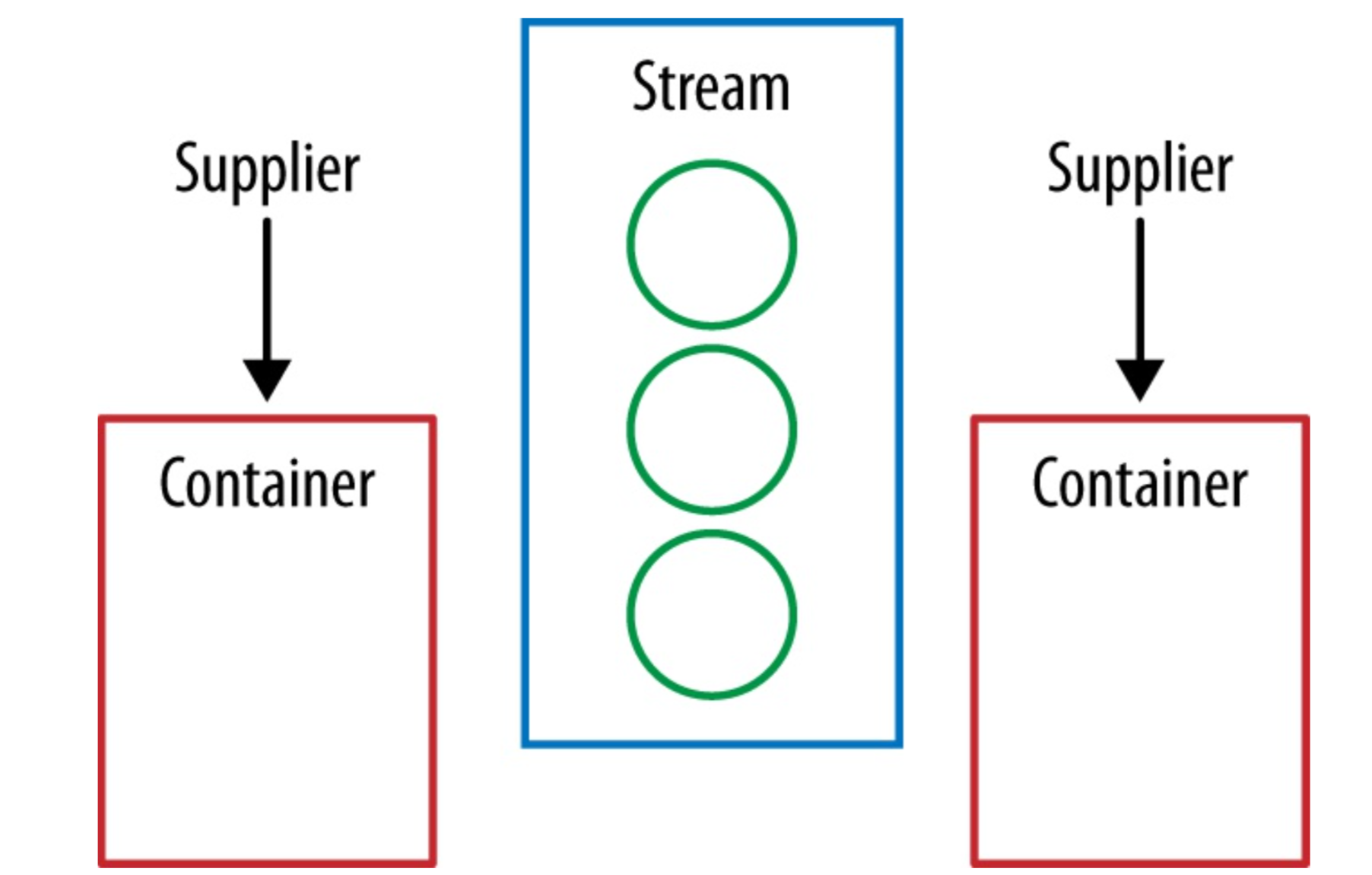
Figure: Supplier
2)
// An accumulator is a function to fold the current element into the collector
public BiConsumer<StringCombiner, String> accumulator() {
return StringCombiner::add;
}
Collector’s accumulator performs the same job as the second argument to reduce.It takes the current element and the result of the preceding operation and return a new value.We’ve already implemented this logic in the add method of Our StringCombiner.
The accumulator is used to fold the stream’s value into the container objects.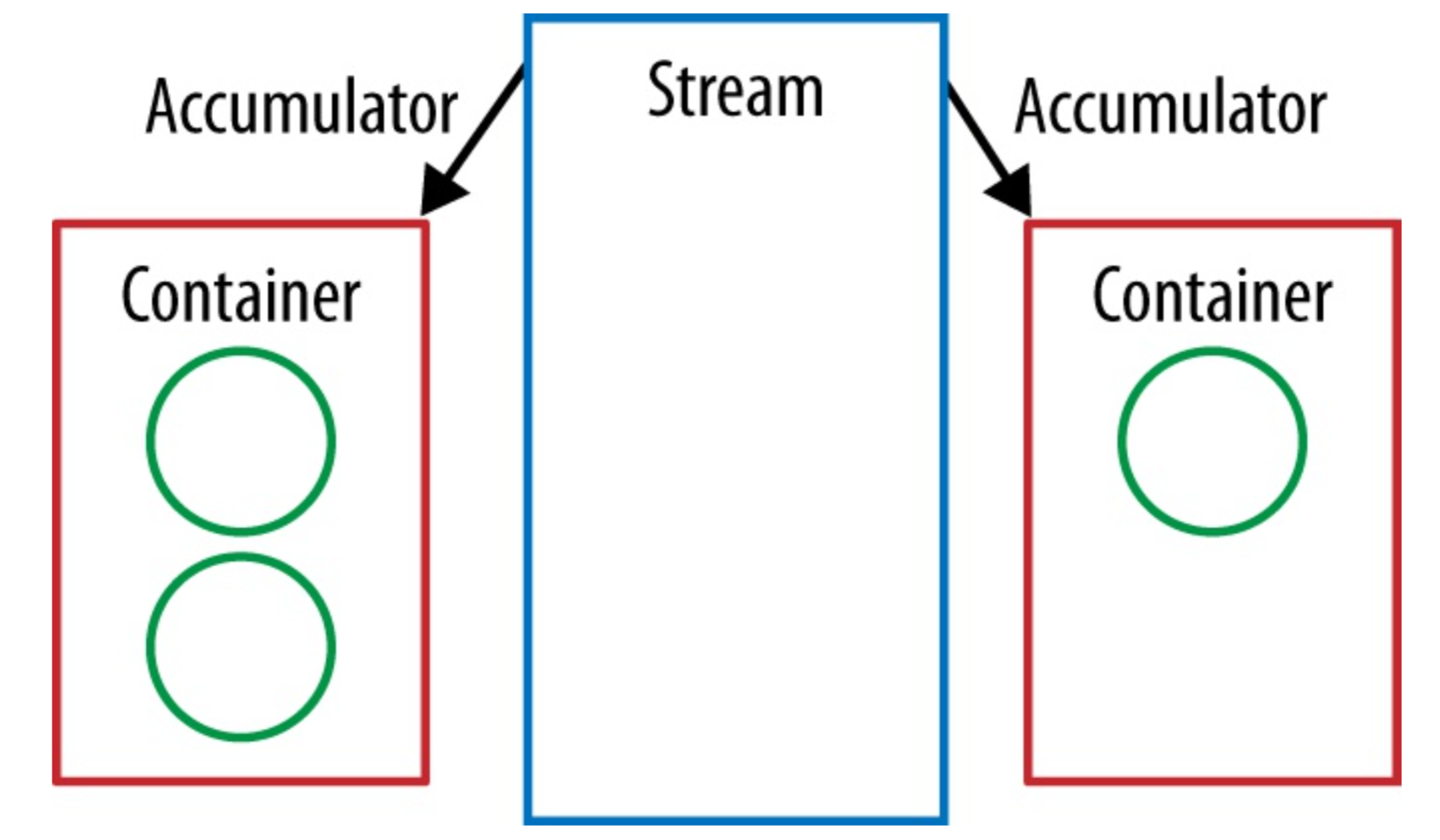
Figure: accumulator
3)
The combine method is an analogue of the third method of our reduce operation.If we have two containers, then we need to be able to merge them together.Again, we’ve already implemented this in a previous refactor step, so we just use the StringCombiner.merge method.
public BinaryOperator<StringCombiner> combiner() {
return StringCombiner::merge;
}During the collect operation, our container objects are pairwise merged using the defined combiner until we have only one container at the end.
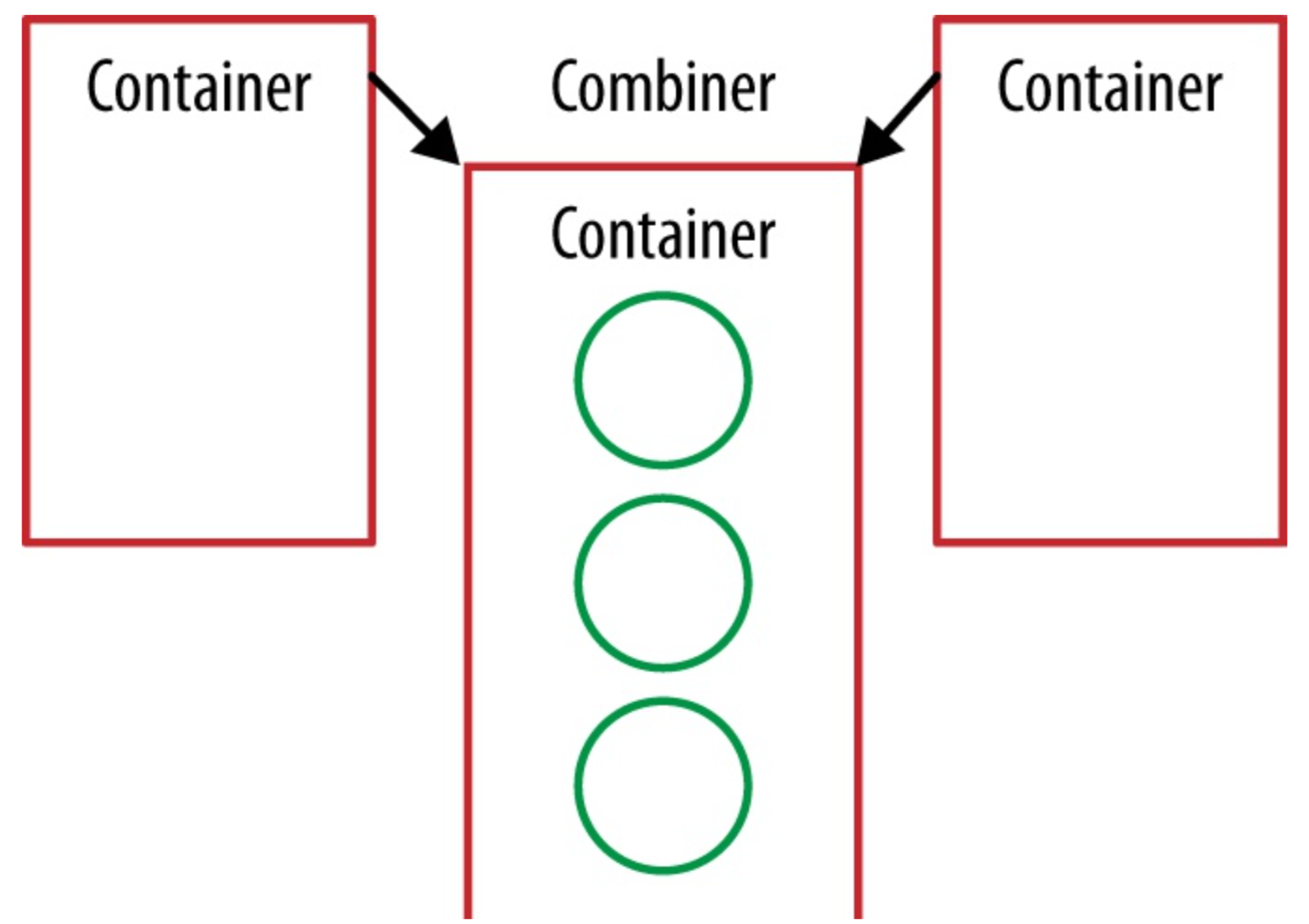
Figure: Combiner
4)
The last step in our refactoring process, before we got to collectors, was to put the toString method inline at the end of the method chain. This converted our StringCombiner into the String that we really wanted.
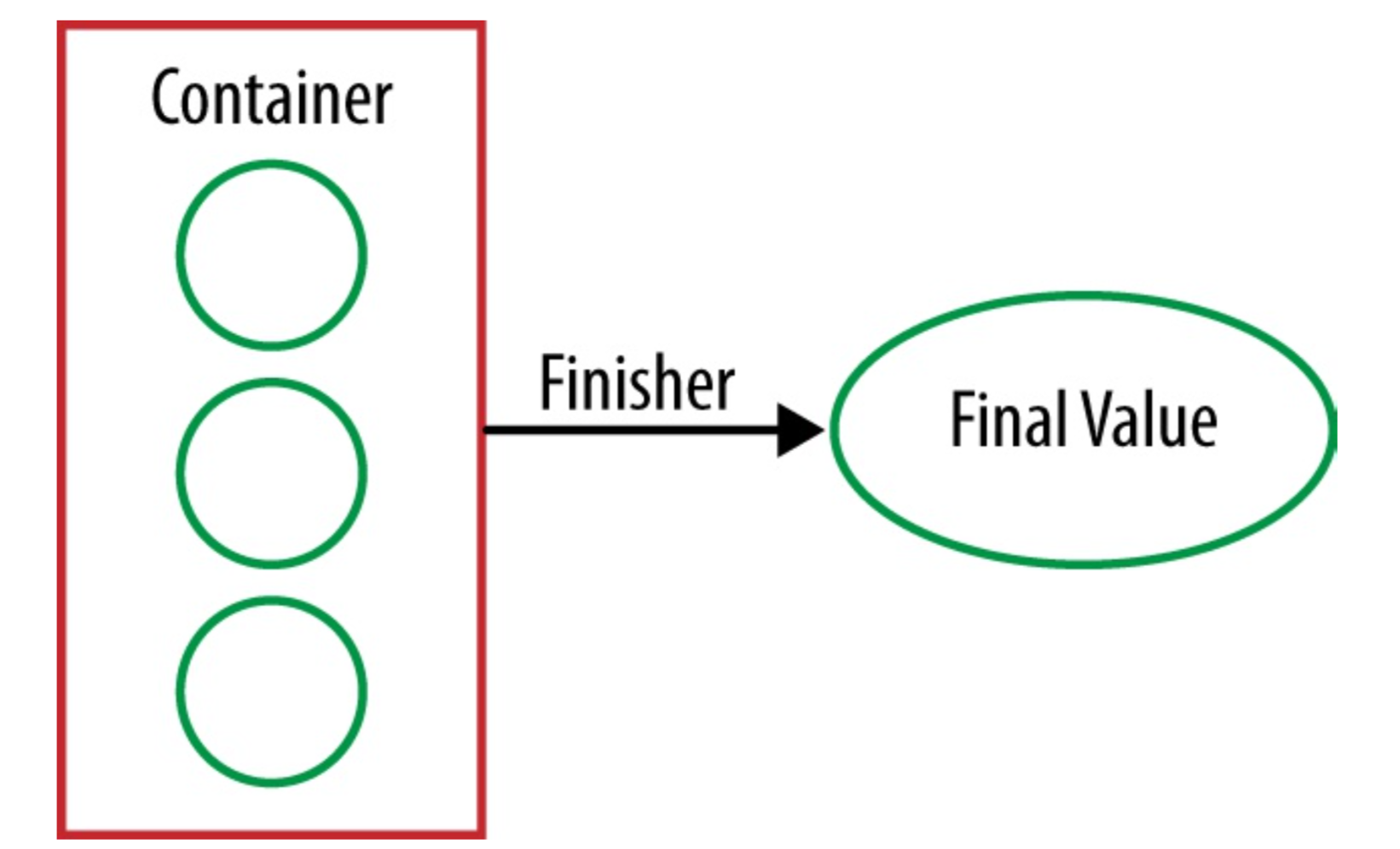
Figure: Finisher
5)
Collector’s finisher method performs the same purpose. We’ve already folded our mutable container over a Stream of values, but it’s not quite the final value that we want. The finisher gets called here, once, in order to make that conversion.
public Function<StringCombiner, String> finisher() {
return StringCombiner::toString;
}6)
public Set<Characteristics> characteristics() {
return characteristics;
}A characteristic is a Set of objects that describes the Collector, allowing the framework to perform certain optimizations.
Java 8 contains a java.util.StringJoiner class that performs a similar role and has a similar API.
5.8 一些细节
// Caching a value using an explicit null check
public Artist getArtist(String name) {
Artist artist = artistCache.get(name);
if (artist == null) {
artist = readArtistFromDB(name);
artistCache.put(name, artist);
}
return artist;
}Cache as Map<String, Artist> artistCache and were wanting to look up artists using an expensive database operation.
Java8 introduces a new computeIfAbsent method that takes a lambda to compute the new value if it doesn’t already exist.
public Artist getArtist(String name) {
return artistCache.computeIfAbsent(name, this::readArtistFromDB);
}You may want variants of this code that don’t perform computation only if the value is absent; the new compute and computeIfPresent methods on the Map interface are useful for these cases.














 6110
6110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









