







简介
学习一种新的技术,在深入技术细节之前,首先需要了解这项技术的产生的背景,了解技术的总体框架。本文介绍了Hadoop基本概念、Hadoop重要模块、守护进程,以使读者能够对Hadoop有一个总体的认识。
Hadoop是什么
按照正式的定义,Hadoop是一个开源的框架,可编写和运行分布式应用,处理大规模数据。分布式计算是一个宽泛并且不断变化的领域,但Hadoop与众不同之处在于以下几点。
1. 方便-Hadoop运行在由一般商用机器构成的大型集群上,或者如亚马逊弹性计算云(EC2)等云计算服务之上。
2. 健壮-Hadoop致力于在一般商用硬件上运行,其架构假设硬件会频繁地出现失效。它可以从容地处理大多数此类故障。
3. 可扩展-Hadoop通过增加集群节点,可以线性地扩展以处理更大的数据集。
4. 简单-Hadoop允许用户快速编写出高效的并行代码。
Hadoop的方便和简单让其在编写和运行大型分布式程序方面占尽优势。即使是在校的大学生也可以快速、廉价地建立自己的Hadoop集群。另一方面,它的健壮性和可扩展性又使它胜任雅虎和Facebook最严苛的工作。这些特性使Hadoop在学术界和工业界都大受欢迎。
Hadoop构造模块
Hadoop作为大数据处理的框架,能够以并行和分布式的方式,存储和处理大数据集。它主要包括两部分:HDFS实现了在集群中数据的存储,MapReduce实现数据的并行处理存储在HDFS中的数据。
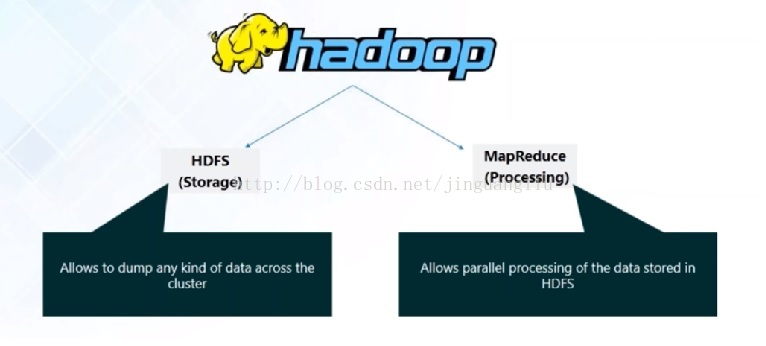
在一个全配置的集群上,“运行Hadoop”意味着在网络分布的不同服务器上运行一组守护进程(daemons)。这些守护进程有特殊的角色,一些仅存在于单个服务器上,一些则运行在多个服务器上。这些守护进程分别属于Hadoop的HDFS和MapReduce,将在后面的讲解中逐一介绍。
HDFS(Hadoop Distributed File System)
HDFS以集群的方式工作,通过对管理的资源提供了一个抽象层,使得我们可以将整个HDFS看作一个整体单元。

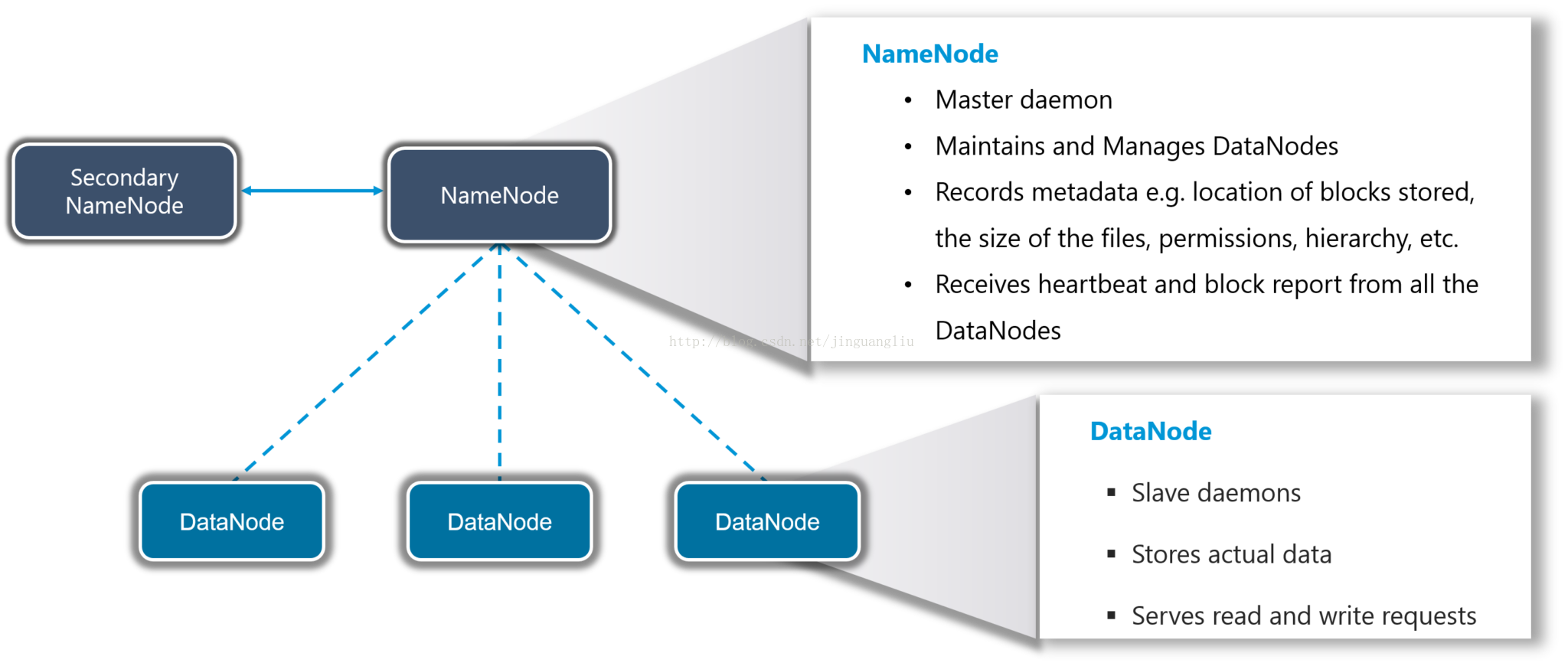
HDFS由两个核心组件,分别是NameNode和DataNode。这两类节点在HDFS集群中以管理者(master)-工作者(slave)模式运行,即一个NameNode和多个DataNode。
NameNode
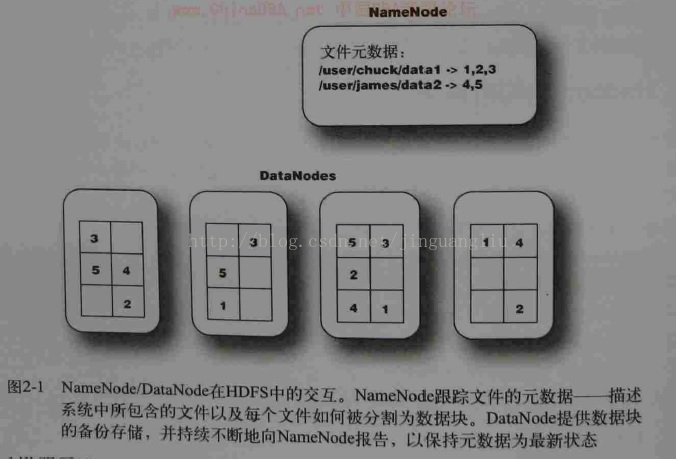
NameNode管理文件系统的命名空间,维护文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。NameNode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建。运行NameNode消耗大量的内存和I/O资源,因此,为了减轻机器的负载,驻留NameNode的服务器通常不会存储用户数据或者执行MapReduce程序的计算任务。
不过NameNode的重要性也带来了一个负面影响,一旦NameNode出现了故障,则整个集群失效。为提供NameNode的冗余保护,提供了Secondary NameNode。
Secondary NameNode(SNN)是一个用于监测HDFS集群状态的辅助守护进程。像NameNode一样,每个集群有一个SNN,它通常也独占一台服务器,该服务器不会运行其他的DataNode或TaskTracker守护进程。SNN与NameNode的不同在于它不接收或记录HDFS的任何实时变化。相反,NameNode通信,根据集群所配置的时间间隔获取HDFS元数据的快照。
如前所述,NameNode是Hadoop集群的单一故障点,而SNN的快照可以有助于减少宕机的时间并降低数据丢失的风险。然而,NameNode的失效处理需要人工的干预,即手动地重新配置集群,将SNN用作主要的NameNode。
DataNode
DataNode是文件系统的工作节点,每个集群上的从节点都会驻留一个DataNode守护进程,来执行分布式文件系统的繁重工作:它们根据需要存储并检索数据块(受客户端或NameNode调度),并且定期向NameNode发送它们所存储的块的列表。当希望对HDFS文件进行读写时,文件被分割为多个块,由NameNode告知客户端每个数据块驻留在哪个DataNode。客户端直接与DataNode守护进程通信,来处理与数据块相应的本地文件。而后,DataNode会与其它DataNode进行通信,复制这些数据块的冗余。
MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
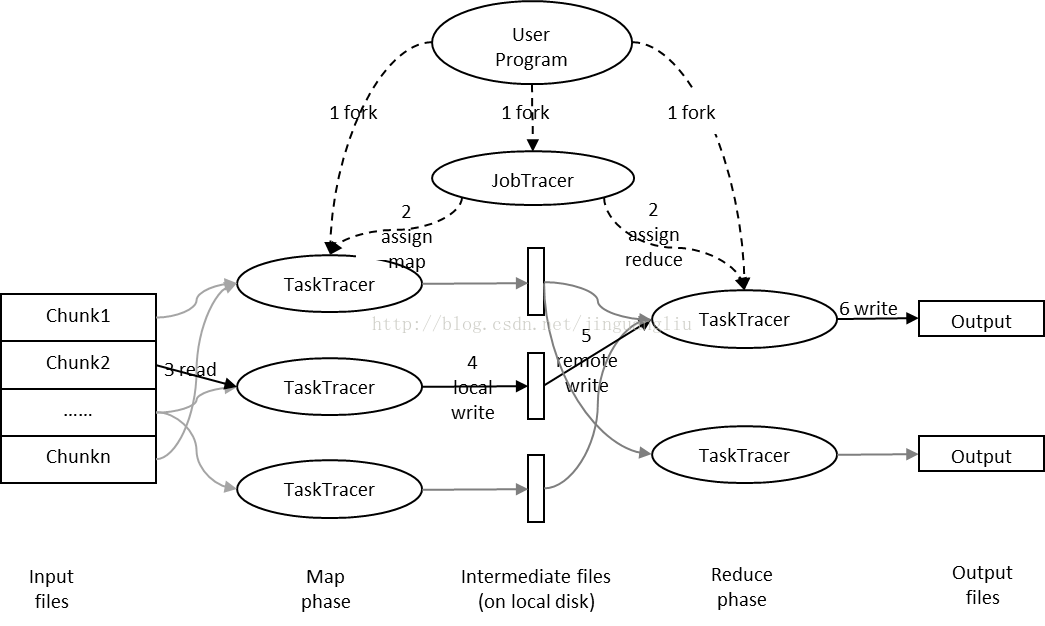
JobTracker
JobTracker守护进程是应用程序和Hadoop之间的纽带。一旦提交代码到集群上,JobTracker就会确定执行计划,包括决定处理哪些文件、为不同的任务分配节点以及监控所有任务的运行。如果任务失败,JobTracker将自动重启任务,但所分配的节点可能会不同,同时受到预定义的重试次数限制。
每个Hadoop集群只有一个JobTracker守护进程。它通常运行在服务器集群的主节点上。
TaskTracker
与存储的守护进程一样,计算的守护进程也遵循主/从架构:JobTracker作为主节点,监测MapReduce作业的整个执行过程,同时,TaskTracker管理各个任务在每个从节点上的执行情况。
每个TaskTracker负责执行由JobTracker配的单项任务。虽然每个从节点上仅有-个TaskTracker.但每个TaskTracker可以生成多个JVM (Java虚拟机)来并行地处理j午多map或reduce任务。
TaskTracker的-个职责是持续不断地与JobTracker通信。如果JobTracker在指定的时问内没有收到来自TaskTracker的“心跳”,它会假定TaskTracker已经崩溃了,进而重新提交相应的任务到集群中的其他节点中。
总结
为了给Hadoop集群有一个直观的印象,这里展示一个典型Hadoop集群的拓扑图。这是一个主从架构,其中NameNode和JobTracker为主端,DataNode和TaskNode为从端。
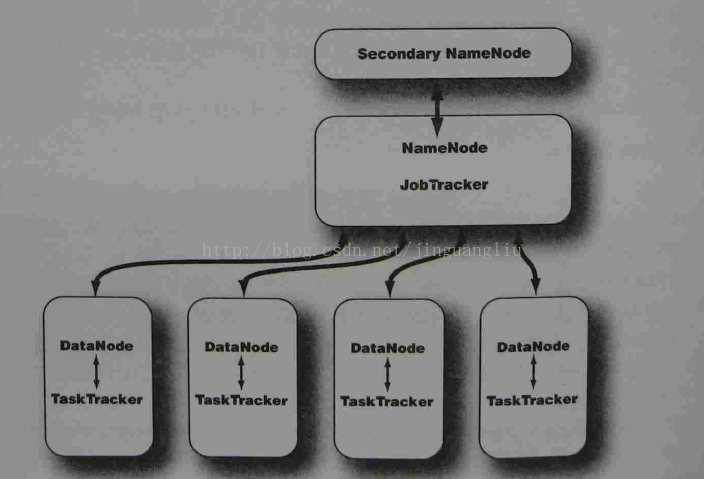
在上面的章节中,我们了解了Hadoop作为大数据处理框架,提供了数据存储的HDFS和数据处理的MapReduce的方案;数据存储方面,需要主从节点上的NameNode, Seconadary NameNode及DataNode守护进程的协作来处理数据的存储和读取;数据处理方面,需要主点上JobTracker分配和管理作业和TaskTracker执行作业来完成数据处理。
参考资料
1. Hadoop权威指南 第3版
2. Hadoop实战














 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









