







这里简单提一下字节顺序的问题,为了理解起来更快更清晰,我不说大小端的问题,只要各位看官记住分析套路先把gzip文件格式分析清楚,知道实际的二进制存储方式即可。后续章节分析压缩源码的时候会结合代码说明。
实例一:
原始文件的文件信息如下,
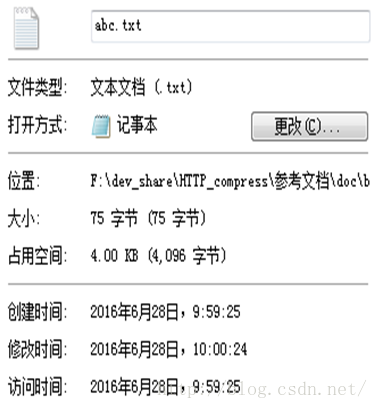

行 ,列
0000 0000h, 0~1,开始的两个字节是标识符1F8B;
0000 0000h, 2,CM (Compression Method),压缩方式,08表示deflate算法;
0000 0000h, 3,FLG (FLaGs),标志位,十六进制08,即二进制0000 1000,从右往左分别是bit0~bit7,现在bit3置位,对应FNAME,即该gzip头后面的扩展部分是带着原始文件名的;
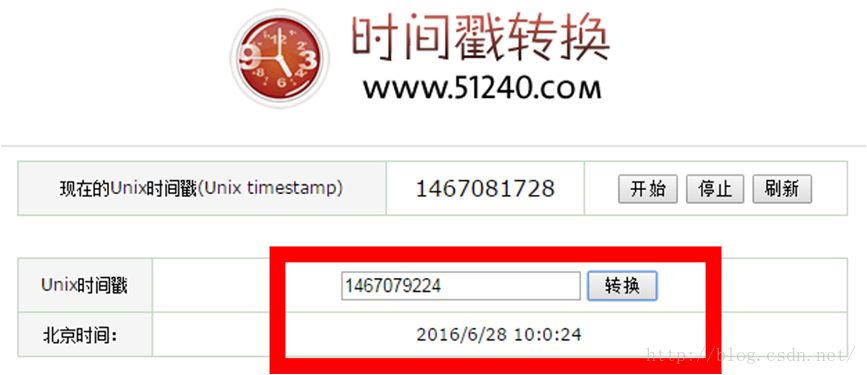
0000 0000h,4~7,这四个字节是时间,分别是十六进制“38 DA 71 57”,这是存储的顺序,我们转换成人们正常读取的顺序“57 71 DA 38”,将其转换成时间,先把5771DA38转换成十进制即1467079224,再使用在线时间戳转换工具得到如下图所示结果
0000 0000h, 8,XFL (eXtra FLags),十六进制02,这个地方我也有点糊涂,但我估计应该是用的XFL = 4 - compressorused fastest algorithm;
0000 0000h, 9,00,即0 - FAT filesystem (MS-DOS, OS/2,NT/Win32),我用的是win7,也是对应的。
0000 0000h, a~00000010h, 1,共8个字节,存储的是原始文件的文件名“abc.txt”,末尾还有个'\0'表示结束,从这里可以看出,这个文件名只是个文件名,没携带路径信息。从这里往后,就是实际的压缩数据信息了;
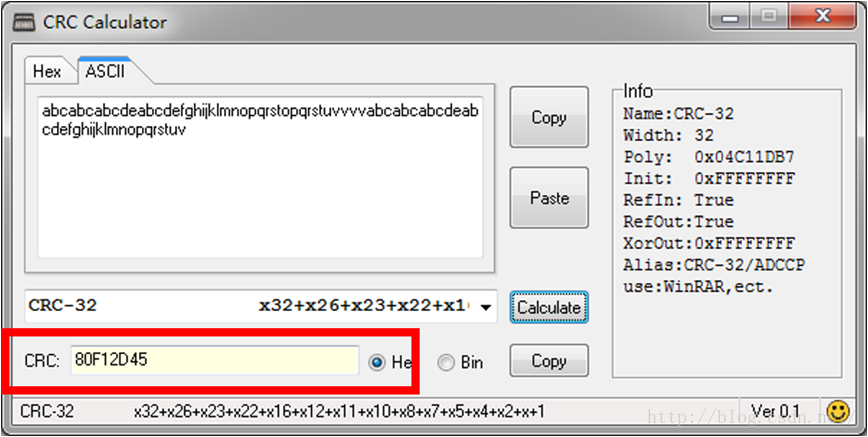
0000 0030h, b~e,这四个字节是CRC32校验码,分别是十六进制“45 2D F1 80”,这是存储的顺序,我们转换成人们正常读取的顺序“80 F1 2D 45”,原文件内容为“abcabcabcdeabcdefghijklmnopqrstopqrstuvvvvabcabcabcdeabcdefghijklmnopqrstuv”,使用CRC计算器算得结果如下图所示
0000 0030h, f~0000 0040h, 2,这四个字节是原始文件的大小,分别是十六进制“4B 00 00 00”,这是存储的顺序,我们转换成人们正常读取的顺序“00 00 00 4B”,即十进制的75,原始文件大小75字节,这也与文件信息对应。
到此,实例一完成。GZIP文件的基本分析方法就是这样,很简单,照着格式一步一步来就好。需要注意的是,这里对CRC32的分析、文件原始长度的分析以及相应工具的使用非常重要,后续章节要分析gzip源码,调试过程中难免出现异常,到时候就要依靠类似的推理方法以及工具。
实例二:
上面我们分析了针对文件的压缩,现在我们分析经过gzip压缩的HTTP应答报文。使用wireshark抓包,请求报文的HOST是“finance.sina.com.cn”,如下图所示,
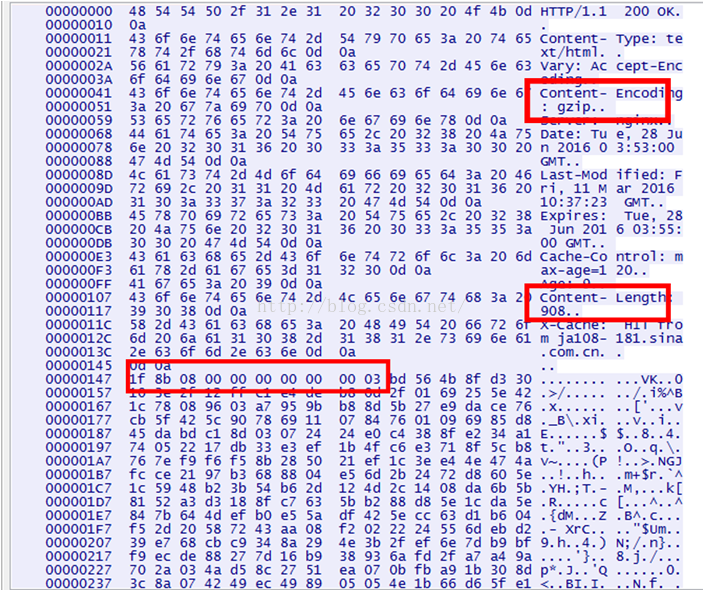
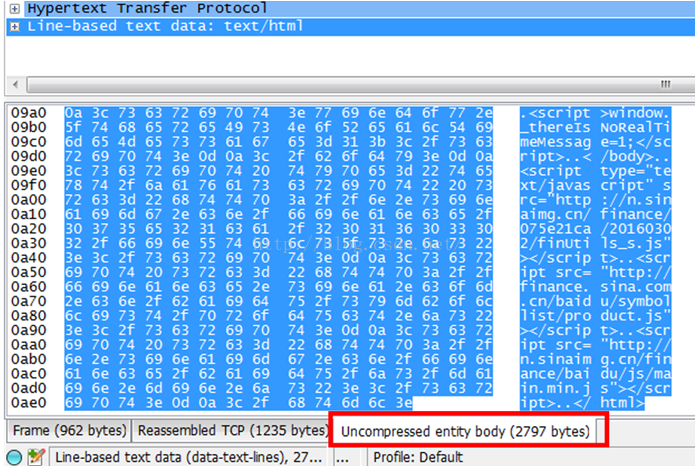
这是经过压缩的HTTP应答报文,HTTP数据长度908个字节(这是经过压缩之后的数据长度),图中固定长度的那10个字节已经被圈出来了,可以看出只有四个字节有效,具体含义参考实例一分析,这里不再赘述。我们看下图,

本章总结
本章我们分析了gzip文件格式各个字段的含义,并用两个实例进行实践,其中用到了一些工具,这些工具都极易获得,是我当初分析以及修改gzip1.2.4源码时,调试代码常用的工具。前文对RFC1952部分内容做了粗浅的翻译,有些直译有些意译,不足之处还请大家海涵,如果能在评论中指出,小僧感激不尽。另,gzip压缩不支持加密。














 2835
2835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









