









一直对python感兴趣,最近想玩玩爬虫,抓拉钩互联网职位招聘信息,然后做点统计什么的,废话不多说,开打开打。
作为程序猿,对什么boss直聘,拉勾网什么的招聘网站应该不陌生.....http://www.lagou.com/
运行环境:
1、win7 32bit
2、pycharm 4.0.4
3、python 3.4
4、google chrome
需要的插件
1、beautifulsoup(相关安装和使用可以到 官网(点击打开)查阅)
2、pymsql(安装可以到github下载安装https://github.com/PyMySQL/PyMySQL)
要抓一个网站的数据,当然要分析这个网站的网页代码是怎么写的,也就是你要的信息数据放在什么位置。
打开拉钩首页,按F12进入网页调试模式,可以发现拉钩把所有的职位都放在了id=sidebar标签下,每个职位都放在<a></a>标签下,所以很容易的就取到了所有职位
def grab_position(self):
"""
获取所有招聘职位
:return:
"""
html = self.my_opener.open(self.lagou_url)
soup = BeautifulSoup(html.read().decode(), "html.parser")
side_bar = soup.find(id="sidebar")
mainNavs = side_bar.find(class_="mainNavs")
menu_boxes = mainNavs.find_all(class_="menu_box")
all_positions = []
for menu_box in menu_boxes:
menu_sub = menu_box.find(class_="menu_sub") # 所有职位
all_a_tags = menu_sub.find_all("a") # 找出所有职位的a标签
for a_tag in all_a_tags:
all_positions.append(a_tag.contents[0])
return all_positions其实,可以看拉钩页面的源码,显示比较单一,然后看它的前端页面源码,可以看到,就是用了一个模板,然后发请求,根据返回的数据填入其中就可以了,你可以随意点一个职位链接,在看它的network,看加载页面的那个请求,发现了什么?
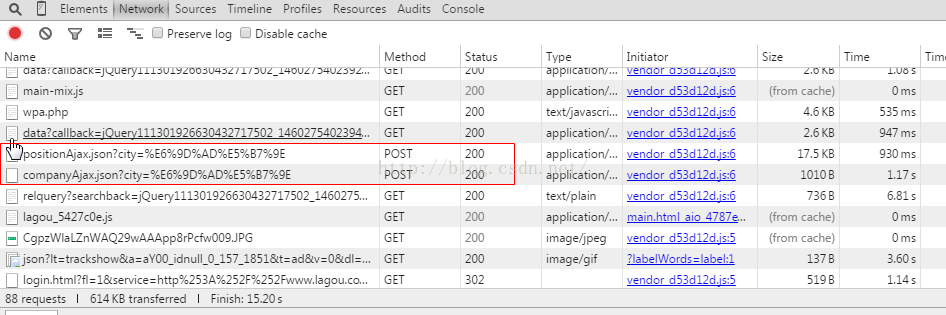
它就是用了一个positionAjax.json?city=*****的post请求,然后根据返回数据显示的
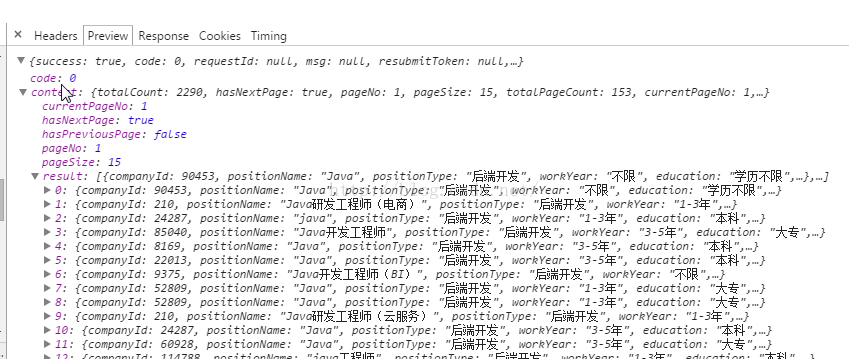
这说明什么?说明你要他的职位数据,你只要发请求,然后对上面返回的json数据提取就可以了!!不需要处理它的页面!
分析它不同职位的请求,你就会发现,它所需要的参数就是一个当前城市city,当前页号pn,和职位种类kd
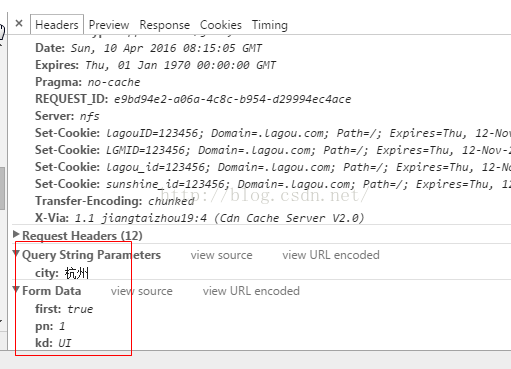
所以,只要获取到它所有的城市,所有的职位,然后依次发请求,就可以轻松的获取它所有的招聘信息了.....上面已经获取了所有职位,现在获取所有城市
打开
http://www.lagou.com/zhaopin/,看工作地点,就可以获取所有招聘城市

提取代码
<pre name="code" class="python">def grab_city(self):
"""
获取所有的城市
:return:
"""
op = self.my_opener.open(self.seed_url)
my_soup = BeautifulSoup(op.read().decode(), 'html.parser')
all_positions_html = my_soup.find(class_='more more-positions')
all_positions_hrefs = all_positions_html.find_all('a')
all_cities = []
for a_tag in all_positions_hrefs:
all_cities.append(a_tag.contents[0])
return all_citiespython的多线程使用比较简单,需要引入threading.Thread 和 queue(队列)
from threading import Thread
from time import sleep
from queue import Queue
# 开启多线程
def start_thread(self):
for i in range(self.thread_num):
curr_thread = Thread(target=self.working)
curr_thread.setDaemon(True)
curr_thread.start()处理函数working()
def working(self):
while True:
post_data = self.job_queue.get() # 从队列中取任务
self.grab(post_data) # 开始抓取
sleep(1)
self.job_queue.task_done() # 完成
def grab(self, args):
"""
根据参数args发请求,获取数据
:param args:请求参数字典{'first': '?', 'kd': ?, 'city': ?, 'pn': ?}
:return:
"""
url = self.base_request_url + urllib.parse.quote(args['city'])
url.encode(encoding='utf-8')
print(url + "--------"+str(args))
del args['city'] # 把city这个键删了,,,,不然,请求没有数据返回!!!
post_data = urllib.parse.urlencode(args).encode()
op = self.my_opener.open(url, post_data)
return_json = json.loads(op.read().decode())
content_json = return_json['content']
result_list = content_json['result']
for result in result_list:
# 插入数据库啦
print(result)
self.insert_into_database(result)
def grab_category(self, city, kd):
"""
分类抓取
:param city:当前城市
:param kd: 当前职位类型
:return:
"""
url = self.base_request_url+urllib.parse.quote(city)
url.encode(encoding='utf-8')
pn = 1 # 第一页单独处理吧,因为要获取当前类别下的总页数 postdata = urllib.parse.urlencode({'first': 'true', 'pn': pn, 'kd': kd}).encode()
pn += 1
op = self.my_opener.open(url, postdata)
return_json = json.loads(op.read().decode())
content_json = return_json['content']
total_page = content_json['totalPageCount'] # 获取当前类别的总页数
result_list = content_json['result'] # 取返回数据
for result in result_list:
self.insert_into_database(result) # 入库吧
while pn <= total_page:
# 一页有15条职位信息,一页作为一个任务塞进任务队列吧....
self.job_queue.put({'first': 'false', 'kd': kd, 'city': city, 'pn': pn})
pn += 1
self.job_queue.join() # 让进程尽情的发请求吧....def main():
my_crawler = LagouCrawler(db='position_info', max_count=30)
my_crawler.start()
if __name__ == '__main__':
main()上面给的都是代码片段,可能有些辅助方法没贴出来,这里就把所有的代码都放上来吧。
LagouCrawler类:
import urllib.request
import urllib.parse
import http.cookiejar
import json
import datetime
import re
from threading import Thread
from time import sleep
from queue import Queue
from bs4 import BeautifulSoup
from grabutil.mysqlconnection import Connection
class LagouCrawler:
def __init__(self, db, max_count=10, thread_num=10):
"""
:param db: 数据库名(mysql)
:param max_count: 批量插入数据库的条数
:param thread_num: 并行线程数
:return:
"""
self.position_default_url = "http://www.lagou.com/jobs/"
self.seed_url = 'http://www.lagou.com/zhaopin/'
self.lagou_url = "http://www.lagou.com/"
self.base_request_url = "http://www.lagou.com/jobs/positionAjax.json?city="
self.to_add_infos = []
self.max_count = max_count # 批量插入的记录数
self.thread_num = thread_num # 线程数
self.job_queue = Queue() # 任务队列
self.my_opener = self.make_my_opener()
self.query = "insert into position_info.position(city, companyId, companyLabelList, companyName, companyShortName, " \
"companySize, education, financeStage, industryField, jobNature, leaderName, positionAdvantage," \
"positionFirstType, positionId, positionName, positionType, pvScore, workYear, salary_min, salary_max," \
"homepage, positionDescibe)" \
" values (%s, %s, %s, %s,%s, %s, %s, %s,%s, %s, %s, %s,%s, %s, %s,%s, %s, %s, %s, %s, %s, %s)"
self.mysqlconn = Connection(db=db)
self.start_thread() # 开启多线程
# 开启多线程
def start_thread(self):
for i in range(self.thread_num):
curr_thread = Thread(target=self.working)
curr_thread.setDaemon(True)
curr_thread.start()
def make_my_opener(self):
"""
模拟浏览器发送请求
:return:
"""
head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
cj = http.cookiejar.CookieJar() # cookie
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def change_salary(self, salary):
"""
:param salary: 处理拉钩的薪资
:return:
"""
salaries = re.findall("\d+", salary)
if salaries.__len__() == 0:
return 0, 0
elif salaries.__len__() == 1:
return int(salaries[0])*1000, int(salaries[0])*1000
else:
return int(salaries[0])*1000, int(salaries[1])*1000
def position_detail(self, position_id):
"""
处理职位详情
:param position_id:
:return:
"""
position_url = self.position_default_url + str(position_id)+".html"
print(position_url)
op = self.my_opener.open(position_url, timeout=1000)
detail_soup = BeautifulSoup(op.read().decode(), 'html.parser')
job_company = detail_soup.find(class_='job_company')
job_detail = detail_soup.find(id='job_detail')
job_req = job_detail.find(class_='job_bt')
c_feature = job_company.find(class_='c_feature')
homePage = c_feature.find('a')
homeUrl = homePage.get('href')
return job_req, homeUrl
def grab_city(self):
"""
获取所有的城市
:return:
"""
op = self.my_opener.open(self.seed_url)
my_soup = BeautifulSoup(op.read().decode(), 'html.parser')
all_positions_html = my_soup.find(class_='more more-positions')
all_positions_hrefs = all_positions_html.find_all('a')
all_cities = []
for a_tag in all_positions_hrefs:
all_cities.append(a_tag.contents[0])
return all_cities
def grab_position(self):
"""
获取所有招聘职位
:return:
"""
html = self.my_opener.open(self.lagou_url)
soup = BeautifulSoup(html.read().decode(), "html.parser")
side_bar = soup.find(id="sidebar")
mainNavs = side_bar.find(class_="mainNavs")
menu_boxes = mainNavs.find_all(class_="menu_box")
all_positions = []
for menu_box in menu_boxes:
menu_sub = menu_box.find(class_="menu_sub") # 所有职位
all_a_tags = menu_sub.find_all("a") # 找出所有职位的a标签
for a_tag in all_a_tags:
all_positions.append(a_tag.contents[0])
return all_positions
def insert_into_database(self, result):
"""
插入数据
:param result:待插入的抓取信息
:return:
"""
city = result['city']
companyId = result['companyId']
companyLabelList = result['companyLabelList']
companyLabel = ''
for lable in companyLabelList:
companyLabel += lable+" "
companyName = result['companyName']
companyShortName = result['companyShortName']
companySize = result['companySize']
education = result['education']
financeStage = result['financeStage']
industryField = result['industryField']
jobNature = result['jobNature']
leaderName = result['leaderName']
positionAdvantage = result['positionAdvantage']
positionFirstType = result['positionFirstType']
positionId = result['positionId']
job_req, homeUrl = self.position_detail(positionId) # 获取信息
positionName = result['positionName']
positionType = result['positionType']
pvScore = result['pvScore']
salary = result['salary']
salaryMin, salaryMax = self.change_salary(salary)
workYear = result['workYear']
'''
print(city, companyId, companyLabel, companyName, companyShortName, companySize,
education, financeStage, industryField, jobNature, leaderName, positionAdvantage,
positionFirstType, positionId, positionName, positionType, pvScore, salary, workYear)
'''
self.to_add_infos.append((city, str(companyId), companyLabel, companyName, companyShortName, companySize,
education, financeStage, industryField, jobNature, leaderName, positionAdvantage,
positionFirstType, positionId, positionName, positionType, pvScore, workYear,
salaryMin, salaryMax, homeUrl, str(job_req)))
if self.to_add_infos.__len__() >= self.max_count: # 批量插入
self.mysqlconn.execute_many(sql=self.query, args=self.to_add_infos)
self.to_add_infos.clear() # 清空数据
def working(self):
while True:
post_data = self.job_queue.get() # 取任务
self.grab(post_data) # 抓取任务
sleep(1)
self.job_queue.task_done()
def grab(self, args):
"""
根据参数args发请求,获取数据
:param args:请求参数字典{'first': '?', 'kd': ?, 'city': ?, 'pn': ?}
:return:
"""
url = self.base_request_url + urllib.parse.quote(args['city'])
url.encode(encoding='utf-8')
print(url + "--------"+str(args))
del args['city'] # 把city这个键删了,,,,不然,请求没有数据返回!!!
post_data = urllib.parse.urlencode(args).encode()
op = self.my_opener.open(url, post_data)
return_json = json.loads(op.read().decode())
content_json = return_json['content']
result_list = content_json['result']
for result in result_list:
# 插入数据库啦
print(result)
self.insert_into_database(result)
def grab_category(self, city, kd):
"""
分类抓取
:param city:当前城市
:param kd: 当前职位类型
:return:
"""
url = self.base_request_url+urllib.parse.quote(city)
url.encode(encoding='utf-8')
pn = 1
postdata = urllib.parse.urlencode({'first': 'true', 'pn': pn, 'kd': kd}).encode()
pn += 1
op = self.my_opener.open(url, postdata)
return_json = json.loads(op.read().decode())
content_json = return_json['content']
total_page = content_json['totalPageCount']
result_list = content_json['result']
for result in result_list:
self.insert_into_database(result)
while pn <= total_page:
# 一个任务处理一页
self.job_queue.put({'first': 'false', 'kd': kd, 'city': city, 'pn': pn})
pn += 1
self.job_queue.join()
print('successful')
def start(self):
all_cities = self.grab_city()
all_positions = self.grab_position()
grabed_cities_file = open("d:\\grabed_cities.txt", 'a')
for i in range(1, 2):
start_time = datetime.datetime.now()
for j in range(1, int(all_positions.__len__()/2)):
self.grab_category(city=all_cities[i], kd=all_positions[j])
end_time = datetime.datetime.now()
grabed_cities_file.write(all_cities[i]+"----职位:"+all_positions[j]+"----耗时:"
+ str((end_time-start_time).seconds)+"s\n")
end_time = datetime.datetime.now()
print((end_time-start_time).seconds)
grabed_cities_file.write(all_cities[i]+"----耗时:"+str((end_time-start_time).seconds)+"s\n")
self.mysqlconn.close()
grabed_cities_file.close()
print("----------finish--------------")mysql Connection类:
import pymysql
class Connection:
def __init__(self, db, host=u'localhost', port=3306, user=u'root', passwd=u'', charset=u'utf8'):
self.connection = pymysql.connect(db=db, host=host, port=port, user=user, passwd=passwd, charset=charset)
self.cur = self.connection.cursor()
def execute_single(self, sql, args):
self.cur.execute(sql, args)
self.connection.commit()
def execute_many(self, sql, args):
self.cur.executemany(sql, args)
self.connection.commit()
def close(self):
self.cur.close()
self.connection.close()未完待续....后面统计的之后在写,现在还没做....














 2125
2125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









