







V. PHONETIC DECISION TREES
Our goals in building the phonetic decision tree code were to make it efficient for arbitrary context sizes (i.e. we avoided enumerating contexts), and also to make it general enough to support a wide range of approaches. The conventional approach is, in each HMM-state of each monophone, to have a decision tree that asks questions about, say, the left and right phones. In our framework, the decision-tree roots can be shared among the phones and among the states of the phones, and questions can be asked about any phone in the context window, and about the HMM state. Phonetic questions can be supplied based on linguistic knowledge, but in our recipes the questions are generated automatically based on a tree-clustering of the phones. Questions about things like phonetic stress (if marked in the dictionary) and word start/end information are supported via an extended phone set; in this case we share the decision-tree roots among the different versions of the same phone.
注:
1.建立phonetic decision tree code的目的是有效的应对任意的上下文以及对广泛的方法有通用的支持
2.conventional approach: 每个单音素的HMM模型都有一个决策树
3.In paper approach:每个决策树的根节点被众多的音素或者是音素的状态共享
VI. LANGUAGE MODELING
Since Kaldi uses an FST-based framework, it is possible, in principle, to use any language model that can be represented as an FST. We provide tools for converting LMs in the standard ARPA format to FSTs. In our recipes, we have used the IRSTLM toolkit for purposes like LM pruning. For building LMs from raw text, users may use the IRSTLM toolkit, for which we provide installation help, or a more fully-featured toolkit such as SRILM.
注:
1.Kaldi: an FST-based framework
2.IRSTLM toolkit: LM pruning
VII. CREATING DECODING GRAPHS
All our training and decoding algorithms use Weighted Finite State Transducers (WFSTs). In the conventional recipe [14], the input symbols on the decoding graph cor-respond to context-dependent states (in our toolkit, these symbols are numeric and we call them pdf-ids). However, because we allow different phones to share the same pdf-ids, we would have a number of problems with this approach, including not being able to determinize the FSTs, and not having sufficient information from the Viterbi path through an FST to work out the phone sequence or to train the transition probabilities. In order to fix these problems, we put on the input of the FSTs a slightly more fine-grained integer identifier that we call a “transition-id”, that encodes the pdf-id, the phone it is a member of, and the arc (transition) within the topology specification for that phone. There is a one-to-one mapping between the “transition-ids” and the transition-probability pa-rameters in the model: we decided make transitions as fine-grained as we could without increasing the size of the decoding graph.
注:
1.Problems: determinize the FSTs & not having sufficient information from the Viterbi path through an FST to work
out the phone sequence or to train the transition probabilities
2.Fix: we put on the input of the FSTs a slightly more fine-grained integer identifier that we call a “transition-id”
Our decoding-graph construction process is based on the recipe described in [14]; however, there are a number of
differences. One important one relates to the way we handle “weight-pushing”, which is the operation that is supposed to ensure that the FST is stochastic. “Stochastic” means that the weights in the FST sum to one in the appropriate sense, for each state (like a properly normalized HMM). Weight pushing may fail or may lead to bad pruning behavior if the FST representing the grammar or language model (G) is not stochastic, e.g. for backoff language models. Our approach is to avoid weight-pushing altogether, but to ensure that each stage of graph creation “preserves stochasticity” in an appropriate sense. Informally, what this means is that the “non-sum-to-one-ness” (the failure to sum to one) will never get worse than what was originally present in G.
VIII. DECODERS
We have several decoders, from simple to highly optimized; more will be added to handle things like on-the-fly language model rescoring and lattice generation. By “decoder” we mean a C++ class that implements the core decoding algorithm. The decoders do not require a particular type of acoustic model: they need an object satisfying a very simple interface with a function that provides some kind of acoustic model score for a particular (input-symbol and frame).
<span style="font-size:18px;">class DecodableInterface {
public:
virtual float LogLikelihood(int frame, int index) = 0;
virtual bool IsLastFrame(int frame) = 0;
virtual int NumIndices() = 0;
virtual ˜DecodableInterface() {}
};</span>decoder and one acoustic-model type. Multi-pass decoding is implemented at the script level.
IX. EXPERIMENTS
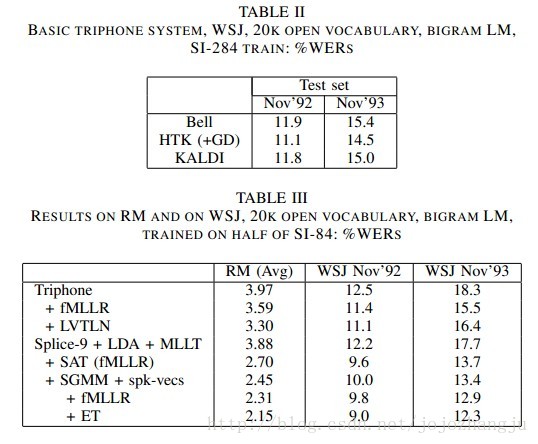
We report experimental results on the Resource Manage-ment (RM) corpus and on Wall Street Journal. The results re-ported here correspond to version 1.0 of Kaldi; the scripts that correspond to these experiments may be found inegs/rm/s1 and egs/wsj/s1.
A. Comparison with previously published results
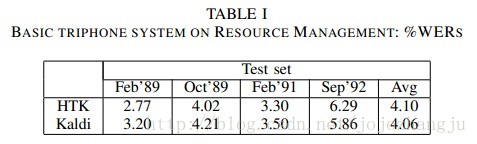
Table I shows the results of a context-dependent triphone system with mixture-of-Gaussian densities; the HTK baseline numbers are taken from [15] and the systems use essentially the same algorithms. The features are MFCCs with per-speaker cepstral mean subtraction. The language model is the word-pair bigram language model supplied with the RM corpus. The WERs are essentially the same. Decoding time was about 0.13×RT, measured on an Intel Xeon CPU at 2.27GHz. The system identifier for the Kaldi results is tri3c.
X. CONCLUSIONS
We described the design of Kaldi, a free and open-source speech recognition toolkit. The toolkit currently supports mod-eling of context-dependent phones of arbitrary context lengths, and all commonly used techniques that can be estimated using maximum likelihood. It also supports the recently proposed SGMMs. Development of Kaldi is continuing and we are working on using large language models in the FST frame-work, lattice generation and discriminative training.
REFERENCES
[1] S. Young, G. Evermann, M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey, V. Valtchev, and P. Woodland,The HTK Book (for version 3.4). Cambridge University Engineering Department, 2009.
[2] A. Lee, T. Kawahara, and K. Shikano, “Julius – an open source real-time large vocabulary recognition engine,” in EUROSPEECH, 2001, pp.1691–1694.
[3] W. Walker, P. Lamere, P. Kwok, B. Raj, R. Singh, E. Gouvea, P. Wolf,and J. Woelfel, “Sphinx-4: A flexible open source framework for speech recognition,” Sun Microsystems Inc., Technical Report SML1 TR2004-0811, 2004.
[4] D. Rybach, C. Gollan, G. Heigold, B. Hoffmeister, J. L¨o¨ of, R. Schl¨ uter,and H. Ney, “The RWTH Aachen University Open Source Speech Recognition System,” inINTERSPEECH, 2009, pp. 2111–2114.
[5] C. Allauzen, M. Riley, J. Schalkwyk, W. Skut, and M. Mohri, “OpenFst: a general and efficient weighted finite-state transducer library,” inProc. CIAA, 2007.
[6] R. Gopinath, “Maximum likelihood modeling with Gaussian distribu-tions for classification,” in Proc. IEEE ICASSP, vol. 2, 1998, pp. 661–664.
[7] M. J. F. Gales, “Semi-tied covariance matrices for hidden Markov models,”IEEE Trans. Speech and Audio Proc., vol. 7, no. 3, pp. 272–281, May 1999.
[8] C. J. Leggetter and P. C. Woodland, “Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models,”Computer Speech and Language, vol. 9, no. 2, pp. 171–185,
1995.
[9] M. J. F. Gales, “Maximum likelihood linear transformations for HMM-based speech recognition,” Computer Speech and Language, vol. 12, no. 2, pp. 75–98, April 1998.
[10] ——, “The generation and use of regression class trees for MLLR adaptation,” Cambridge University Engineering Department, Technical Report CUED/F-INFENG/TR.263, August 1996.
[11] D. Y. Kim, S. Umesh, M. J. F. Gales, T. Hain, and P. C. Woodland, “Using VTLN for broadcast news transcription,” inProc. ICSLP, 2004, pp. 1953–1956.
[12] D. Povey, G. Zweig, and A. Acero, “The Exponential Transform as a generic substitute for VTLN,” inIEEE ASRU, 2011.
[13] D. Povey, L. Burgetet al., “The subspace Gaussian mixture model— A structured model for speech recognition,”Computer Speech & Lan-guage, vol. 25, no. 2, pp. 404–439, April 2011.
[14] M. Mohri, F. Pereira, and M. Riley, “Weighted finite-state transducers in speech recognition,” Computer Speech and Language, vol. 20, no. 1, pp. 69–88, 2002.
[15] D. Povey and P. C. Woodland, “Frame discrimination training for HMMs for large vocabulary speech recognition,” inProc. IEEE ICASSP, vol. 1,1999, pp. 333–336.
[16] W. Reichl and W. Chou, “Robust decision tree state tying for continuous speech recognition,” IEEE Transactions on Speech and Audio Process-ing, vol. 8, no. 5, pp. 555–566, September 2000.
[17] P. C. Woodland, J. J. Odell, V. Valtchev, and S. J. Young, “Large vocabulary continuous speech recognition using HTK,” inProc. IEEE ICASSP, vol. 2, 1994, pp. II/125–II/128.














 7179
7179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









