







概述
对网络包处理中,提升性能的关键在于CPU Cache的利用情况。因此,从体系结构角度深刻理解Cache的原理,对写出高性能数据包处理程序是必要的理论基础。这篇文档写于2007年,有点久远,但是其描述的原理仍然适用现在的主流CPU。我将从程序员的角度总结该文章的要点。
CPU Caches
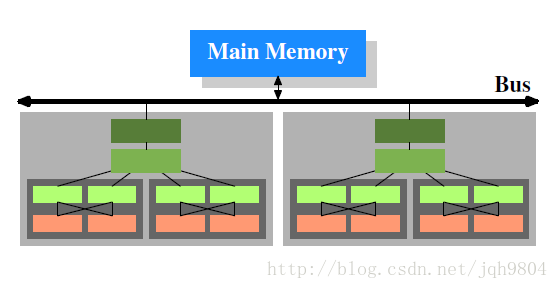
- L1 cache分为指令cache和数据cache,缓存不同内容。L2和L3不再区分,指令和数据共享。
- 数据流向可以从CPU直达内存绕过cache,不必严格按照图中所示。
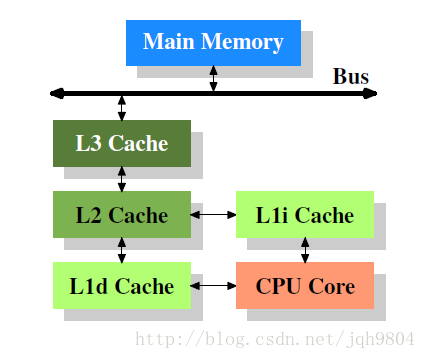
1. 多个处理器之间所有资源(寄存器,L1,L2,L3 cache)独立。
2. 单个处理器中多个核心之间,寄存器和L1 cache独立,其它资源共享。
3. 单个处理器单个核心的多个超线程之间,部分寄存器独立,部分寄存器共享,其它资源都共享。
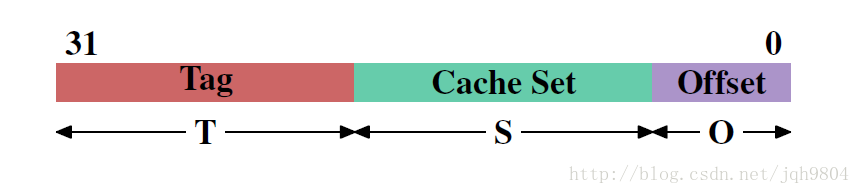
以32位CPU中地址为例:T用于组内tag标记,S用于定位组位置,O代表偏移定位具体字节。
- 对内存写操作,需要先把对应的数据读取到cache中,一次读取一个完整的cache line,然后修改cache line中的数据,标记该line为dirty。当cache line写入内存后,dirty标记清空。
- 往L1 cache中装载数据时,如果对应组没有空位了,则需要淘汰一个cache line,被淘汰的数据写入L2 cache,如果L2也需要淘汰数据,则从L2淘汰的数据写入L3,以此类推,最终写入内存中。Intel的CPU中,L3 cache含有L2 cache的副本,L2 cache含有L1 cache的副本。AMD和VIA的CPU则没有包含关系。
SMP系统中,各个CPU在任何时候看到的内存模型都是一样的,但是它们又有自己独立的cache,cache之间可能数据不一致,为了协调各个cache称为cache coherency。CPU不能直接访问其它CPU的cache,但是CPU可以监听总线知道其它CPU对哪个cache line进行了操作。以此发展出了MSEI协议。其核心目标为:1. dirty数据只允许出现在一个cache中 2. 干净的数据可以出现在多个CPU cache中
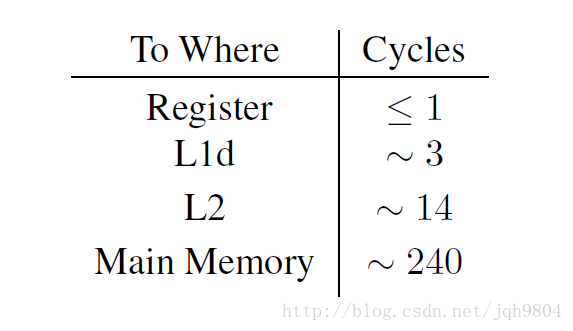
下图是intel Pentium M的数据
- 实际运行中的访问数据耗时比表格中小,因为现代流水线技术,可以掩盖很多访问延时。其它体系结构树中会有详细描述。
- 写操作并不需要等待数据完全写入内存才能返回,而是可以立即返回执行下一条指令。
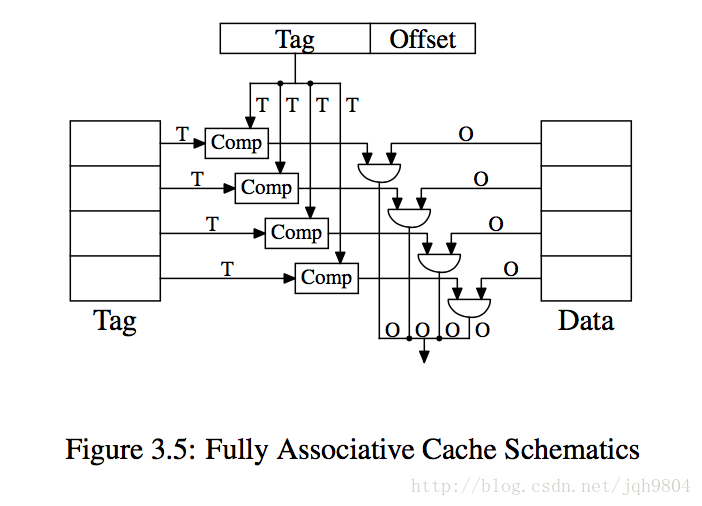
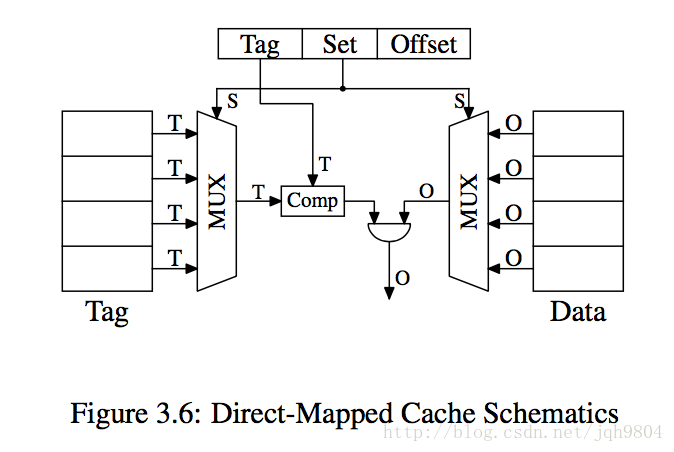
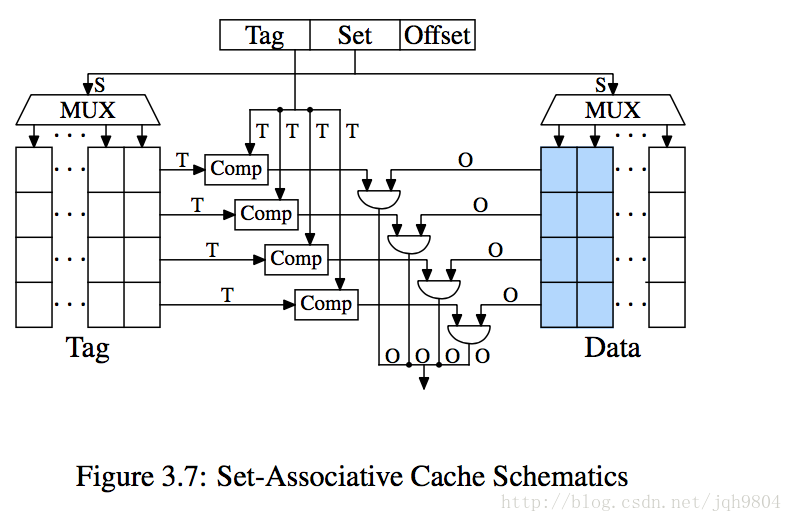
cache的最小单位是一个cache line。如果只有一个组,包含了所有cache line则称为全相联cache,如果有多个组,每个组只含有一个cache line,则称为直接映射cache。如果有多个组,每个组含有n > 1个cache line,则称为n路组相联cache。
Comp对比器每次可以比较T bit数据,为了效率必须并行对比所有cache line的tag。全相联cache中,Tag比较大,意味着对比器需要迭代对比多次,同时Cache line数量多,意味着Comp对比器的数量要求多,CPU晶体管资源消耗很多。
全相联Cache只适用于小的cache,比如TLB。
直接映射cache的Comp只需要一个,Tag也比较短,对比会很快。唯一复杂的地方在于MUX,它要根据组号选择cache line,消耗的CPU晶体管规模为O(log N),应该采用的是二分查找。
直接映射cache的实际效率跟使用内存地址分布关联很大,容易出现cache使用不平衡,降低效率。
组相联cache避免了前面两种缺点。L1 cache一般使用8路组相联,L2 cache最多24路组相联。
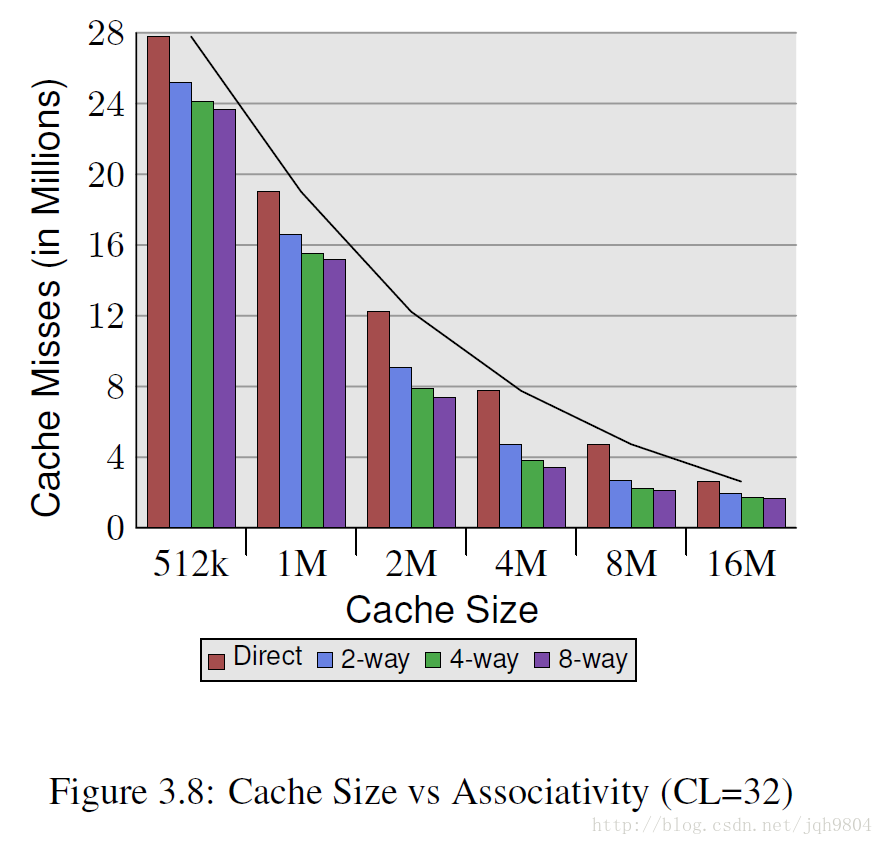
- Cache line为32字节,数据集大概5.6M。简单测试可以发现多路组相联会比直接映射cache缺失率少很多。但是在硬件单线程情况下,组相联大于8路,收益会越来越小。新的超线程CPU会共享L1 cache,相当于把L1组相连度平分了。多核心cpu会共享L2 cache,也相当于把L2组相连度平分了。随着核心数目增加,增加L2相连度或者增加新的L3 cache是有必要的。
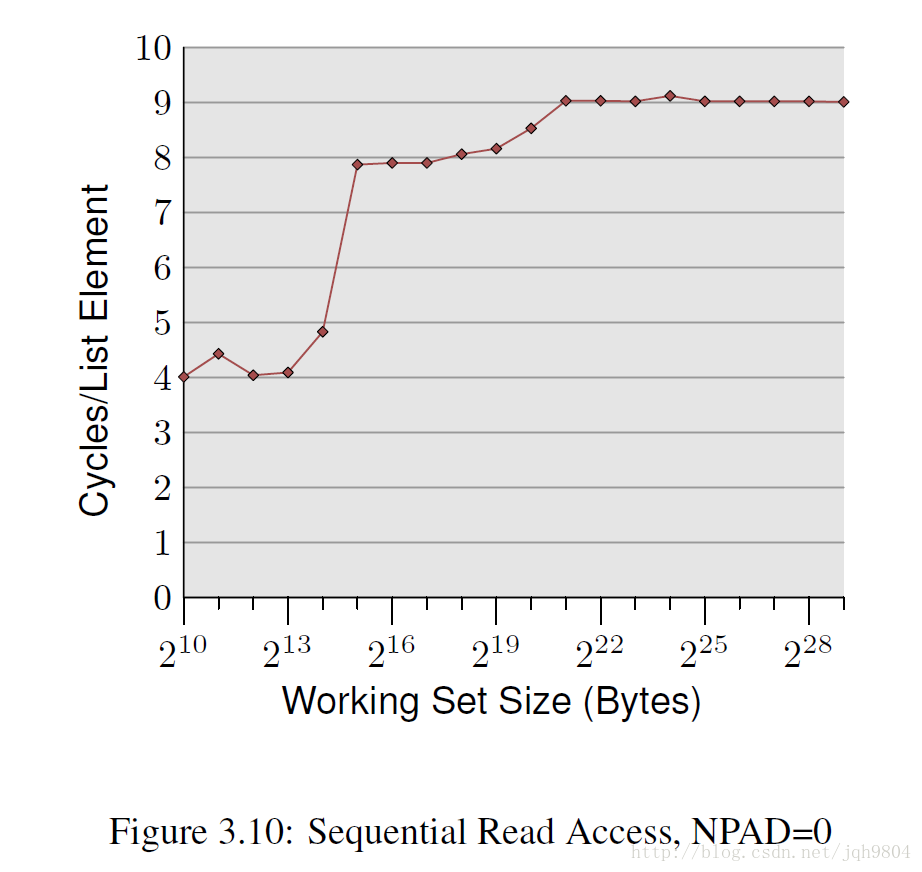
接下来的实验将以对如下数据结构读写测试,NPAD值会设置不同的值。Pentium 4 64位CPU,L1 16kb,L2 1MB。
struct l {
struct l *n;
long int pad[NPAD];
};
当数据集小于L1大小,数据集大于L1小于L2,数据集大于L2时,出现了顺序读取消耗周期稳定区。注意的是,当数据集大于L1小于L2,数据集大于L2时,消耗的周期比上文提到的访存时间明显少,这是由于CPU在顺序读取时硬件自动触发了prefetch(L2->L1,内存->L2),大幅提升了性能。
单个数据结构的大小直接影响cpu硬件自动触发prefetch效果,越大的数据结构将不会触发prefetch,那么消耗的时钟周期越多。
- 当数据集少于L1大小时,4个测试消耗时钟周期差不多。
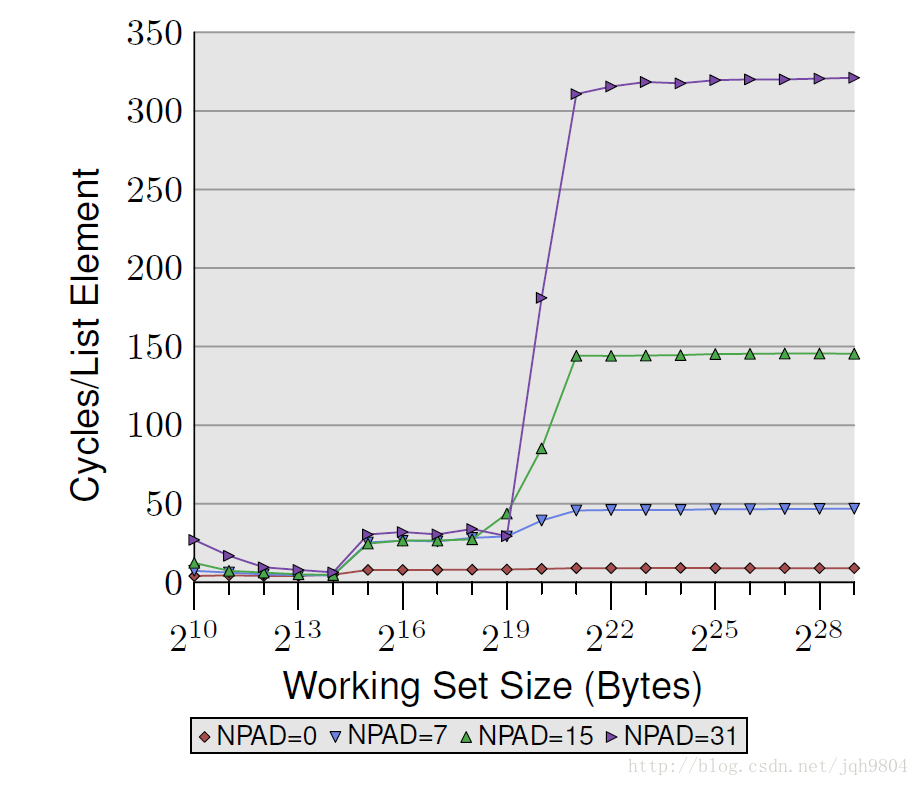
- 当数据集在L1和L2大小之间时,后三个测试消耗时钟周期明显增加,L2->L1预取关闭,耗时大概28个始终周期,但是他们彼此消耗差不多。
当数据集大于L2大小后,消耗差距急剧拉大。NPAD=7情况下,内存->L2预取开始生效,此时消耗时钟周期不到50。NPAD=15和NPAD=31情况下,内存->L2预取关闭,外加TLB失效率提高,导致性能下降明显。
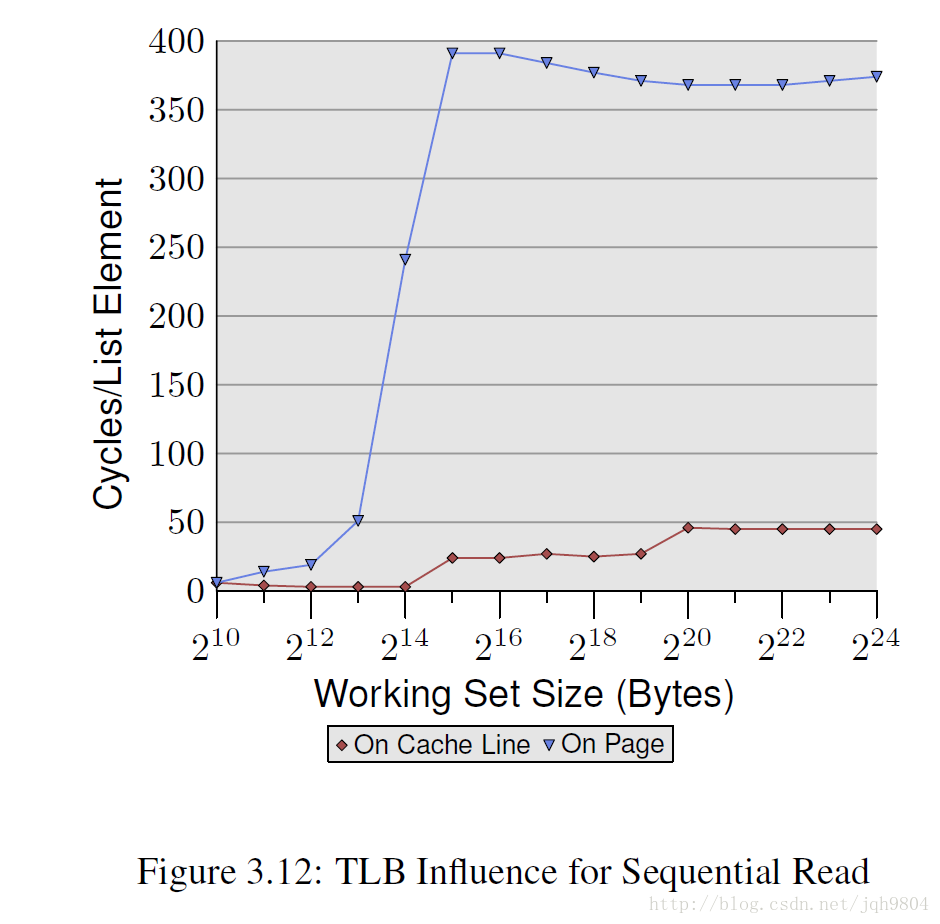
NPAD=7情况下,把数据紧凑排列,和每个数据占用一个页面对比。可见,当TLB miss增加时,导致性能急剧下降。
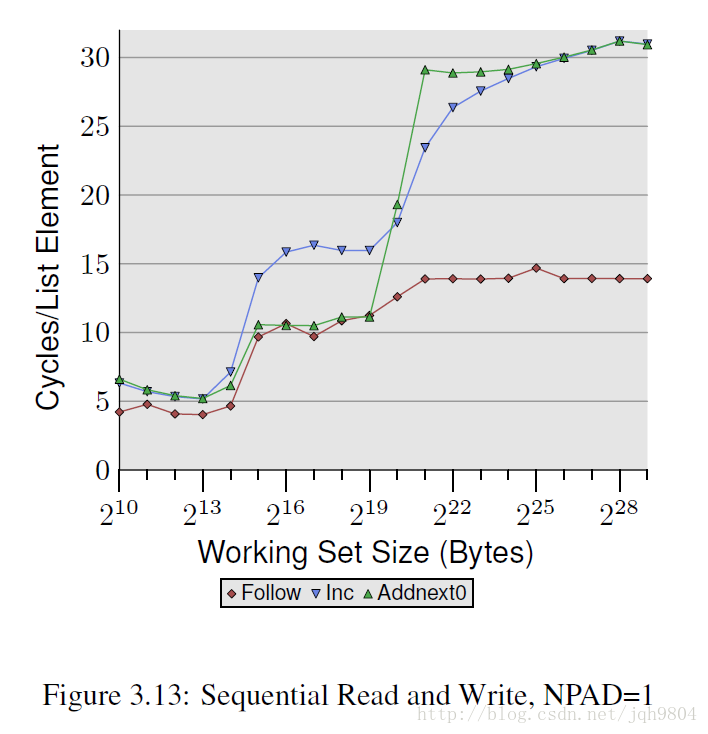
- Inc操作将自身翻倍写回。Addnext0操作将下一个数据加到自身然后写回。
- 当工作集在L1~L2 cache大小之间时,Addnext0性能高于Inc,我估计由于编译器自动做了预取优化,先发起预取读取下一个元素,再读取当前元素,当做加法时,下一个元素已经在L2中了。不过工作集大于L2后没有效果,因为预取从内存从读取,延时太大,当做加法时,下一个元素还没预取到。
- 单线程随机读操作中,随着工作集的增加,消耗的时钟周期急剧增加,达到450个左右,大大超出内存的200-300的读取周期,这是因为TLB miss导致。同时,随着工作集的增加,没有出现像顺序访问那样的平台期,而是一直不断增加时钟消耗,因为硬件预取无法生效。
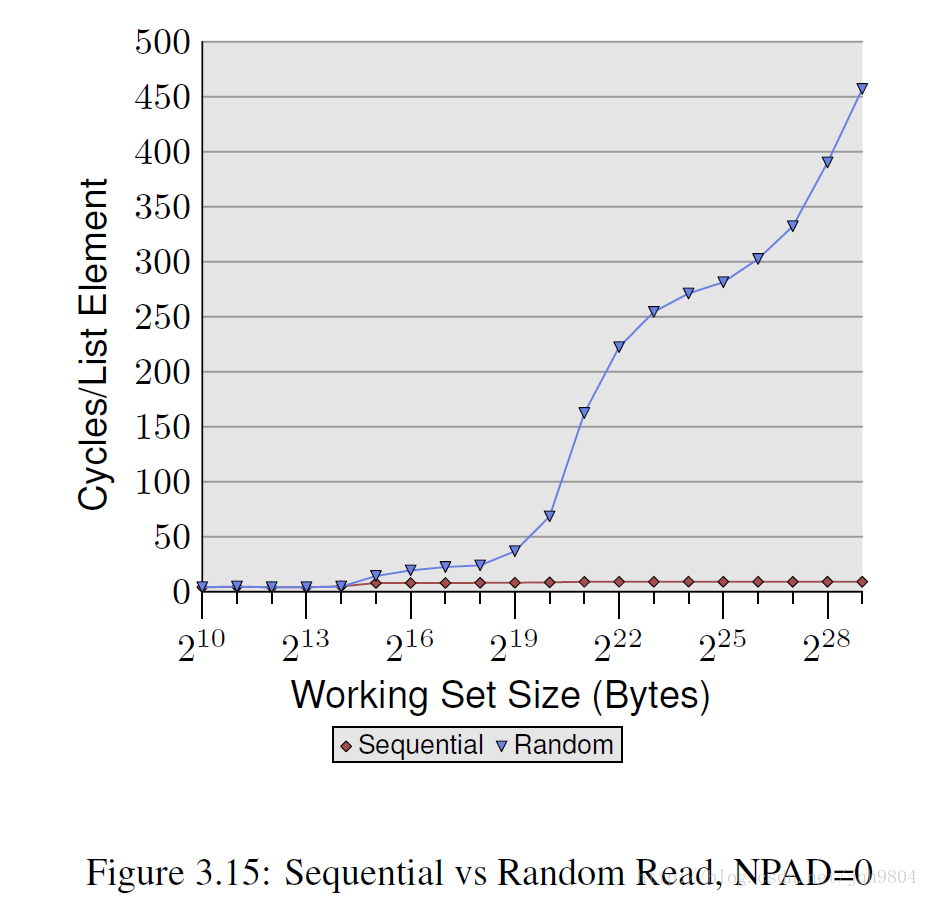
- 当工作集大于L2 cache大小后,L2 miss率大幅提高,然后轻微下降,又继续提高。
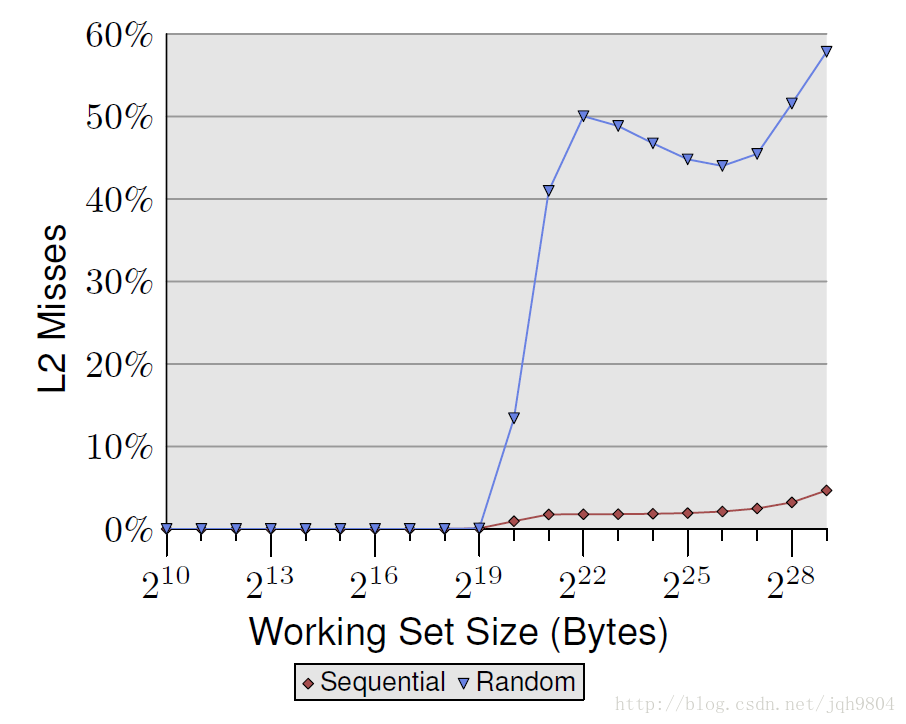
- 本实验每个数据元素大小为64字节,这样硬件预取将不怎么起作用,对性能的影响将关注在TLB。
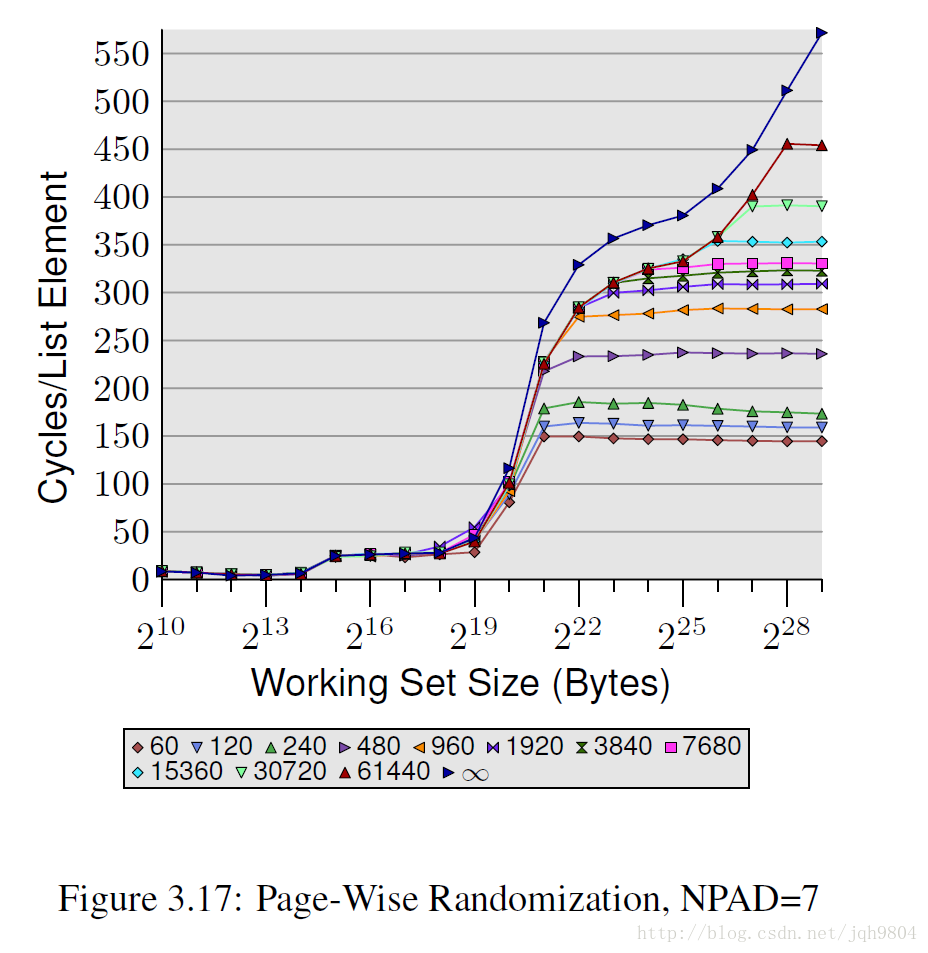
- 将工作集划分为block。每个block内随机访问,遍历完一个block后再遍历下一个block中元素。这样就人为的控制住了随机性。随机性越大,TLB miss就越高,访问性能就越差。
- 多处理器或者多核心处理器,只要cache不是共享的,就会有多线程同步问题。这些cache之间不能随意的传输数据,因为处理器之间带宽有限,他们在该情况下需要传输:当一个处理器上线程请求的cache line在另外一个处理器上,并且是dirty状态。
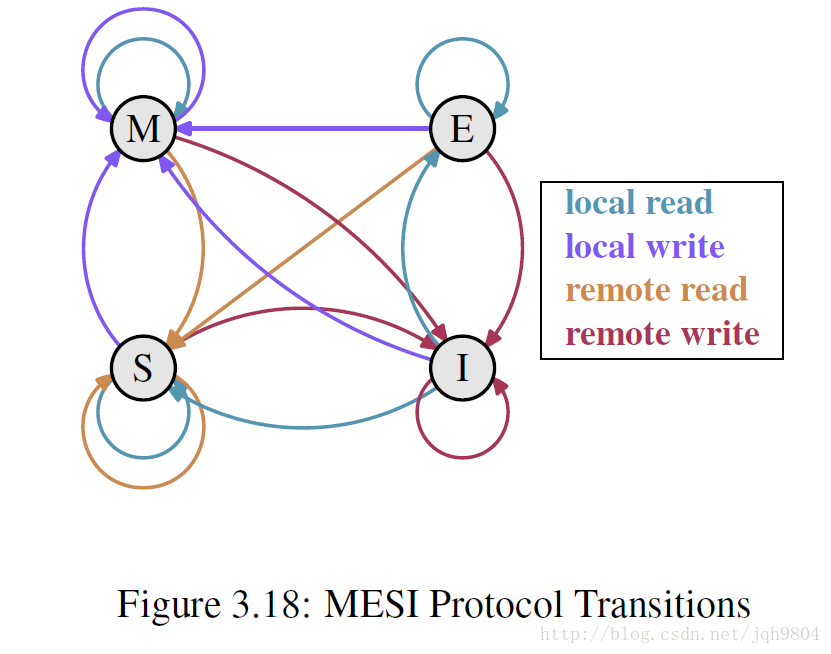
- MESI协议四种状态:Modified 修改了,唯一一份。Exclusive 未修改,唯一一份。Shared 未修改,有多份。Invalid cache line已作废。处理器可以监听到其他处理器的cache操作。
- RFO操作:cache同步中最耗时的是RFO操作。当第一个处理器读取了一行cache line,第二个处理器要对该cache line写操作时,第一个处理器发送该cache line到第二个处理器,并标记第一个处理的cache line为无效。
- 多线程之间同步操作就是典型的RFO情况。要尽量减少该操作。
- 多处理器中,FSB往往是瓶颈之一,多核心将分享统一的总线带宽。
- 多线程顺序读取操作与单线程顺序读取对比,此时cache line为S状态,之间没有RFO。但是仍然出现了多线程时性能下降情况,其原因只可能是内存总线瓶颈所致。
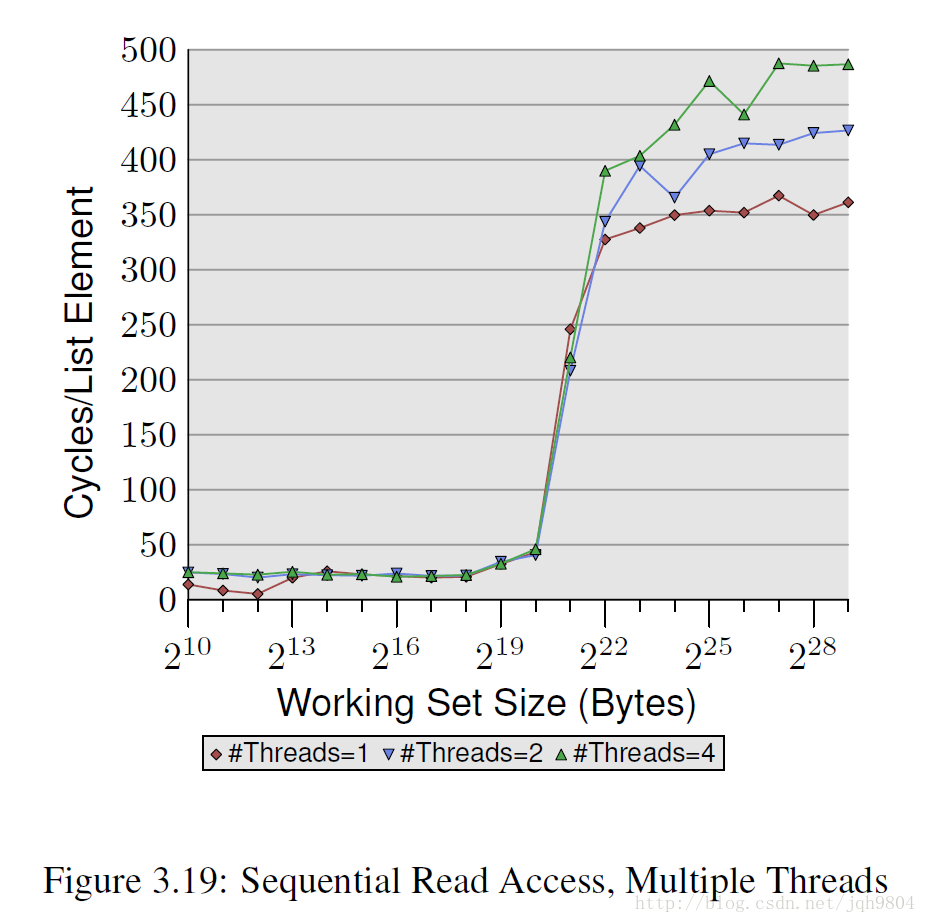
- 多线程顺序写操作与单线程顺序写对比
- 工作集小于L1大小时,多线程情况性能也会比单线程差,因为L1 cache各个核心独立,多线程时总线带宽将不够。
- 当工作集大于L1小于L2大小时,多线程和单线程性能接近,很奇怪此时带宽又够了,博主不解,这需要硬件知识才能解答。
- 当工作集大于L2时,会有很多访问内存操作,此时四线程情况下性能会出现急剧下降。这是由于预取操作和写会操作超过了总线承载量。
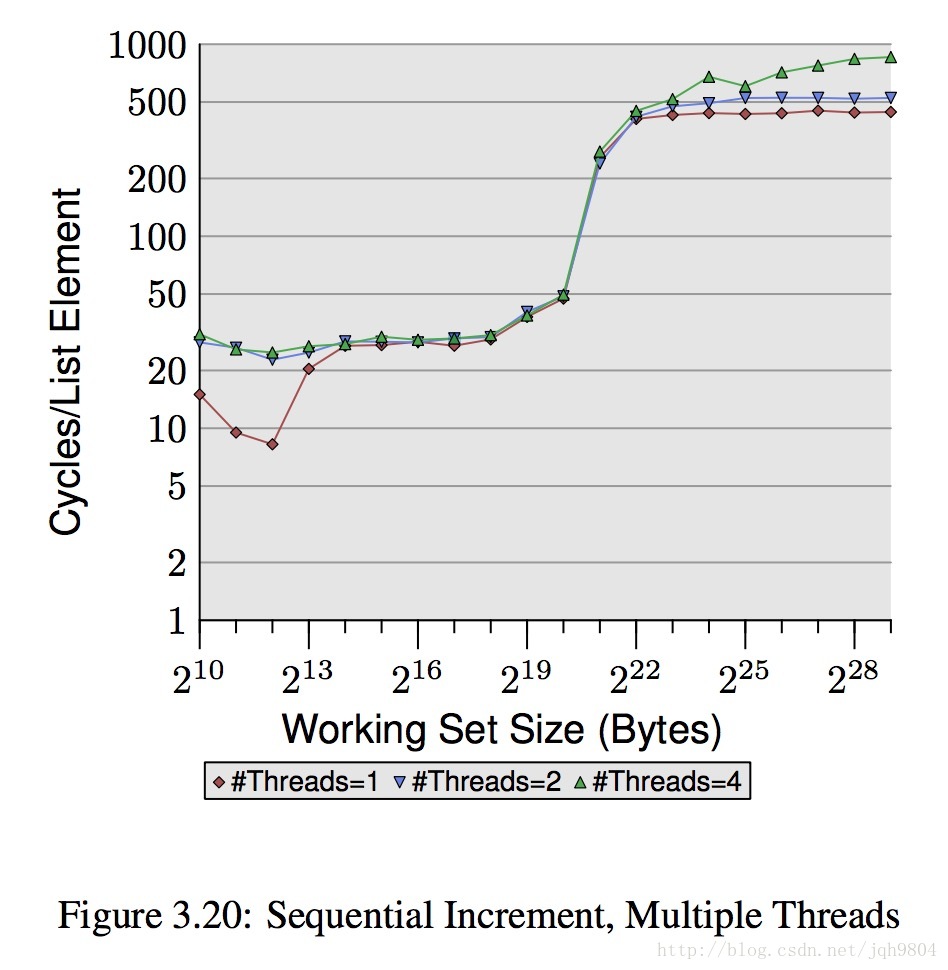
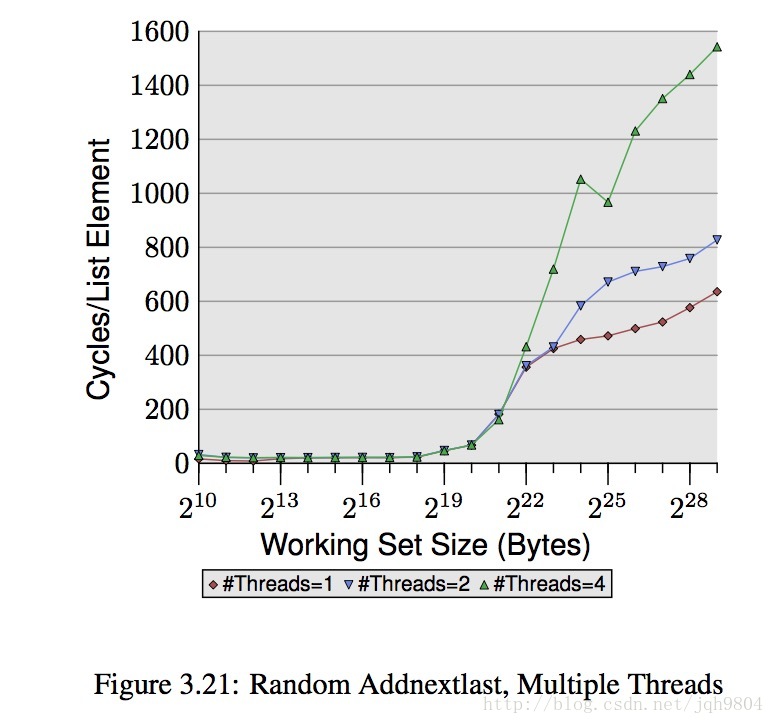
- 随机写操作时,数据集大于L2大小,更多的线程性能下降比顺序写更高。
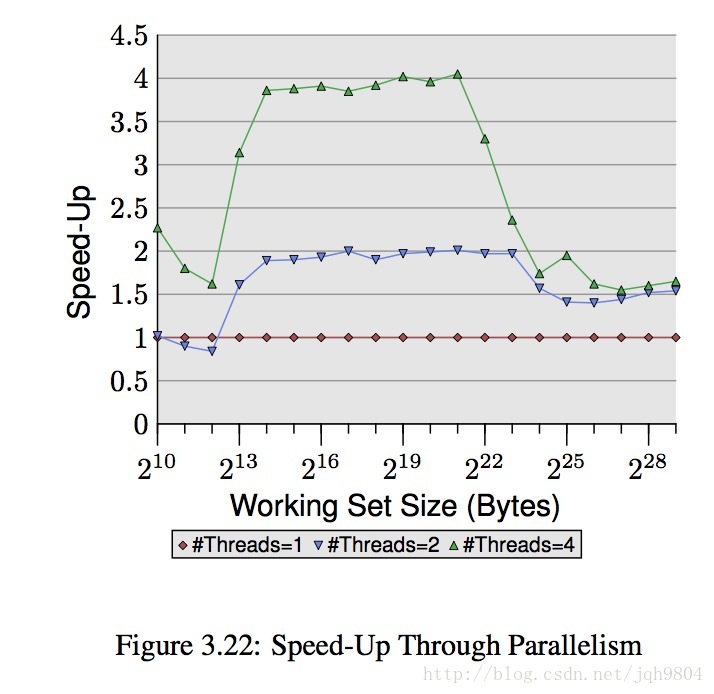
- 随机写多线程整体加速情况,可见当数据集大于L2大小时,4线程性能跟2线程性能很接近了。数据集在L1和L2之间时,加速倍数接近理论值。
- Hyper-Threads CPU中,多个超线程独占一套寄存器,但是共享cache和ALU。其提速原理是,当一个线程处于访存等待时,调度另外一个线程来执行。这意味着,当线程本身的cache hit率越低,整体提速效果越好。反之就没什么效果,加上超线程固有开销,还不如考虑在主板上关闭该特性。
- L1 cache强制使用的是虚拟地址,因为如果使用物理地址,则MMU地址转换代价相对于L1访问速度是很高的。L2 cache一般使用物理地址。
- 指令cache的优化主要是编译器的工作,人工可干预的地方很少,只能尽可能减少代码量,以及帮助代码预测。
(未完待续)














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









