







目录
pixel-wise,patch-wise,image-wise
batch | epoches|dacay |iteration
global averagepooling&average pooling
pixel-wise,patch-wise,image-wise
pixel-wise,patch-wise,image-wise的含义如下
pixel-wise字面上的理解一样,一张图片是由一个个pixel组成的,这个是图像的基本单位,像素级别的
image-wise图像级别,比如一张图片的标签是狗,是对整个图片的标注
patch-wise介于像素级别和图像级别的区域,也就是块,每个patch都是由好多个pixel组成的
Soft-NMS和NMS
https://www.cnblogs.com/makefile/p/nms.html
http://www.sohu.com/a/135469270_642762
batch | epoches|dacay |iteration
参考google group:
https://groups.google.com/forum/#!searchin/darknet/subdivisions|sort:relevance/darknet/WgFJDkVc7z4/V56hc5w_AwAJ
https://groups.google.com/forum/#!searchin/darknet/subdivisions|sort:relevance/darknet/qZp5P0I4iGA/OexXrkK7DwAJ
batch sizes
https://www.zhihu.com/question/32673260
batch: how many images load at once;
epoches
一个epoch是指把所有训练数据完整的过一遍;
一次epoch=所有训练数据forward+backward后更新参数的过程。
一次iteration=[batch size]个训练数据forward+backward后更新参数过程
dacay
iterations(迭代)
每一次迭代都是一次权重更新,每一次权重更新需要batch size个数据进行Forward运算得到损失函数,再BP算法更新参数
one epoch = numbers of iterations = N = 训练样本的数量/batch size
subdivisions:
how many times to break image batch into smaller pieces;
batch / subdivisions:how many images are loaded and feed to network.
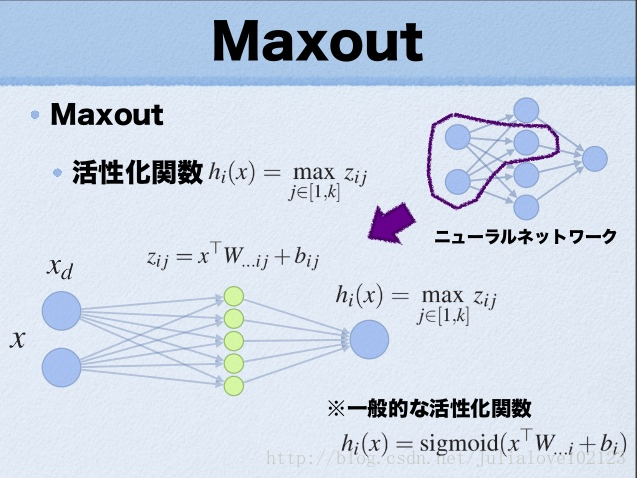
Maxout
maxout:http://arxiv.org/pdf/1302.4389v4.pdf
NIN:http://arxiv.org/abs/1312.4400
Maxout
maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start-of-art的识别率。
从论文中可以看出,maxout其实一种激发函数形式。通常情况下,如果激发函数采用sigmoid函数的话,在前向传播过程中,隐含层节点的输出表达式为:
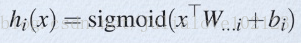
其中W一般是2维的,这里表示取出的是第i列,下标i前的省略号表示对应第i列中的所有行。
如果是maxout激发函数,则其隐含层节点的输出表达式为:
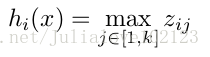
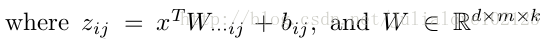
这里的W是3维的,尺寸为d m k,
d表示输入层节点的个数,
m表示隐含层节点的个数,
k表示每个隐含层节点对应了k个”隐隐含层”节点,
这k个“隐隐含层”节点都是线性输出的,而maxout的每个节点就是取这k个“隐隐含层”节点输出值中最大的那个值。因为激发函数中有了max操作,所以整个maxout网络也是一种非线性的变换。
因此当我们看到常规结构的神经网络时,如果它使用了maxout激发,则我们头脑中应该自动将这个”隐隐含层”节点加入。
maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。最直观的解释就是任意的凸函数都可以由分段线性函数以任意精度拟合,而maxout又是取k个隐隐含层节点的最大值,这些”隐隐含层”节点也是线性的,所以在不同的取值范围下,最大值也可以看做是分段线性的(分段的个数与k值有关)。论文中的图1如下(它表达的意思就是可以拟合任意凸函数,当然也包括了ReLU了)
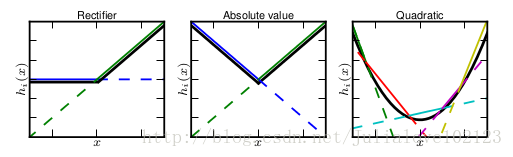
作者从数学的角度上也证明了这个结论,即只需2个maxout节点就可以拟合任意的凸函数了(相减),前提是“隐隐含层”节点的个数可以任意多,如下图所示
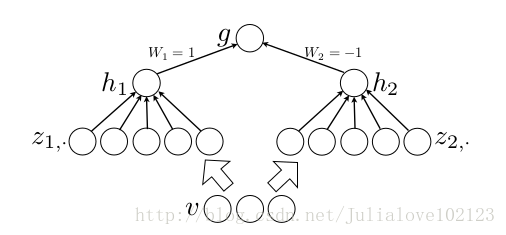
maxout的一个假设是潜在概念的实例是位于输入空间的凸集中。
参考
maxout和NIN具体内容可以参考:Deep learning:四十五(maxout简单理解)
Network In Network
各用一句话概括
- 常规卷积层: conv→relu
- maxout: several conv(full)→max
- NIN: serveral conv(full)→relu→conv(1x1)→relu
具体一点
- 常规卷积层:conv→relu
conv: conv_out=∑(x·w)
relu: y=max(0, conv_out)
maxout:several conv(full)→max
several conv (full): conv_out1 = x·w_1, conv_out2 = x·w_2, …
max: y = max(conv_out1, conv_out2, …)
- NIN: conv→relu→conv(1x1)→relu
several conv (full): conv_out1 = x·w_1, conv_out2 = x·w_2, …
relu: relu_out1 = max(0, conv_out1), relu_out2 = max(0, conv_out2), …
conv(1x1): conv_1x1_out = [relu_out1, relu_out2, …]·w_1x1
relu: y = max(0, conv_1x1_out)
例子
假设现在有一个3x3的输入,用一个9维的向量x代表,卷积核大小也是3x3,也9维的向量w代表。
- 对于常规卷积层,直接x和w求卷积,然后relu一下就好了。
- maxout,有k个的3x3的w(这里的k是自由设定的),分别卷积得到k个1x1的输出,然后对这k个输入求最大值
- NIN,有k个3x3的w(这里的k也是自由设定的),分别卷积得到k个1x1的输出,然后对它们都进行relu,然后再次对它们进行卷积,结果再relu。(这个过程,等效于一个小型的全连接网络
总结
总的来说,maxout和NIN都是对传统conv+relu的改进。
maxout想表明它能够拟合任何凸函数,也就能够拟合任何的激活函数(默认了激活函数都是凸的)
NIN想表明它不仅能够拟合任何凸函数,而且能够拟合任何函数,因为它本质上可以说是一个小型的全连接神经网络
global averagepooling&average pooling
理解《一》:
比如:“最后一个卷积层输出10个feature map”,“而average pooling是对每个feature map分别求平均,输出10个feature map”,这个理解是没问题的,“global average pooling是对10个feature map求平均值,输出一个feature map”,这个理解就不太对了。论文里面有这么一句话
Instead of adding fully connected layers on top of the feature maps, we take the average of each feature map, and the resulting vector is fed directly into the softmax layer.
其实就是表示global average pooling是对每个feature map内部取平均,每个feature map变成一个值(因为kernel的大小设置成和feature map的相同),10个feature map就变成一个10维的向量,然后直接输入到softmax中。
另外也可以参考一下颜老师组在ILSVRC2014报告中的ppt,(里面有这么一个图,可以很明显看出来是对每个feature map内部取平均。

有兴趣还可以看看caffe中NIN的proto文件,global average pooling层使用的就是普通的pooling层,只是类型改成了ave。
理解《二》:
global average pooling 与 average pooling 的差别就在 "global" 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。
因此,global average pooling 的最后输出结果仍然是 10 个 feature map,而不是一个,只不过每个 feature map 只剩下一个像素罢了。这个像素就是求得的平均值。
官方 prototxt 文件 里写了。网络进行到最后一个 average pooling 层的时候,feature map 就剩下了 10 个,每个大小是 8 * 8。顺其自然地作者就把 pooling 窗口设成了 8 个像素,意会为 global average pooling 。可见,global average pooling 就是窗口放大到整个 feature map 的 average pooling 。
交叉熵的定义:
在信息论中,交叉熵是表示两个概率分布p,q,其中p表示真实分布,q表示非真实分布,在相同的一组事件中,其中,用非真实分布q来表示某个事件发生所需要的平均比特数。从这个定义中,我们很难理解交叉熵的定义。下面举个例子来描述一下:
假设现在有一个样本集中两个概率分布p,q,其中p为真实分布,q为非真实分布。假如,按照真实分布p来衡量识别一个样本所需要的编码长度的期望为: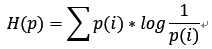
但是,如果采用错误的分布q来表示来自真实分布p的平均编码长度,则应该是
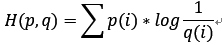
此时就将H(p,q)称之为交叉熵。交叉熵的计算方式如下:
对于离散变量采用以下的方式计算:
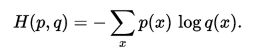
对于连续变量采用以下的方式计算:
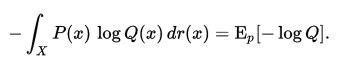
实际上,交叉熵是衡量两个概率分布p,q之间的相似性。这可以在特征工程中,用来衡量变量的重要性。
2、交叉熵的应用:
(1)在特征工程中,可以用来衡量两个随机变量之间的相似度
(2)语言模型中(NLP),由于真实的分布p是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。其计算方式如下:
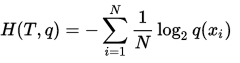
其中,N是表示的测试集的大小,q(x)表示的是事件x在训练集中的概率(在nlp中就是关键词在训练语料中的概率)。
(3)在逻辑回归中的应用。
由于交叉熵是衡量两个分布之间的相似度,在逻辑回归中,首先数据集真实的分布是p,通过逻辑回归模型预测出来的结果对应的分布是q,此时交叉熵在这里就是衡量预测结果q与真实结果p之间的差异程度,称之为交叉熵损失函数。具体如下:
假设,对应两分类的逻辑回归模型logistic regression来说,他的结果有两个0或者1,在给定预测向量x,通过logistics regression回归函数g(z)=1/(1+e-z),则真实结果y=1,对应预测结果y'=g(wx);真实结果y=0,对应预测结果y'=1-g(wx);以上就是通过g(wx)和1-g(wx)来描述原数据集0-1分布。根据交叉熵的定义可知:
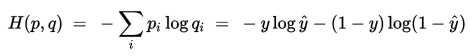
上式是针对测试集一个样本得到的交叉熵。若测试集有N个样本,对应的交叉熵损失函数表示方式如下:
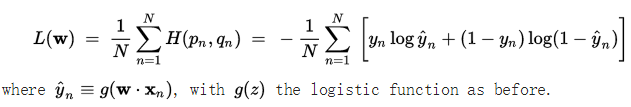














 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









