 KVM、QEMU与libvirt详解
KVM、QEMU与libvirt详解





 本文详细介绍了KVM、QEMU和libvirt在虚拟化中的作用和架构。KVM作为内核的一部分,提供了虚拟机管理能力;QEMU则负责硬件模拟,通过与KVM的配合提供高性能的虚拟化环境;libvirt则作为一个统一的管理接口,简化了对不同虚拟化技术的管理。
本文详细介绍了KVM、QEMU和libvirt在虚拟化中的作用和架构。KVM作为内核的一部分,提供了虚拟机管理能力;QEMU则负责硬件模拟,通过与KVM的配合提供高性能的虚拟化环境;libvirt则作为一个统一的管理接口,简化了对不同虚拟化技术的管理。
注:本文内容均来自网络,我只是在此做了一些摘抄和整理的工作,来源均有注明。
0、虚拟化
虚拟化简介
我们首先简要介绍一下虚拟化,阐述 QEMU 的搭建背景。
本文中介绍的虚拟化实际上指的是平台虚拟化。在物理硬件上,控制程序可能是主机操作系统或管理程序(见图 1)。在某些情况下,主机操作系统就是管理程序。来宾操作系统位于管理程序中。在某些情况下,来宾操作系统与控制程序使用相同的 CPU,而在另外一些情况下,则可能不同(比如 PowerPC 来宾操作系统在 x86 硬件上运行)。
图 1. 平台虚拟化的基本架构

您可以通过多种方法实现虚拟化,但是最常见的有三种。第一种称为本地虚拟化(或全虚拟化)。在这种虚拟化中,管理程序实现基本的隔离元素,将物理硬件与来宾操作系统相分离。这种技术首次出现于 1966 年 IBM® CP-40 虚拟机/虚拟内存操作系统中,另外 VMware ESX Server 也使用了此技术。
另一种流行的虚拟化技术称为半虚拟化。在半虚拟化中,控制程序实现了管理程序的应用程序接口(API),它将由来宾操作系统使用。Xen 和 Linux Kernel-based Virtual Machine (KVM) 都使用了半虚拟化技术。
第三种有用的技术称为仿真。仿真,顾名思义,通过模拟完整的硬件环境来虚拟化来宾平台。仿真可通过多种方法实现,即使在同一个解决方案中也是如此。通过仿真实现虚拟化的技术有 QEMU 和 Bochs。
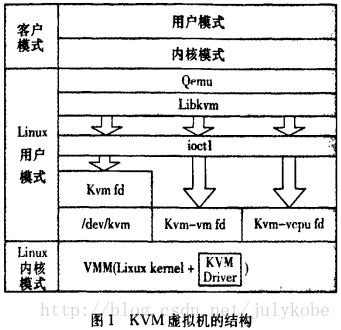
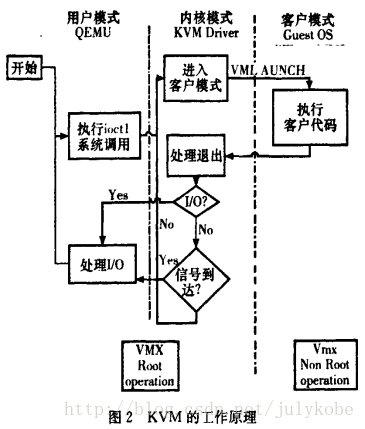
1、KVM

2、QEMU
- 模拟(emulator)
- 虚拟化(virtualizer)
虚拟化:就是在host OS上运行guest OS的指令,并为guest OS提供虚拟的CPU、RAM、IO和外围设备。
ioctl(KVM_RUN)switch (exit_reason) {case KVM_EXIT_IO: /* ... */case KVM_EXIT_HLT: /* ... */}
109 1673 1 1 May04 ? 00:26:24 /usr/bin/qemu-system-x86_64 -name instance-00000002 -S -machine pc-i440fx-trusty,accel=tcg,usb=off -m 2048 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid f3fdf038-ffad-4d66-a1a9-4cd2b83021c8 -smbios type=1,manufacturer=OpenStack Foundation,product=OpenStack Nova,version=2014.2,serial=564d2353-c165-6238-8f82-bfdb977e31fe,uuid=f3fdf038-ffad-4d66-a1a9-4cd2b83021c8 -no-user-config -nodefaults -chardev socket,id=charmonitor,path=/var/lib/libvirt/qemu/instance-00000002.monitor,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc -no-shutdown -boot strict=on -device piix3-usb-uhci,id=usb,bus=pci.0,addr=0x1.0x2 -drive file=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none -device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1 -drive file=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/disk.config,if=none,id=drive-ide0-1-1,readonly=on,format=raw,cache=none -device ide-cd,bus=ide.1,unit=1,drive=drive-ide0-1-1,id=ide0-1-1 -netdev tap,fd=26,id=hostnet0 -device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:db:86:d4,bus=pci.0,addr=0x3 -chardev file,id=charserial0,path=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/console.log -device isa-serial,chardev=charserial0,id=serial0 -chardev pty,id=charserial1 -device isa-serial,chardev=charserial1,id=serial1 -vnc 127.0.0.1:1 -k en-us -device cirrus-vga,id=video0,bus=pci.0,addr=0x2 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5QEMU 支持两种操作模式:用户模式仿真和系统模式仿真。用户模式仿真 允许一个 CPU 构建的进程在另一个 CPU 上执行(执行主机 CPU 指令的动态翻译并相应地转换 Linux 系统调用)。系统模式仿真 允许对整个系统进行仿真,包括处理器和配套的外围设备。
在 x86 主机系统上仿真 x86 代码时,使用 QEMU 加速器 可以实现近似本地的性能。这让我们能够直接在主机 CPU 上执行仿真代码(在 Linux 上通过 kernel 模块执行)。
但是从技术角度看,QEMU 的有趣之处在于其快速、可移植的动态翻译程序。动态翻译程序 允许在运行时将用于目标(来宾)CPU 的指令转换为用于主机 CPU,从而实现仿真。这可以通过一种强制方法实现(将指令从一个 CPU 映射到另一个 CPU),但是情况并非总是这样简单,在某些情况下,根据所翻译的架构,可能需要使用多个指令或行为更改。
QEMU 实现动态翻译的方法是,首先将目标指令转换为微操作。这些微操作是一些编译成对象的 C 代码。然后构建核心翻译程序。它将目标指令映射到微操作以进行动态翻译。这不仅可产生高效率,而且还可以移植。
QEMU 的动态翻译程序还缓存了翻译后的代码块,使翻译程序的内存开销最小化。当初次使用目标代码块时,翻译该块并将其存储为翻译后的代码块。 QEMU 将最近使用的翻译后的代码块缓存在一个 16 MB 的块中。 QEMU 甚至可以通过在缓存中将翻译后的代码块变为无效来支持代码的自我修改。
3、libvirt
- The KVM/QEMU Linux hypervisor
- The Xen hypervisor on Linux and Solaris hosts.
- The LXC Linux container system
- The OpenVZ Linux container system
- The User Mode Linux paravirtualized kernel
- The VirtualBox hypervisor
- The VMware ESX and GSX hypervisors
- The VMware Workstation and Player hypervisors
- The Microsoft Hyper-V hypervisor
- The IBM PowerVM hypervisor
- The Parallels hypervisor
- The Bhyve hypervisor

libvirt 比较和用例模型

图 使用 libvirtd 控制远程虚拟机监控程序
表 1. libvirt 支持的虚拟机监控程序
| 虚拟机监控程序 | 描述 |
|---|---|
| Xen | 面向 IA-32,IA-64 和 PowerPC 970 架构的虚拟机监控程序 |
| QEMU | 面向各种架构的平台仿真器 |
| Kernel-based Virtual Machine (KVM) | Linux 平台仿真器 |
| Linux Containers(LXC) | 用于操作系统虚拟化的 Linux(轻量级)容器 |
| OpenVZ | 基于 Linux 内核的操作系统级虚拟化 |
| VirtualBox | x86 虚拟化虚拟机监控程序 |
| User Mode Linux | 面向各种架构的 Linux 平台仿真器 |
| Test | 面向伪虚拟机监控程序的测试驱动器 |
| Storage | 存储池驱动器(本地磁盘,网络磁盘,iSCSI 卷) |
参考:
- Kvm Qemu Libvirt:http://kiwik.github.io/openstack/2014/05/04/KVM-QEMU-libvirt/#
- KVM虚拟机分析: http://wenku.baidu.com/link?url=1sEgxHLl-pYpSavmRJXwFq3QYHENQPvEX7QMUQ7zf9UL1Qkio1YNUVKhF-697vqk4O7DDjuEPc0NLbHfoiMbOkGo4zdmRjVjftWlkNa1AJy
- 使用QEMU进行系统仿真: https://www.ibm.com/developerworks/cn/linux/l-qemu/
- Libvirt虚拟化库剖析: https://www.ibm.com/developerworks/cn/linux/l-libvirt/
- Libvirt架构及源码分析(一) : http://blog.chinaunix.net/uid-20940095-id-3813601.html

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









