









该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/JUNJUN_ZHAO/article/details/78847856
Logistic 回归
In this video, we’ll go over logistic regression.This is a learning algorithm that you use when the output labels y in a supervised learning problem are all either zero or one,so for binary classification problems.Given an input feature vector x maybe corresponding to an image that you want to recognize as either a cat picture or not a cat picture,you want an algorithm that can output a prediction,which we’ll call y hat,which is your estimate of y.More formally, you want
y^
to be the probability of the chance that y is equal to one given the input features x.
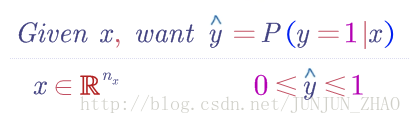
本视频中,我们讲讲 logistic 回归,这是一个用在监督学习问题中的学习算法 ,输出 y 标签是 0 或 1 时,这是一个二元分类问题。已知的输入特征向量 x 可能是一张图,你希望把识别出,这是不是猫图,你需要一个算法,可以给出一个预测值,我们说预测值 y^ ,就是你对 y 的预测,更正式的说,你希望 y^ 是一个概率,当输入特征 x 满足条件时,y 就是 1。
So in other words, if x is a picture,as we saw in the last video,you want y hat to tell you,what is the chance that this is a cat picture.So x, as we said in the previous video,is an
nx
dimensional vector,given that the parameters of logistic regression will be w,which is also an
nx
dimensional vector,together with b which is just a real number.So given an input
X
and the parameters
所以换句话说,如果 x 是图片,正如我们在上一个视频中看到的,你希望 y^ 能告诉你,这是一张猫图的概率,所以x 正如我们之前的视频里说过的,是一个 nx 维向量,已知 Logistic 回归的参数是 w,也是一个 nx 维向量,而 b 就是一个实数,所以已知输入 x 和参数 w 和 b,我们如何计算输出预测 y^ ? 好,你可以这么试,但其实不靠谱,就是 y^=wTx+b ,输入 X 的线性函数。
And in fact, this is what you use if you were doing linear regression.But this isn’t a very good algorithm for binary classification,because you want y hat to be the chance that Y is equal to one.So y hat should really be between zero and one,and it’s difficult to enforce that because
wTx+b
can be much bigger then one or it can even be negative,which doesn’t make sense for probability,that you want it to be between zero and one.

事实上,如果你做线性回归 就是这么算的。但这不是一个非常好的二元分类算法,因为你希望 y^ 是 y=1 的概率,所以 y^ 应该介于 0 和 1 之间,但实际上这很难实现,因为 wTx+b ,可能比 1 大得多或者甚至是负值 ,这样的概率是没意义的, 你希望概率介于 0 和 1 之间。
So in logistic regression our output is instead going to be y hat equals the sigmoid function applied to this quantity.This is what the sigmoid function looks like.If on the horizontal axis I plot Z then the function sigmoid of Z looks like this.So it goes smoothly from zero up to one.Let me label my axes here,this is zero and it crosses the vertical axis as 0.5.So this is what sigmoid of Z looks likeand we’re going to use Z to denote this quantity,W transpose X plus B.
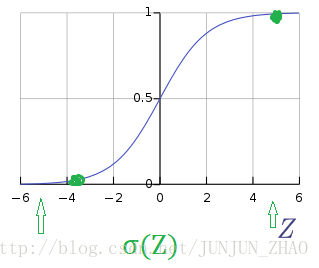
所以在 Logisitc 回归中我们的输出变成, y^ 等于 sigmoid 函数作用到这个量上,这就是 sigmoid 函数的图形,横轴是 z,那么 sigmoid(z) 就是这样的,从 0 到 1 的光滑函数,我标记一下这里的轴,这是 0 然后和垂直轴相交在 0.5 处,这就是 sigmoid(z) 的图形,我们用 z 来表示这个量,w 转置 x + b。
Here’s the formula for the sigmoid function.Sigmoid of Z, where Z is a real number,is one over one plus e to the negative Z.So notice a couple of things.If Z is very large then e to the negative, Z will be close to zero.So then sigmoid of Z will be approximately one over one plus something very close to zero,because e to the negative of very large number will be close to zero.So this is close to 1.
这是 Sigmoid 函数的公式, sigmoid(z) 其中 z 是实数,就是 11+e−z ,要注意一些事情,如果 z 非常大 那么 e−z 就很接近0,那么 sigmoid(z) 就是,大约等于 11+某个很接近0的量 ,因为 e−z 在 z 很大时就很接近 0,所以这接近 1。
And indeed, if you look in the plot on the left,if Z is very large the sigmoid of Z is very close to one.Conversely, if Z is very small,or it is a very large negative number,then sigmoid of Z becomes one over one plus E to the negative Z,and this becomes, it’s a huge number.
事实上,如果你看看左边的图,z 很大时 sigmoid(z) 就很接近1,相反 如果 z 很小,或者是非常大的负数,那么 sigmoid(z) 就变成 11+e−z ,就变成很大的数字。
So this becomes, think of it as one over one plus a number that is very, very big, and so,that’s close to zero.And indeed, you see that as Z becomes a very large negative number,sigmoid of Z goes very close to zero.So when you implement logistic regression,your job is to try to learn parameters W and B.so that y hat becomes a good estimateof the chance of Y being equal to one.
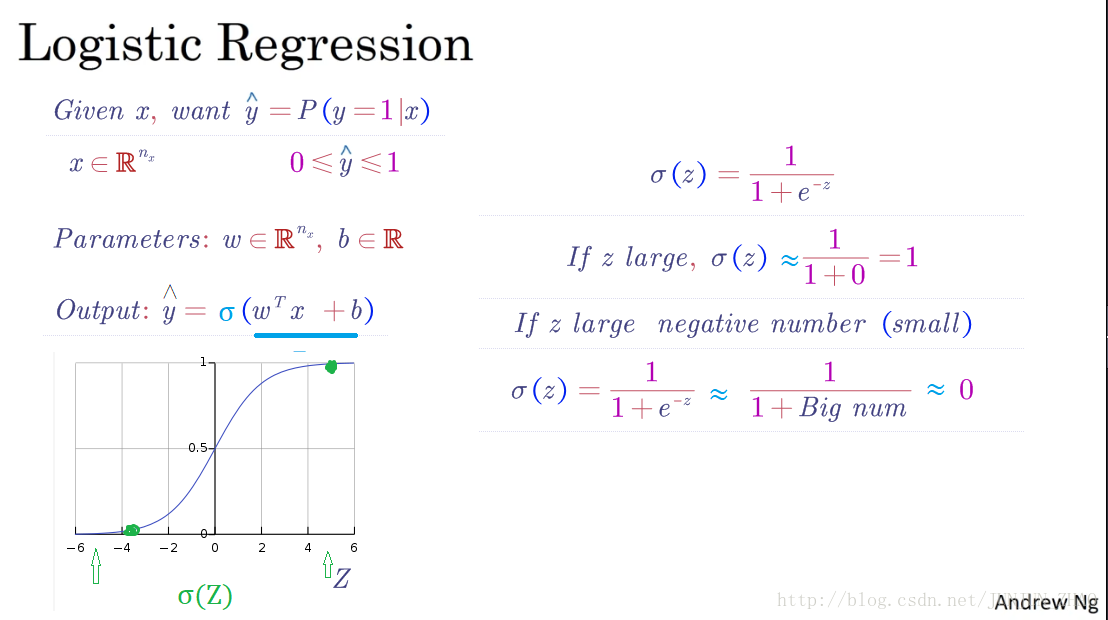
这就变成.. 想一下,1 除以 1 加上很大的数字 ,那是非常大的数字,所以这接近 0,确实 当你看到 z 变成非常大的负值时, sigmoid(z) 就很接近 0,所以当你实现 logistic 回归时,你要做的是学习参数 w 和 b,你要做的是学习参数w 和 b,所以 y^ 变成了比较好的估计,对 y=1 概率的比较好的估计。
Before moving on, just another note on the notation.When we programmed neural networks,we’ll usually keep the parameter W and parameter b separate,where here, b corresponds to an interceptor.In some other courses,you might have seen a notation that handles this differently.In some conventions you define an extra feature called x0 and that equals a one.So that now x is in R(nx+1) .And then you define y hat to be equal to sigma of theta transpose X.
在继续之前,们再讲讲符号约定,当我们对神经网络编程时,我们通常会把 w和参数 b 分开,这里 b 对应一个拦截器。在其他一些课程中,你们可能看过不同的表示,在一些符号约定中,你定义一个额外的特征向量 叫 x0 那等于 1,所以出现 x 就是 R(nx+1) 维向量,然后你将 y^ 定义为 σ(θTx) 。
In this alternative notational convention,you have vector parameters theta,theta zero θ0 , theta one θ1 , theta two θ2 ,down to theta nx θnx .And so, theta zero θ0 , plays the role of b,that’s just a real number,and theta one θ0 down to theta nx θnx play the role of W.It turns out, when you implement you implement your neural network,it will be easier to just keep b and W as separate parameters.
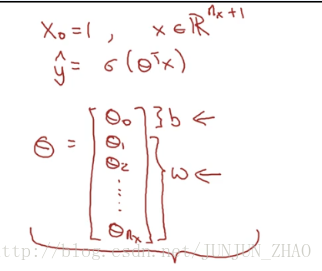
在这另一种符号约定中,你有一个向量参数 θ ,
And so, in this class,we will not use any of this notational convention that I just wrote in red.If you’ve not seen this notation before in other courses,don’t worry about it.It’s just that for those of you that have seen this notation I wanted to mention explicitly that we’re not using that notation in this course.But if you’ve not seen this before,it’s not important and you don’t need to worry about it.So you have now seen what the logistic regression model looks like.Next to change the parameters W and B.you need to define a cost function.Let’s do that in the next video.
所以对于这门课,我们不会用那种符号约定,就是红色写的那些我不会用,如果你们没有在其他课程里见过这个符号约定,不要担心太多,我讲这个是为了服务那些见过这种符号约定的学生,我们在本课中不会使用那种符号约定,如果你以前没见过,这不重要所以不用担心,现在你看到了 logistic 回归模型长什么样,接下来我们看参数 w 和 b,你需要定义一个成本函数,我们下一个视频来讨论。
重点总结:
2. logistic Regression
逻辑回归中,预测值:
其表示为 1 的概率,取值范围在 [0,1] 之间。
引入 Sigmoid 函数,预测值:
其中
注意点:函数的一阶导数可以用其自身表示,
该部分的求导可查看:Logistic回归-代价函数求导过程 | 内含数学相关基础
这里可以解释梯度消失的问题,当 z=0 时,导数最大,但是导数最大为 σ′(0)=σ(0)(1−σ(0))=0.5(1−0.5)=0.25 ,这里导数仅为原函数值的 0.25 倍。
参数梯度下降公式的不断更新, σ'(z) 会变得越来越小,每次迭代参数更新的步伐越来越小,最终接近于 0,产生梯度消失的现象。
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)– 神经网络基础 CSDN
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









