







 本文介绍了SQL Server中大数据量查询记录数的优化方法,对比了count(*)和查询sysindexes视图的效率差异。通过实验展示了在不同索引类型下两者的执行时间和执行计划,揭示了count(*)全表扫描的低效和sysindexes的高效原因。同时,文章讨论了如何利用索引来提高查询速度,并提供了对数据库调优的深入理解。
本文介绍了SQL Server中大数据量查询记录数的优化方法,对比了count(*)和查询sysindexes视图的效率差异。通过实验展示了在不同索引类型下两者的执行时间和执行计划,揭示了count(*)全表扫描的低效和sysindexes的高效原因。同时,文章讨论了如何利用索引来提高查询速度,并提供了对数据库调优的深入理解。
问题描述
生产库中一张表的数据10亿级别,另一张表数据100亿级别,还有其他表的数据也是相当地庞大。入职之前不知道这些表有那么大的数据量,于是习惯了使用count(*)来统计表的记录数。但这一执行就不得了,跑了30多分钟都没出结果,最后只有取消查询。后来采取了另一种办法查询记录数。首先说明下解决的办法,使用如下SQL:
SELECT object_name(id) as TableName,indid,rows,rowcnt
FROM sys.sysindexes WHERE id = object_id('TableName')
and indid in (0,1);
问题模拟
接着我做了一个模拟,并且试着从原理的角度分析下使用count(*)和查询sysindexes视图为什么会出现那么大的差距。
我们做模拟之前首先要得测试数据。所以我创建一个了测试表,并且插入测试数据。这里插入1亿条数据。
创建测试表的语句如下:
DROP TABLE count_Test;
CREATE TABLE count_Test
(
id bigint,
name VARCHAR(20),
phoneNo VARCHAR(11)
);
由于插入大量数据,我们肯定不能手动来。于是我写了一个存储过程,插入1亿条数据。为了模拟出数据的复杂性,数据我采用随机字符串的形式。插入测试数据的存储过程如下:
CREATE PROCEDURE pro_Count_Test
AS
BEGIN
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SET NOCOUNT ON;
WITH Seq(id,name,phoneNo) AS
(
SELECT 1,cast('13'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
AS varchar),9) AS VARCHAR(20)),
cast('name_'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
AS varchar),9) AS VARCHAR(40))
UNION ALL
SELECT id+1,cast('13'+right('000000000'+ cast(cast(rand(checksum(newid()))*100000000 AS int)
AS varchar),9) AS VARCHAR(20)),
cast('name_'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
AS varchar),9) AS VARCHAR(40))
FROM Seq
WHERE id <= 100000000
)
INSERT INTO count_Test(id,name,phoneNo)
SELECT id,name,phoneNo
FROM Seq
OPTION (MAXRECURSION 0)
SET STATISTICS IO OFF ;
SET STATISTICS TIME OFF;
END接着我们执行此存储过程,插入测试数据。SQL Server Management Studio在输出窗口的右下角记录了操作的时间。为了更直观,我们手动写了个记录时间的语句,如下:
DECLARE @d datetime
SET @d=getdate()
print '开始执行存储过程...'
EXEC pro_Count_Test;
SELECT [存储过程执行花费时间(毫秒)]=datediff(ms,@d,getdate())
好了,等待47分29秒,数据插入完毕,插入数据的统计信息如图一,占用数据空间如图二,我们开始测试count(*)和sysindexes在效率上的差别。
图一 插入1亿行数据统计信息

图二 插入1亿行数据占用空间
在没有任何索引的情况下使用count(*)测试,语句如下:
DECLARE @d datetime
SET @d=getdate()
SELECT COUNT(*) FROM count_Test;
SELECT [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
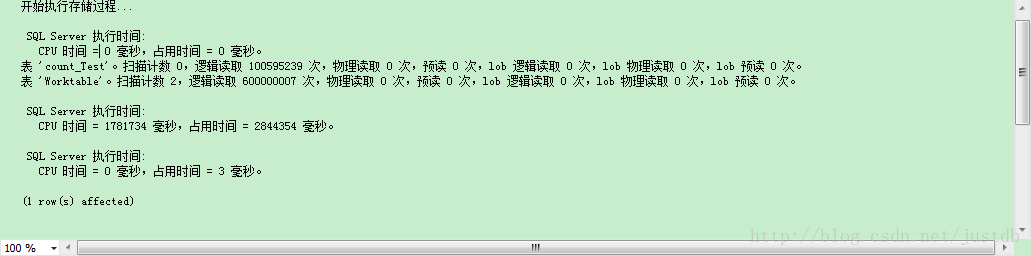
测试时内存使用率一度飙到96%,可见效率是极低的。测试结果用时1分42秒,如图三,我们查看此时的执行计划,如图四。可以清晰地看到此时走的是全表扫描,并且绝大多数的开销都花销在这上面。

图三 无索引使用count(*)执行时间
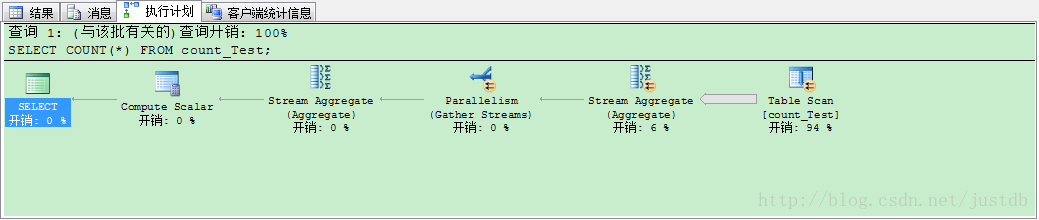
图四 无索引使用count(*)执行计划
在没有任何索引的情况下使用sysindexes测试,语句如下:
DECLARE @d datetime
SET @d=getdate()
SELECT object_name(id) as TableName,indid,rows,rowcnt
FROM sys.sysindexes WHERE id = object_id('count_Test')
and indid in(0,1);
SELECT [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())测试结果用时450毫秒,如图五。我们查看此时的执行计划,如图六。可以看到此时走的是聚集索引扫描,并且全部的开销都在此。

图五 无索引使用使用sysindexes执行时间
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









