







C4.5决策树的工程实现
这篇文章开始,将讲述一系列机器学习算法的工程实现方案。出于常用且简单的考虑,选择了C4.5决策树作为第一个算法。
工程框架
鉴于本篇是第一个算法实现,应此需要把整个工程框架介绍一下。
出于最优性能考虑,本框架是为C/C++语言设计的。不过即使用其他语言,也可以按这个框架实现,模块还可以再精简。
本工程定位:
1、无脑版机器学习算法库,使用者基本不需要了解任何算法细节,也不需要了解配置的算法参数含义。
2、可分离的算法库,算法库输出的模型文件可以方便地被其他工程解析使用。
3、高性能的算法库,理论上能达到极限性能。
总体设计如下图:
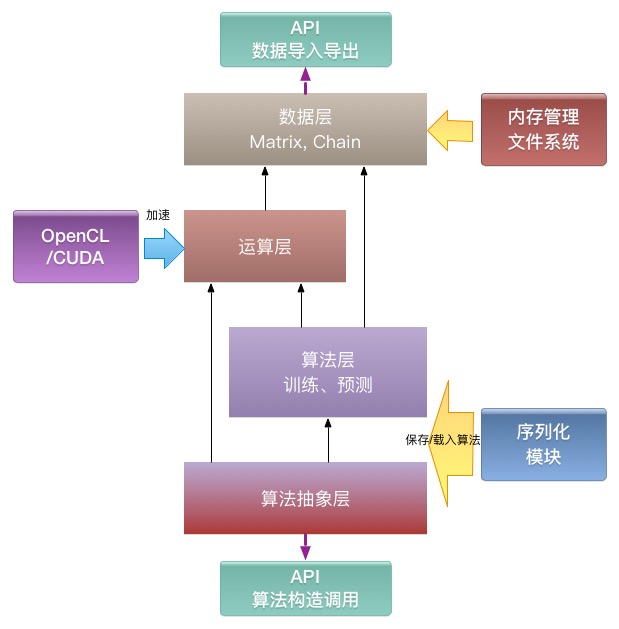
数据层
这一层解决数据如何定义,如何产生,如何使用,如何销毁的问题。
定义两种数据类型:
Matrix:静态数据,矩阵形式存储,默认使用浮点,精度可全局性地作配置。
Chain:动态数据,也即时间序列类型数据。
理想情况是,数据层尽量提供统一接口供运算层和算法层使用,无论是在CPU上申请的矩阵内存,还是在GPU显存中申请出来的内存,无论是普通矩阵,还是稀疏矩阵,对外透明。不过,有些算法还是必须要根据矩阵的具体情况作区分的(比如QR变换算矩阵特征向量的算法就希望基于稀疏矩阵加速),因此,除了统一接口外,也支持类型识别,让运算层能够“因地制宜”。
离散数据和连续数据的区分也是作抽象的一个难点,这里的设计是默认数据是连续的,但在Matrix和Chain类型中引入meta信息,用元数据去确定那些列是离散的,有哪些离散值可选。
运算层
特性
一方面,机器学习算法大部分都是矩阵运算,封装在一层便于复用,另一方面,为了后续性能优化便利,需要专门一个运算层。此层作为优化重点,需要接一个优化模块。
提供如下功能:
1、基本矩阵运算:矩阵相乘、矩阵求逆、求特征根等等。
2、基于矩阵的复杂运算:梯度下降、卷积、核函数映射等等。
3、数据转换相关:时间序列展开为矩阵数据(AR模型、相空间重构等)、稀疏矩阵与稠密矩阵互转、数据随机抽样等等。
优化
优化手段主要包括两方面,可根据实际应用的需要,去专门优化某些算法。
1、GPGPU:OpenCL/CUDA
2、SIMD:neon/SSE
有句“名言”:过早优化是万恶之源。但踩过一系列代码优化的坑后,深刻觉得,不考虑优化才是万恶之源,对一个写得很糟糕的程序作优化改造的代价,远超过一开始就高效率编写的时间成本。讲究代码效率,也并不是说一开始就要把性能优化到极致,而是要按一个有利于后续性能优化的框架去设计,这样后面在有性能要求时不需要作大重构。
算法层
这一层实现基础的机器学习算法。如SVM、C45决策树、朴素贝叶斯、逻辑回归等。
我们很希望全部运算在矩阵运算层中做掉,这样可以统一优化。不过理想很美好,现实很残酷。考虑有些操作不容易封装矩阵运算层,这一层也允许直接与数据层交互,操作实际数据。
以下是算法层的接口定义:
/*预测模型*/
class IPredictor
{
public:
virtual Matrix* vPredict(Matrix* X) const = 0;
/*以下两个接口用于分类*/
//输出各个类型的概率
virtual Matrix* vPredictProb(Matrix* X) const = 0;
//获得各个类型的值
virtual Matrix* vGetValues() const = 0;
virtual Node* vDump() const = 0;
};
/*监督学习算法*/
class ILearner
{
public:
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const = 0;
};
/*非监督学习算法*/
class IFreeLearner
{
public:
virtual IPredictor* vLearn(Matrix* X) const = 0;
};
/*时间序列预测模型*/
class IChainPredictor
{
public:
virtual Chain* vPredict(Chain* X) const = 0;
virtual Node* vDump() const = 0;
};
/*时间序列训练算法*/
class IChainLearner
{
public:
virtual IChainPredictor* vLearn(Matrix* X) const = 0;
};注意到,对于分类模型,我们给出了提供概率预测的需求,这对于一些应用场景是很重要的,比如基于人脸识别的一系列图像处理算法。事实上,所有分类算法,都是可以计算这个概率的。
出于更广泛的工程应用考虑,我们需要能将预测算法(也即训练所得模型)序列化。推荐的方式是dump成一棵语法树(上面的Node为树结点),然后选一个json或xml库去序列化。反序列化时,先解出语法树,再根据语法树还原模型。
算法抽象层
这一层的目的是实现复合算法,比如基于决策树实现随机森林、adaboost、gbdt,基于二分类SVM实现多分类SVM,以及对训练算法作评分(交叉验证)等等。 这一层允许调用算法层的接口和运算层的数据转换接口(比如抽样等)。
C45决策树算法实现
关于决策树的算法原理可参考这篇文章:
http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
算法描述与参数
引自上面那篇文章,该算法步骤如下:
1. 开始,所有记录看作一个节点
2. 遍历每个变量的每一种分割方式,找到最好的分割点
3. 分割成两个节点N1和N2
4. 对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止详细的实现是这样的:
训练算法:
1、接受输入自变量矩阵X,因变量矩阵Y
2、基于矩阵Y计算纯度,满足如下任一条件则终止,转步骤5生成节点:
(1)达到最大树深限制
(2)纯度达到targetPrune
(3)Y的数量小于minNumber
3、基于自变量矩阵X的统计列出所有分划点,遍历每一个点,计算纯度增益,选取收益最大的一个分划点:
(1)基于该点分隔对应的Y为Y1和Y2。
(2)按一定公式计算Y1的纯度和Y2的纯度。
(3)计算纯度增益。
4、产生分划点,并基于最优分划点,将Y分成Y1和Y2,将X分为X1和X2,从1步执行。
5、产生结果点:
(1)得出Y中所有类型,记为数值矩阵。
(2)计算Y中所有类型的占比,记为概率矩阵。
(3)以概率最高的类型作为该点的默认预测值。这里涉及到这些参数:
1、最大树深限制maxDepth
2、提前终止的纯度要求targetPrune
3、每个有效节点至少要覆盖到的数据量minNumber
这三个参数需要按一定规则,将其映射到[0,1)区间,以便使用者无差别调参。
树结构
分划点
1、分划信息:第几列,值为多少
2、左右两节点的指针/引用
结果点
结果点包括
1、概率矩阵
2、数值矩阵
3、默认值
预测时,按分划信息一层层往下找到结果点,取结果点的概率矩阵和数值矩阵即可。
类、模块位置
无论是ID3、C45还是C50算法,决策树的预测模型都是一种相同的树型结构,而C45决策树是一种构造决策树的算法。因此,命名方面,预测模型是不带C45的前缀的。
该算法涉及到的类分布如下:
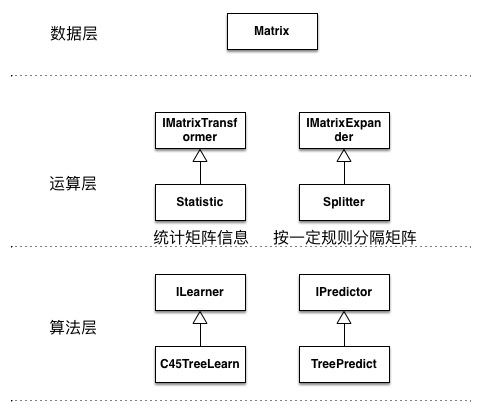














 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









