







图像表达
用RCNN提取图像中的物体(取概率最大的19个),然后和原始图像一起作为CNN输入,获得图像的特征向量(每幅图20个)
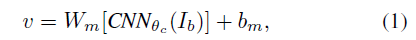
句子表达
使用BRNN,输入为word2vec的词向量(e)
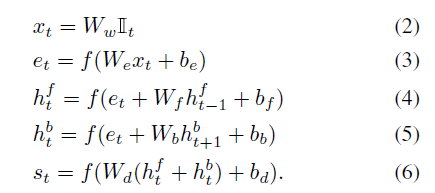
结合图像和句子
损失函数是图像向量和句子向量的match程度
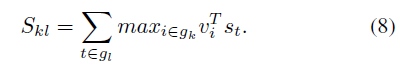
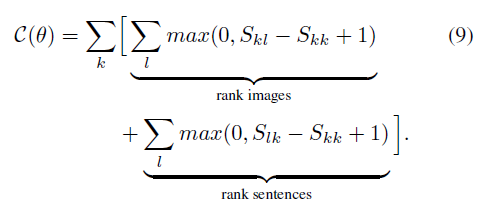
该损失函数使得匹配的图像-句子对比不匹配的对具有更高的得分,并且有余量(类似svm合页损失函数)
从匹配的词语生成连贯的短语
上面的方法生成了图像区域-词语对,现在我们需要把对应同一个图像区域的词语连接起来成为有意义的短语。使用马尔可夫随机场(即条件随机场)。定义能力函数为:
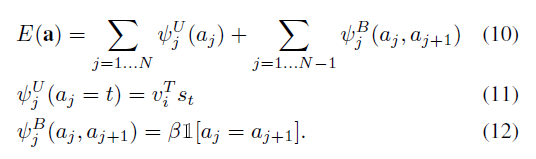
对条件随机场做参数估计,之后就能解序列问题得到最佳的状态序列,从而得到最好的短语。
生成整幅图的描述
使用RNN,并把图像向量也作为一个输入(Deep Learning一书中描述的将额外输入提供给RNN的三种方式:在每个时刻作为一个额外数据;作为初始状态h0;结合两者)
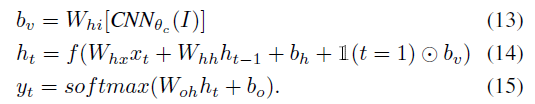
图像向量只作为第一个神经元的输入,句子结束是通过y(t)为结束符(Deep Learning一书中描述的三种确定输出长度的机制:对应序列末端的特殊符号;模型中加入一个伯努利输出表明是否结束;输出一个参数代表长度本身)














 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









