







首先,Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题,此外还能解决非线性问题。
LR分类器(Logistic Regression Classifier)目的就是从训练数据特征学习出一个0/1分类模型--这个模型以样本特征的线性组合作为自变量,使用logistic函数将自变量映射到(0,1)上。因此LR分类器的求解就是求解一组权值,当有一新样本过来时,首先将特征线性加权,然后代入Logistic函数,函数的输出值表示结果为1的概率,就是特征属于y=1的概率。
Logistic回归其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高。
算法优化--随机梯度法
梯度上升(下降)算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理100个左右的数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度算法。由于可以在新样本到来时对分类器进行增量式更新,它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算,因而随机梯度算法是一个在线学习算法。(与“在线学习”相对应,一次处理所有数据被称作是“批处理”)。随机梯度算法与梯度算法的效果相当,但具有更高的计算效率。
数据丢失处理方法
训练数据中样本特征值的部分缺失是很棘手的问题,很多文献致力于解决该问题,因为数据直接丢掉太可惜,重新获取代价也昂贵。一些可选的数据丢失处理方法包括:
□使用可用特征的均值来填补缺失值;
□使用特殊值来±真补缺失值,如-1;
□忽略有缺失值的样本;
□使用相似样本的均值添补缺失值;
□使用另外的机器学习算法预测缺失值。
损失函数
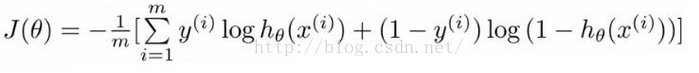
处理多分类问题
所谓one-vs-all method就是将binary分类的方法应用到多类分类中。
比如我想分成K类,那么就将其中一类作为positive,另(k-1)合起来作为negative,这样进行K个h(θ)的参数优化,每次得到的一个hθ(x)是指给定θ和x,它属于positive的类的概率。给定一个输入向量x,获得最大hθ(x)的类就是x所分到的类。
解决过拟合问题:
1. 减少feature个数(人工定义留多少个feature或者算法选取这些feature)
2. 正则化(留下所有的feature,但对于部分feature定义其parameter非常小)
PS:正则化之后就转化为了岭回归,类似的还有lasso回归等。














 9426
9426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









