







51job爬虫篇(二)
分析篇
继上一篇抓取到了公司名字和公司链接之后,公司的链接里面包含了公司的详细信息,例如公司业务简介,规模以及公司地址
所以我们可以用到上一次抓取回来公司连接地址,再编写不同的爬虫规则,再抓取一次,就可以抓到公司详细信息继续来分析站点html结构,从下图图一可以看到红色框框就是我们需要的信息,同意可以根据xpath的结构获取指定位置的内容
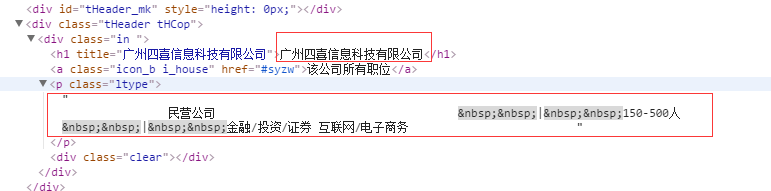
这里有我们需要的公司简介

这里有我们需要的公司地址

再仔细分析上面的html结构,我们可以通过下面的xpath抓取固定的内容
item['name'] = response.xpath('//div[@class="tHeader tHCop"]/*/h1/text()').extract()[0]
item['ltype'] = response.xpath('//div[@class="tHeader tHCop"]/*/p[@class="ltype"]/text()').extract()[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6436
6436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









