







本篇博文在编写时参考了http://cuiqingcai.com/2652.html,向作者表示感谢
一.新的问题与工具
平时在淘宝上剁手的时候,总是会看到各种各样的模特。由于自己就读于一所男女比例三比一的工科院校……写代码之余看看美女也是极好的放松方式。但一张一张点右键–另存为又显得太过麻烦而且不切实际,毕竟图片太多了。于是,我开始考虑用万能的python来解决问题。
我们先看看淘女郎页面的URL,https://mm.taobao.com/json/request_top_list.htm?page=1
page后面的数字代表页码,那么有多少页呢?反正我试着写了个10000发现依然有页面存在。由此可见,右键另存为极不现实。
要用爬虫去爬,就得先分析页面,我们打开第一个淘女郎的页面,如图
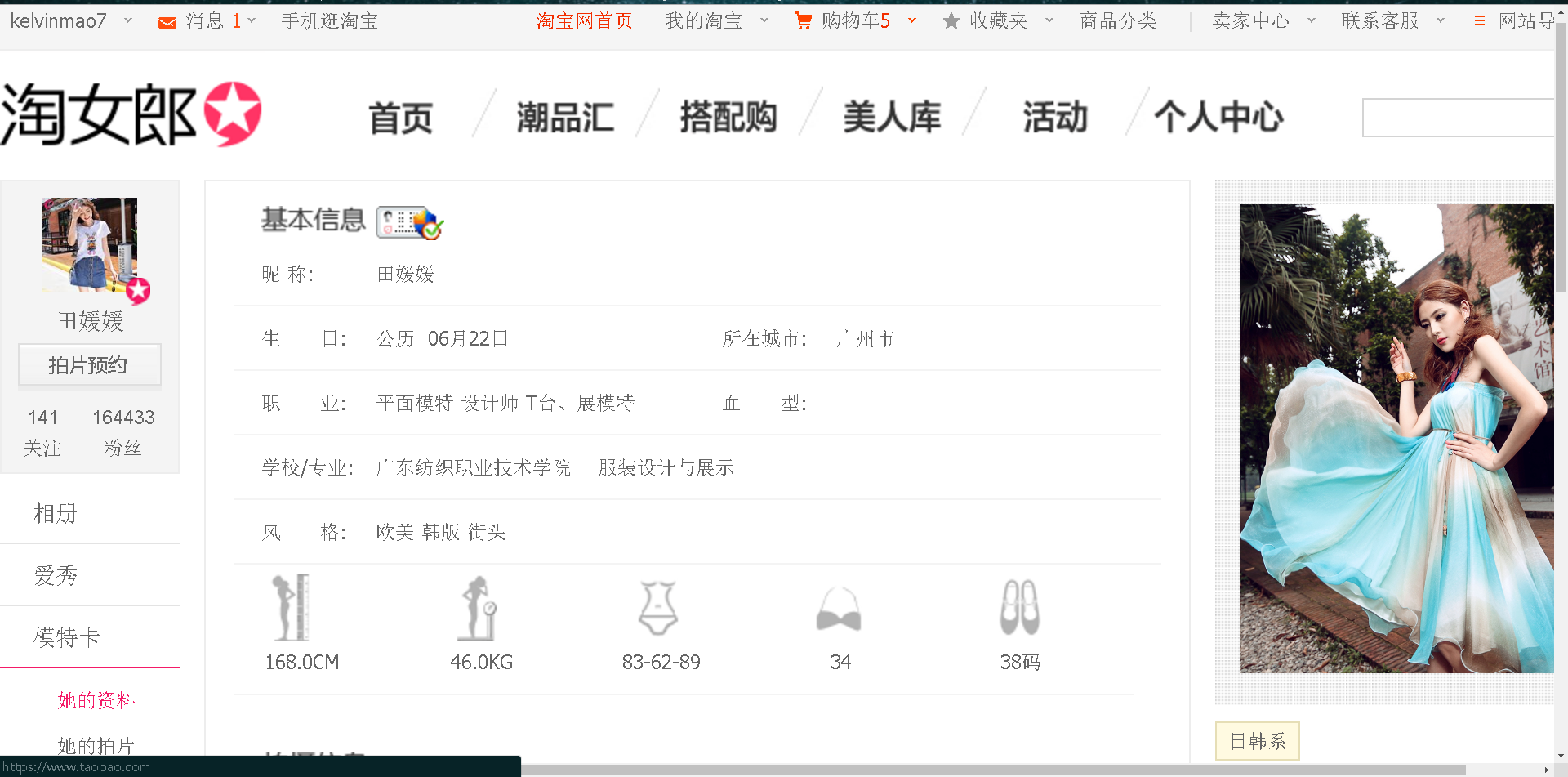
看起来好像和我们之前爬过的站没什么不同嘛,直接上urllib和urllib2不就好了?不过,当我打开页面源码时,发现并非如此,源码如图
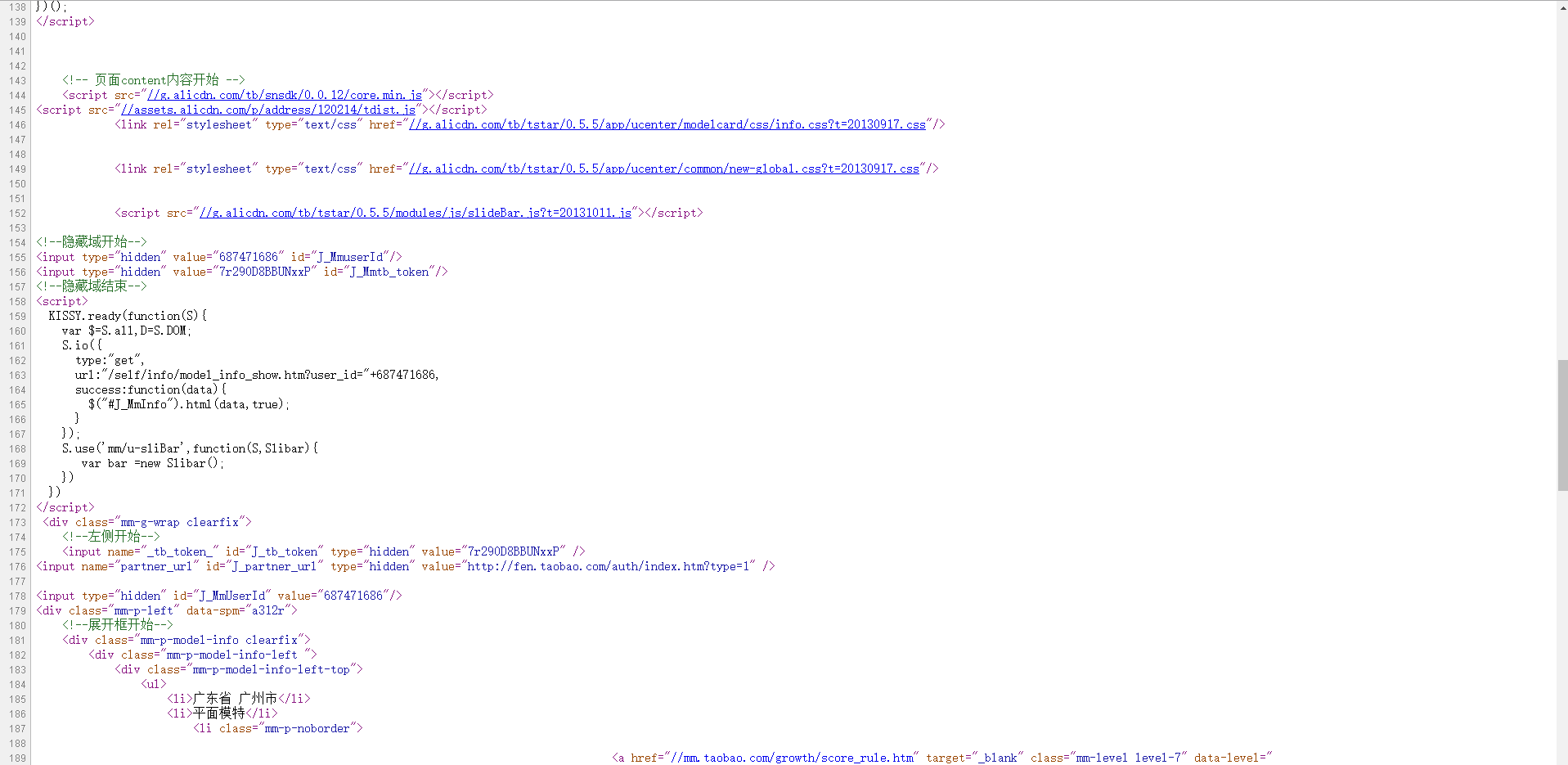
这个页面的很多内容并没有出现在源码中,很明显,使用js加载出来的。那么,我们常用的urllib2库也就起不了什么作用了,因为这个库只能获取到HTML中的内容。于是,在经过查找资料后, 我找到了另外两个好用的工具:Pyspider和Phantomjs
Pyspider是一个爬虫框架,具有webUI,CSS选择器等实用的功能,支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等等的功能,使用非常人性化。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它全面支持web而不需浏览器支持,其快速、原生支持各种Web标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可以用于页面自动化、网络监测、网页截屏以及无界面测试等。
在介绍完我们的主角之后,我会对我配置开发环境的过程中遇到的问题进行记录。
二.开发环境的配置
系统环境:Ubuntu 14.04 -i386(注意一定要使用32位的Ubuntu,因为经过我的实际测试phantomjs无法在64位系统上运行,另外,也无法再16.04版本的Ubuntu上运行,建议系统环境与我保持一致)
step 1:安装pip
sudo apt-get install python-pipstep 2:安装Phantomjs
sudo apt-get install phantomjsstep 3:安装Pyspider
根据官方文档,在在安装pyspider之前,你需要安装以下类库
sudo apt-get install python python-dev python-distribute python-pip libcurl4-openssl-dev libxml2-dev libxslt1-dev python-lxml安装过程完成之后,运行
sudo pyspider all不报错即为安装成功,如果有错误,请善用google和baidu,都可以找到答案。
之后进入图形界面,打开浏览器在地址栏中输入localhost:5000即可
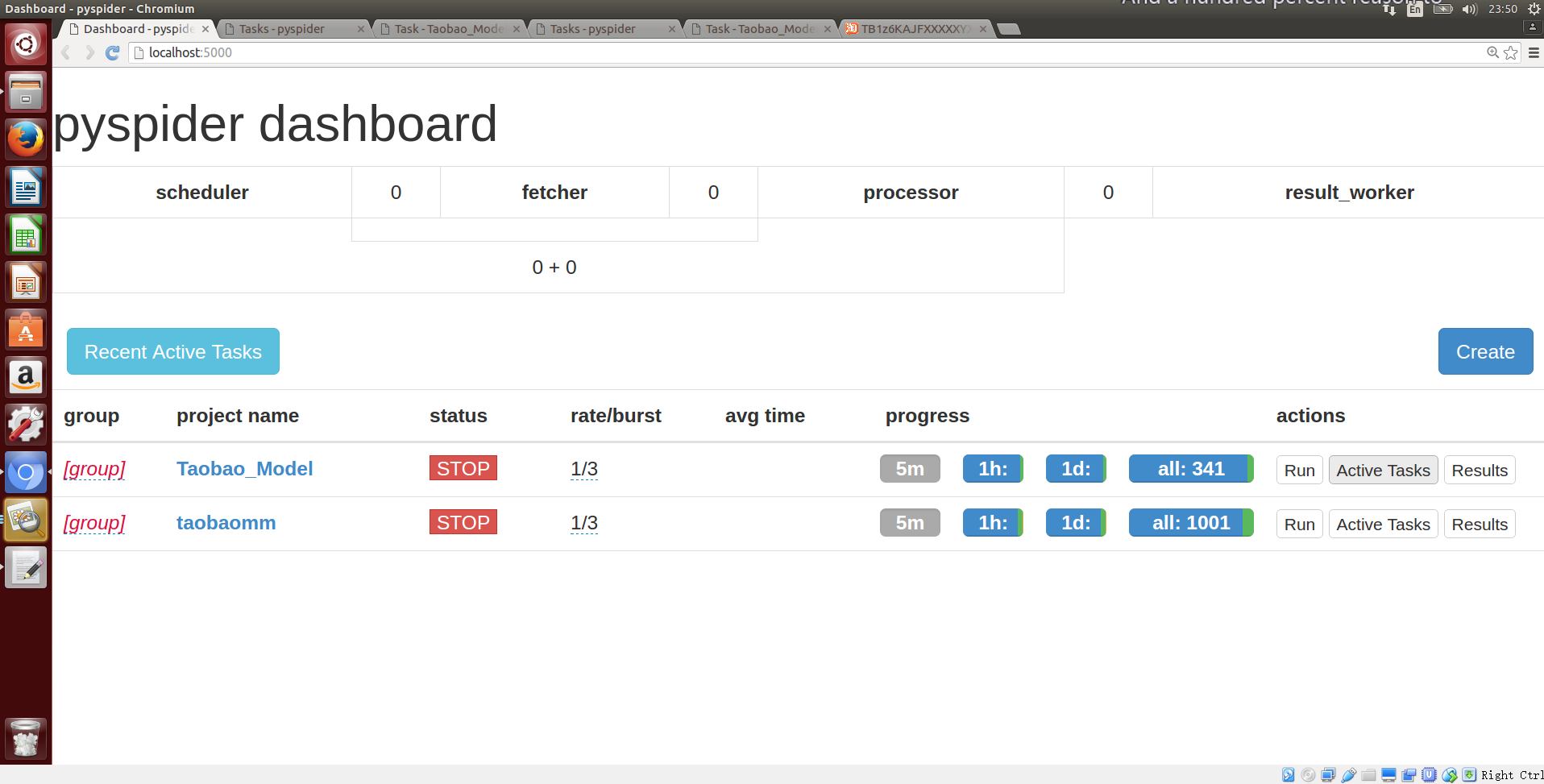
下面记录一个似乎是只有我遇到的问题,在使用ubuntu自带的firefox时,在之后的一步操作中会出现问题,至于问题是什么待会儿陈述,强烈建议各位使用应用商店中别的浏览器。
之后打开目标网站https://mm.taobao.com/json/request_top_list.htm?page=1
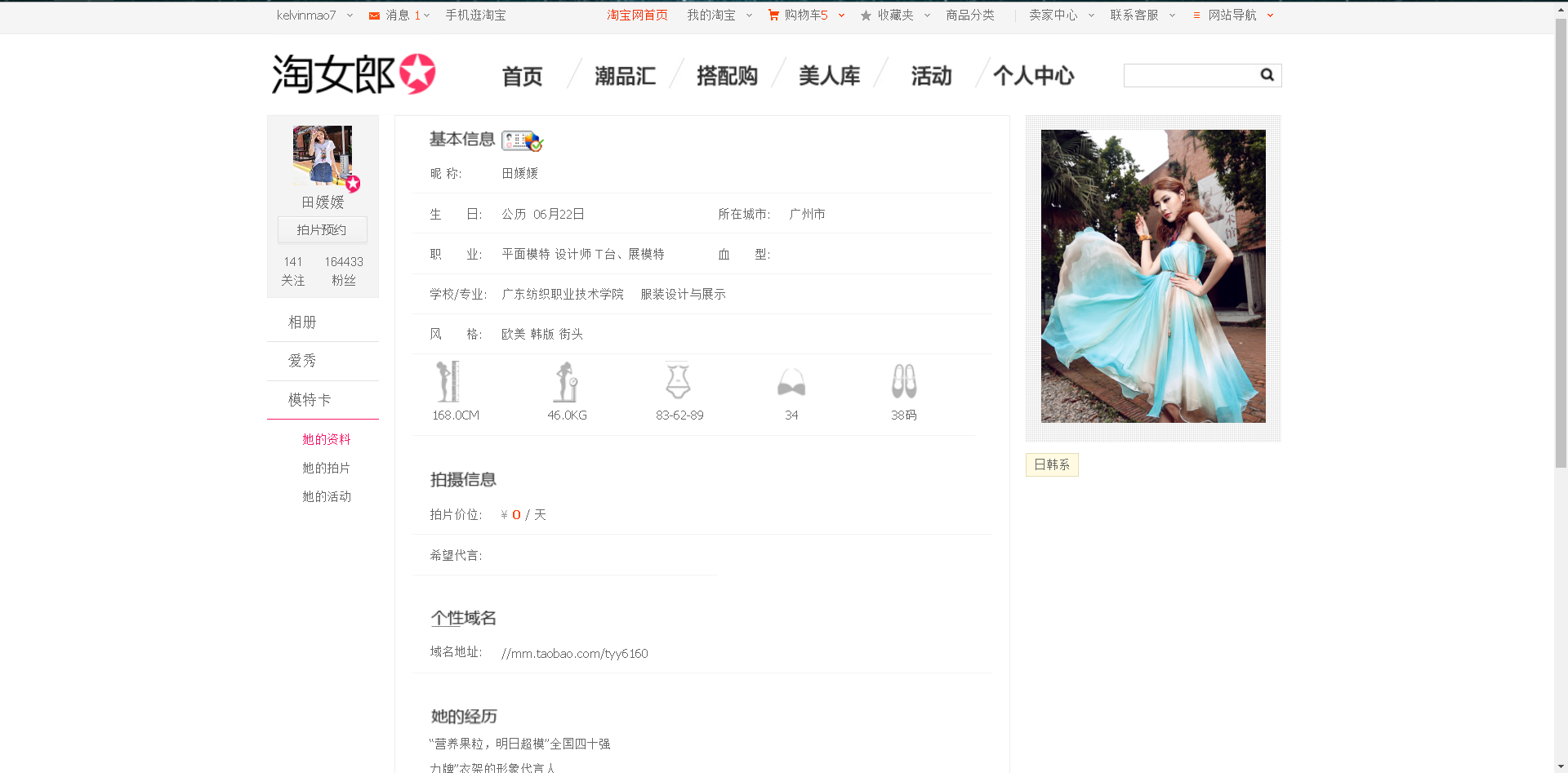
打开第一位模特的页面,如图
注意到个性域名了吗?进去看看~

原来模特的图片都在这里,这样我们大致确定了爬取思路:
1.在某一页中先爬取每位模特的详情页
2.在详情页中取出我们需要的个性域名的url
3.从个性域名中筛选出图片并保存。
三.开始爬取
(1)创建项目
在浏览器中输入 http://localhost:5000,可以看到 PySpider 的主界面,点击的 Create,命名为 taobaomm,名称你可以随意取,点击 Create。
之后进入到一个爬取操作的页面。
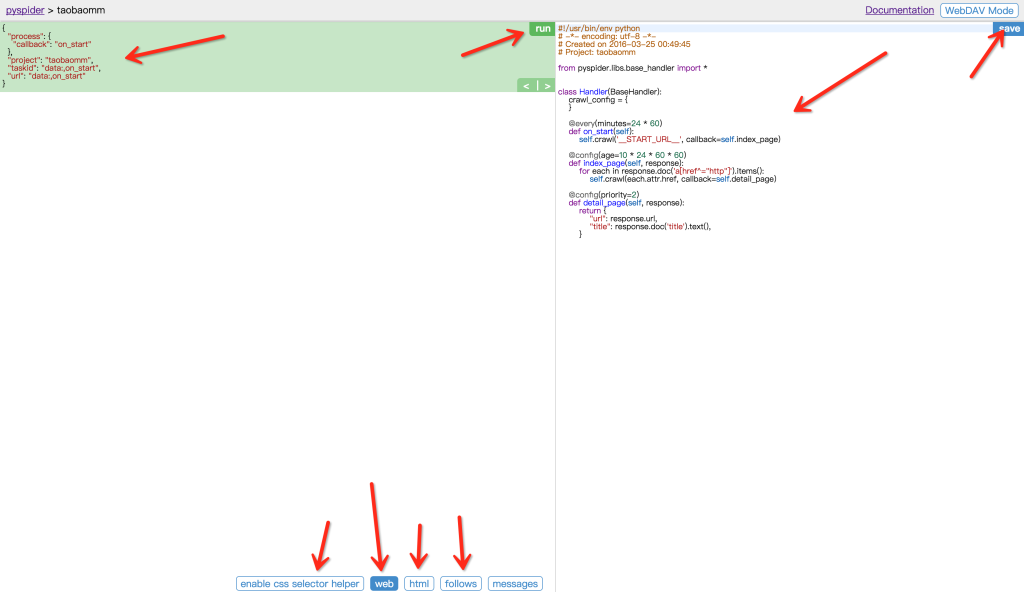
我们看到页面被分为两栏,左边是爬取页面预览区域,右边是代码编写区域。
左侧绿色区域:这个请求对应的 JSON 变量,在 PySpider 中,其实每个请求都有与之对应的 JSON 变量,包括回调函数,方法名,请求链接,请求数据等等。
绿色区域右上角Run:点击右上角的 run 按钮,就会执行这个请求,可以在左边的白色区域出现请求的结果。
左侧 enable css selector helper: 抓取页面之后,点击此按钮,可以方便地获取页面中某个元素的 CSS 选择器。
左侧 web: 即抓取的页面的实时预览图。
左侧 html: 抓取页面的 HTML 代码。
左侧 follows: 如果当前抓取方法中又新建了爬取请求,那么接下来的请求就会出现在 follows 里。
左侧 messages: 爬取过程中输出的一些信息。
右侧代码区域: 你可以在右侧区域书写代码,并点击右上角的 Save 按钮保存。
右侧 WebDAV Mode: 打开调试模式,左侧最大化,便于观察调试。
(2)进行简单的爬取操作
我们先对https://mm.taobao.com/json/request_top_list.htm?page=1这个页面进行爬取,我们在’init’ 方法中定义基地址,页码,最大页码。代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









