







接上一篇HBase的安装以及简单操作...
2.Hive
2.1.单机环境下Hive安装
下载hive,链接http://apache.cs.utah.edu/hive/,最新版本为hive-0.13.0。
解压tar –zxvf apache-hive-0.13.0.tar.gz,安装在hadoop目录下。
配置环境变量,sudo gedit /etc/profile,如下所示:
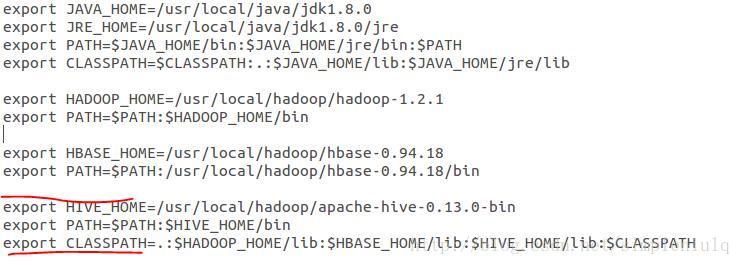
同样执行source /etc/profile使其生效。
进入$HIVE_HOME/conf目录,原来有四个template文件,执行命令生成正式配置文件:
cp hive-default.xml.template hive-site.xml
cp hive-env.sh.template hive-env.sh
cp hive-exec-log4j.properties.templatehive-exec-log4j.properties
cp hive-log4j.properties.templatehive-log4j.properties

编辑hive-site.xml文件,在最后加入:

说明:根据自己jar的路径。
至此配置完成,后续进行shell操作。
2.2.Hiveshell简单操作
启动hive,进入$HIVE_HOME目录,执行bin/hive,执行jps检测:
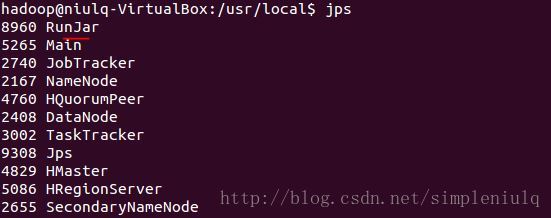
多出一个RunJar,暂时不了解是何作用。
在hive中建表:

从文本中导入数据:
文本数据格式为:
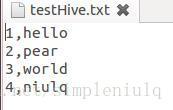
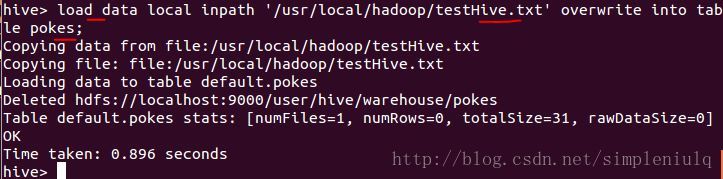
执行SQL查询:
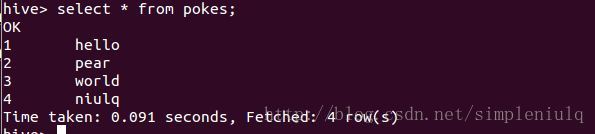
2.3.Hiveshell实验-莎士比亚文档词频统计
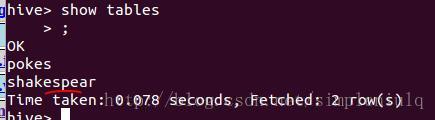
创建表:Shakespeare(word string,count int):

用showtables查询所有的表:
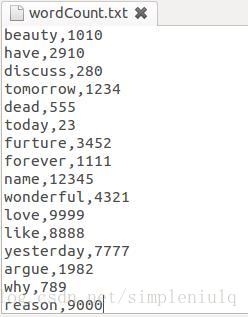
由于是实验,所以自己定义了一个词频统计文件,wordCount.txt,如下格式:
导入wordCount.txt中的数据:
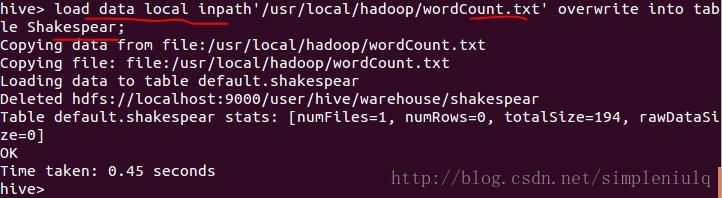
注意:hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
SQL查询Shakespear中的数据:
执行select* from shakespear;则会直接得到数据,如下:
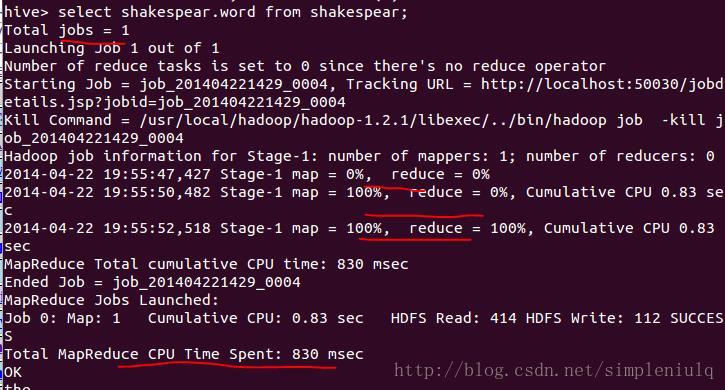
执行selectshakespear.word from shakespear;,将会采用mapreduce执行查询,如下:
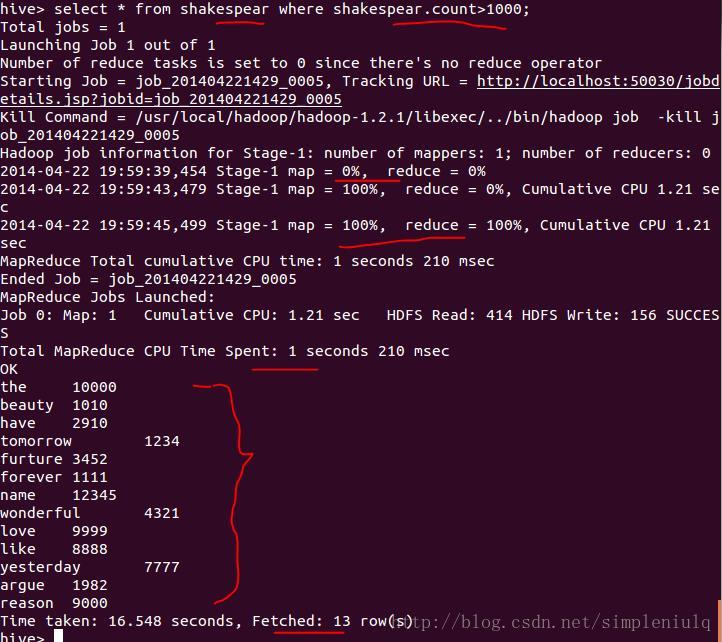
检索表中词频数count大于1000的词,执行select* from shakespear where shakespear.count>1000;,得到如下结果:
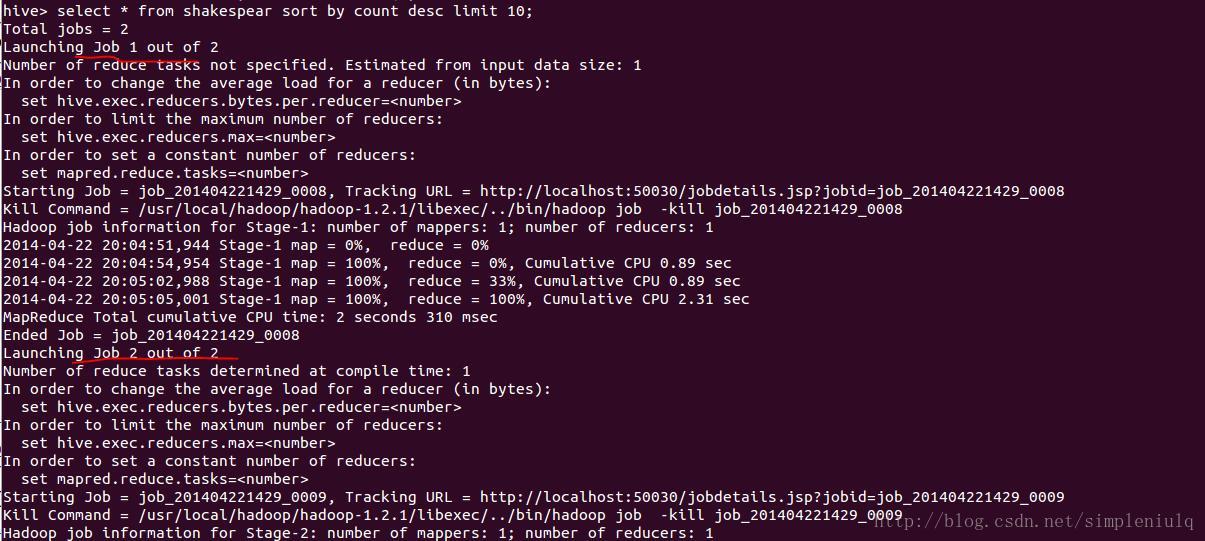
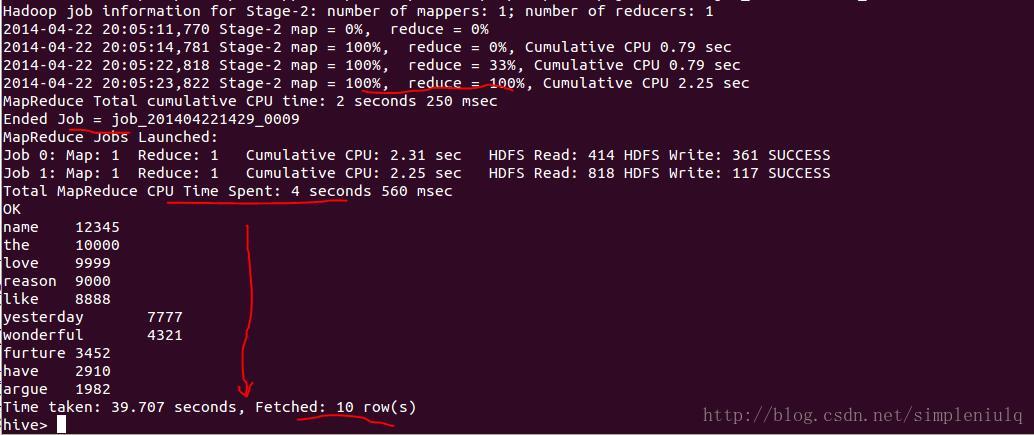
检索表中前10个出现次数最多的词,执行select* from shakespear sort by count desc limit 10;,得到如下结果:
3.HBase与Hive总结
3.1.HBase原理
在整个HBase到操作建表的过程中,我们可以体会到HBase是建立在HDFS之上,并且由于所创建的表与google BigTable相似,由行,列族,列名,值组成。因此,可以看到相比HDFS的一般性,HBase可以为上层应用提供结构化半结构化海量数据存储访问能力。
即光有分布式文件系统HDFS还不足够,HBase支持了分布式文件系统之上的非关系型数据库,为用户提供数据的存储访问。
3.2.Hive原理
通过Hive的安装以及查询,我们可以体会到,Hive建立在HDFS、HBase、MapReduce之上,既可以完成数据的存储,也可以完成数据的访问。对于每一个任务,我们可以看到Hive利用MapReduce来完成Job。
可以认为Hive是在分布式文件系统HDFS之上,结合HBase以及MapReduce高度集成的数据仓库,为用户提供了数据存储和访问。
4.附录
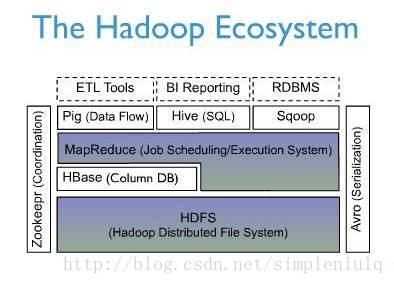
最后引入HBase与Hive在整个hadoop生态系统中的结构图:
还有Hive的原理图:
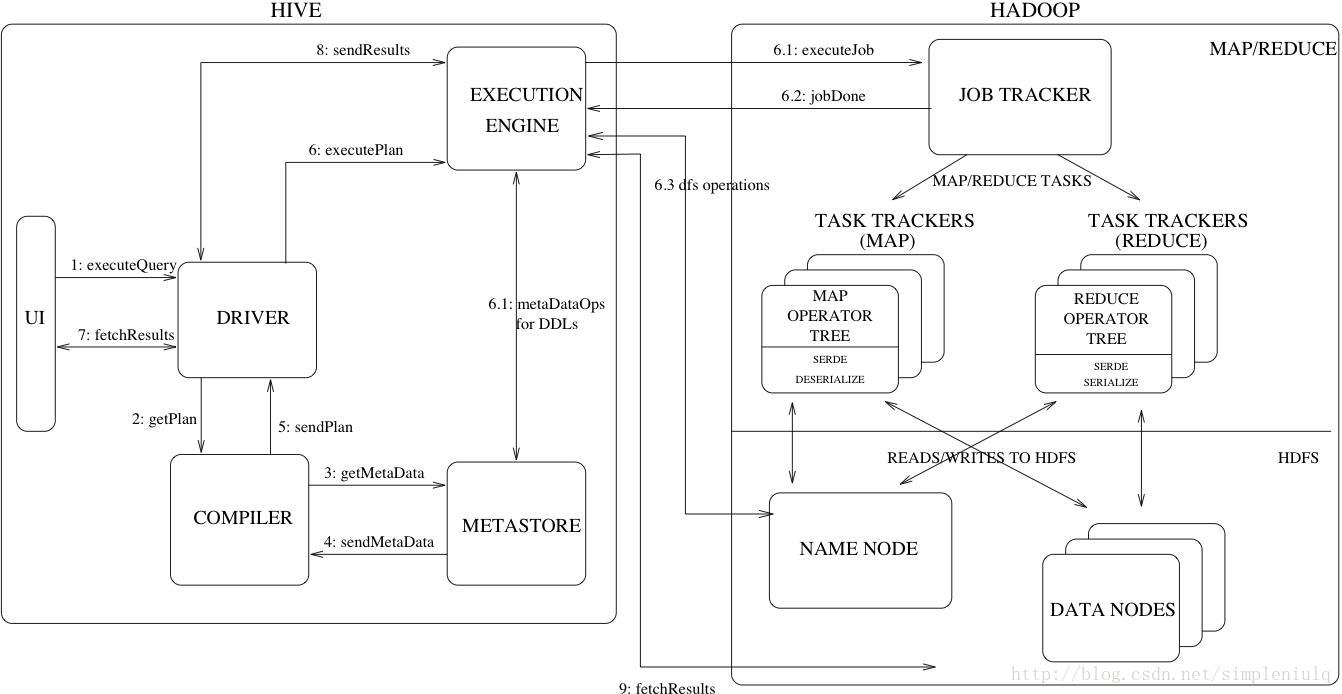
我们可以更加深刻的理解HBase以及Hive。
5.References
部分资料来自黄宜华老师的MapReduce课程ppt以及互联网。在此感谢。














 2114
2114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









