







IOMMU From Wikipedia, the free encyclopedia
In computing, aninput/output memory management unit (IOMMU) is amemory management unit (MMU) that connects a DMA-capable I/O bus to the main memory. Like a traditional MMU, which translates CPU-visible virtual addresses to physical addresses, the IOMMU takes care of mapping device-visible virtual addresses (also calleddevice addresses orI/O addresses in this context) to physical addresses. Some units also providememory protection from misbehaving devices.
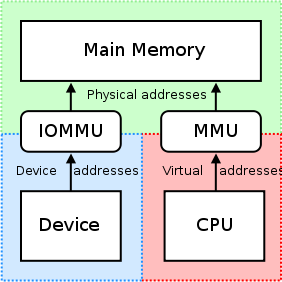
An example IOMMU is the graphics address remapping table (GART) used by AGP and PCI Express graphics cards.
AMD has published a specification for IOMMU technology in the HyperTransport architecture.[1]Intel has published a specification for IOMMU technology as Virtualization Technology for Directed I/O, abbreviatedVT-d.[2] Information about the Sun IOMMU has been published in the Device Virtual Memory Access (DVMA) section of the Solaris Developer Connection.[3] The IBM Translation Control Entry (TCE) has been described in a document entitled Logical Partition Security in the IBMeServerpSeries 690.[4] ThePCI-SIG has relevant work under the terms I/O Virtualization (IOV)[5] and Address Translation Services (ATS).ARM defines its version of IOMMU as System Memory Management Unit (SMMU)[6] to complement its Virtualization architecture.[7]
I/O virtualization is not performed by the CPU, but instead by the chipset.[8]
Contents[hide] |
Advantages [edit]
The advantages of having an IOMMU, compared to direct physical addressing of the memory, include:
- Large regions of memory can be allocated without the need to be contiguous in physical memory — the IOMMU will take care of mapping contiguous virtual addresses to the underlying fragmented physical addresses. Thus, the use ofvectored I/O (scatter-gather lists) can sometimes be avoided.
- For devices that do not support memory addresses long enough to address the entire physical memory, the device can still address the entire memory through the IOMMU. This avoids overhead associated with copying buffers to and from the memory space the peripheral can address.
- For example, as of 2010[update] x86 computers can use more than 4 GiB of memory, enabled by thePAE feature in an x86 processor. Still, an ordinary 32-bit PCI device simply cannot address the memory above the 4 GiB boundary, and thus it cannot perform DMA to it. Without an IOMMU, the operating system would have to implement time-consumingbounce buffers (FreeBSD/Linux) also known asdouble buffers[9] (Windows nomenclature).
- Memory protection from malicious or misbehaving devices: a device cannot read or write to memory that hasn't been explicitly allocated (mapped) for it. The memory protection is based on the fact that OS running on the CPU (see figure) exclusively controls both the MMU and the IOMMU. The devices are physically unable to circumvent or corrupt configured memory management tables.
- With virtualization, guest operating systems can use hardware that is not specifically made for virtualization. Higher performance hardware such as graphics cards useDMA to access memory directly; in a virtual environment all the memory addresses are remapped by the virtual machine software, which causes DMA devices to fail. The IOMMU handles this remapping, allowing for the native device drivers to be used in a guest operating system.
- In some architectures IOMMU also performs hardware interrupt remapping, in a manner similar to standard memory address remapping.
- Peripheral memory paging can be supported by an IOMMU. A peripheral using the PCI-SIG PCIe Address Translation Services (ATS) Page Request Interface (PRI) extension can detect and signal the need for memory manager services.
For system architectures in which port I/O is a distinct address space from the memory address space, an IOMMU is not used when the CPU communicates with devices viaI/O ports. In system architectures in which port I/O and memory are mapped into a suitable address space, an IOMMU can translate port I/O accesses.
Disadvantages [edit]
The disadvantages of having an IOMMU, compared to direct physical addressing of the memory, include:[10]
- Some degradation of performance from translation and management overhead (e.g., page table walks).
- Consumption of physical memory for the added I/O page (translation) tables. This can be mitigated if the tables can be shared with the processor.
IOMMU in relation to virtualization[edit]
When an operating system is running inside a virtual machine, including systems that use paravirtualization, such as Xen, it does not usually know the host-physical addresses of memory that it accesses. This makes providing direct access to the computer hardware difficult, because if the guest OS tried to instruct the hardware to perform adirect memory access (DMA) using guest-physical addresses, it would likely corrupt the memory, as the hardware does not know about the mapping between the guest-physical and host-physical addresses for the given virtual machine. The corruption is avoided because the hypervisor or host OS intervenes in the I/O operation to apply the translations; unfortunately, this delays the I/O operation.
An IOMMU can solve this problem by re-mapping the addresses accessed by the hardware according to the same (or a compatible) translation table that is used to map guest-physical address to host-physical addresses.[11]
See also [edit]
References [edit]
- ^"AMD I/O Virtualization Technology (IOMMU) Specification Revision 1.26". Retrieved 2013-02-28.
- ^"Mainstreaming Server Virtualization: The Intel Approach". Retrieved 2006-03-01.
- ^"DVMA Resources and IOMMU Translations". Retrieved 2007-04-30.
- ^"Logical Partition Security in the IBM eServer pSeries 690". Retrieved 2007-04-30.
- ^"I/O Virtualization specifications". Retrieved 2007-05-01.
- ^"ARM SMMU". Retrieved 2013-05-13.
- ^"ARM Virtualization Extensions". Retrieved 2013-05-13.
- ^Intel platform hardware support for I/O virtualization
- ^"Physical Address Extension — PAE Memory and Windows". Microsoft Windows Hardware Development Central. 2005. Retrieved 2008-04-07.
- ^Muli Ben-Yehuda, Jimi Xenidis, Michal Ostrowski (2007-06-27)."Price of Safety: Evaluating IOMMU Performance" (PDF).Proceedings of the Linux Symposium 2007. Ottawa, Ontario, Canada:IBM Research. Retrieved 2013-02-28.
- ^"Xen FAQ: In DomU, how can I use 3D graphics". Retrieved 2006-12-12.
-
Notes
- Bottomley, James (2004-05-01). "Using DMA". Linux Journal (Specialized Systems Consultants).
IOMMU (ariticle from AMD)
Posted by devcentral on September 1, 2008 in Operating System Research Center with no comments
This article is about AMD’s IOMMU, coming up in future server chipsets, what it does, how it works and why it is important.
What it does
IOMMU stands for I/O Memory Management Unit and works very similar to a processor’s memory management unit. The main difference is that it translates memory accesses performed by devices instead of by the processor, as the MMU already does. This address translation is implemented on a paging based scheme. As with the MMU, it is designed to allow not only implementation of translation, but protection functionality, as well. Another key feature is interrupt remapping.
How it works
Device pass-through
This is the ability to directly assign a physical device to a particular guest OS. The required address space translation is handled transparently. Ideally a device’ address space is the same as a guest’s physical address space; however, in the virtualized case this is hard to achieve without an IOMMU.
If done without IOMMU, our experience has been that it is very fragile, slow and works for paravirtualized OSs only. An IOMMU is designed to allow device pass-through functionality to work even with an unmodified OS. Device isolation is a key feature for increased virtualization performance, with network adapters and GPUs being the devices that benefit most, as they usually have high bandwidth requirements. As a side-effect, devices with 32 bit addressing only can be passed to guests that are physically mapped above 4 GB, to allow DMA transfers for them as well.
Device isolation
An IOMMU is designed to be able to safely map a device to a particular guest without risking the integrity of other guests. A guest should not break out of its address space with rogue DMA traffic. Additionally it is designed to provide an increased amount of security in scenarios without virtualization. Particularly the OS should be able to protect itself from buggy device drivers by limiting a device’s memory accesses.
Remapping of interrupts
Usually sharing device interrupts among several guests is complicated to handle. An IOMMU provides a basis to separate device interrupts that are already shared by different devices. It remaps a shared interrupt to an exclusive vector to ease up its delivery to a particular guest OS.
Why is it important?
In virtualization, there are lots of tricks done to abstract the underlying hardware, but also to minimize virtualization overhead. Using Rapid Virtualization Indexing(tm) instead of shadow page tables for memory management is only one example. The biggest remaining performance gap in today’s virtualization scenario is I/O. An IOMMU helps to bridge this gap and also improves the situation from a security point of view. Last, but not least, it allows hypervisors to be simpler and more robust.
Jörg Rödel & Peter Oruba
The information presented in this blogis for informational purposes only and may contain technical inaccuracies, omissions and typographical errors, and may not represent AMD.
mm: iommu: An API to unify IOMMU, CPU and device memory management
| From: | Zach Pfeffer <zpfeffer@codeaurora.org> | |
| To: | mel@csn.ul.ie | |
| Subject: | [RFC 1/3 v3] mm: iommu: An API to unify IOMMU, CPU and device memory management | |
| Date: | Tue, 6 Jul 2010 08:42:34 -0700 | |
| Cc: | linux-arch@vger.kernel.org, dwalker@codeaurora.org, linux-mm@kvack.org, linux-kernel@vger.kernel.org, linux-arm-msm@vger.kernel.org, linux-omap@vger.kernel.org, Zach Pfeffer <zpfeffer@codeaurora.org> | |
| Archive-link: | Article,Thread |
This patch contains the documentation for the API, termed the Virtual
Contiguous Memory Manager. Its use would allow all of the IOMMU to VM,
VM to device and device to IOMMU interoperation code to be refactored
into platform independent code.
Comments, suggestions and criticisms are welcome and wanted.
Signed-off-by: Zach Pfeffer <zpfeffer@codeaurora.org>
---
Documentation/vcm.txt | 587 +++++++++++++++++++++++++++++++++++++++++++++++++
1 files changed, 587 insertions(+), 0 deletions(-)
create mode 100644 Documentation/vcm.txt
diff --git a/Documentation/vcm.txt b/Documentation/vcm.txt
new file mode 100644
index 0000000..1c6a8be
--- /dev/null
+++ b/Documentation/vcm.txt
@@ -0,0 +1,587 @@
+What is this document about?
+============================
+
+This document covers how to use the Virtual Contiguous Memory Manager
+(VCMM), how the first implementation works with a specific low-level
+Input/Output Memory Management Unit (IOMMU) and the way the VCMM is used
+from user-space. It also contains a section that describes why something
+like the VCMM is needed in the kernel.
+
+If anything in this document is wrong, please send patches to the
+maintainer of this file, listed at the bottom of the document.
+
+
+The Virtual Contiguous Memory Manager
+=====================================
+
+The VCMM was built to solve the system-wide memory mapping issues that
+occur when many bus-masters have IOMMUs.
+
+An IOMMU maps device addresses to physical addresses. It also insulates
+the system from spurious or malicious device bus transactions and allows
+fine-grained mapping attribute control. The Linux kernel core does not
+contain a generic API to handle IOMMU mapped memory; device driver writers
+must implement device specific code to interoperate with the Linux kernel
+core. As the number of IOMMUs increases, coordinating the many address
+spaces mapped by all discrete IOMMUs becomes difficult without in-kernel
+support.
+
+The VCMM API enables device independent IOMMU control, virtual memory
+manager (VMM) interoperation and non-IOMMU enabled device interoperation
+by treating devices with or without IOMMUs and all CPUs with or without
+MMUs, their mapping contexts and their mappings using common
+abstractions. Physical hardware is given a generic device type and mapping
+contexts are abstracted into Virtual Contiguous Memory (VCM)
+regions. Users "reserve" memory from VCMs and "back" their reservations
+with physical memory.
+
+Why the VCMM is Needed
+----------------------
+
+Driver writers who control devices with IOMMUs must contend with device
+control and memory management. Driver writers have a large device driver
+API that they can leverage to control their devices, but they are lacking
+a unified API to help them program mappings into IOMMUs and share those
+mappings with other devices and CPUs in the system.
+
+Sharing is complicated by Linux's CPU-centric VMM. The CPU-centric model
+generally makes sense because average hardware only contains a MMU for the
+CPU and possibly a graphics MMU. If every device in the system has one or
+more MMUs the CPU-centric memory management (MM) programming model breaks
+down.
+
+Abstracting IOMMU device programming into a common API has already begun
+in the Linux kernel. It was built to abstract the difference between AMD
+and Intel IOMMUs to support x86 virtualization on both platforms. The
+interface is listed in include/linux/iommu.h. It contains
+interfaces for mapping and unmapping as well as domain management. This
+interface has not gained widespread use outside the x86; PA-RISC, Alpha
+and SPARC architectures and ARM and PowerPC platforms all use their own
+mapping modules to control their IOMMUs. The VCMM contains an IOMMU
+programming layer, but since its abstraction supports map management
+independent of device control, the layer is not used directly. This
+higher-level view enables a new kernel service, not just an IOMMU
+interoperation layer.
+
+The General Idea: Map Management using Graphs
+---------------------------------------------
+
+Looking at mapping from a system-wide perspective reveals a general graph
+problem. The VCMM's API is built to manage the general mapping graph. Each
+node that talks to memory, either through an MMU or directly (physically
+mapped) can be thought of as the device-end of a mapping edge. The other
+edge is the physical memory (or intermediate virtual space) that is
+mapped.
+
+In the direct-mapped case the device is assigned a one-to-one MMU. This
+scheme allows direct mapped devices to participate in general graph
+management.
+
+The CPU nodes can also be brought under the same mapping abstraction with
+the use of a light overlay on the existing VMM. This light overlay allows
+VMM-managed mappings to interoperate with the common API. The light
+overlay enables this without substantial modifications to the existing
+VMM.
+
+In addition to CPU nodes that are running Linux (and the VMM), remote CPU
+nodes that may be running other operating systems can be brought into the
+general abstraction. Routing all memory management requests from a remote
+node through the central memory management framework enables new features
+like system-wide memory migration. This feature may only be feasible for
+large buffers that are managed outside of the fast-path, but having remote
+allocation in a system enables features that are impossible to build
+without it.
+
+The fundamental objects that support graph-based map management are:
+
+1) Virtual Contiguous Memory Regions
+
+2) Reservations
+
+3) Associated Virtual Contiguous Memory Regions
+
+4) Memory Targets
+
+5) Physical Memory Allocations
+
+Usage Overview
+--------------
+
+In a nutshell, users allocate Virtual Contiguous Memory Regions and
+associate those regions with one or more devices by creating an Associated
+Virtual Contiguous Memory Region. Users then create Reservations from the
+Virtual Contiguous Memory Region. At this point no physical memory has
+been committed to the reservation. To associate physical memory with a
+reservation a Physical Memory Allocation is created and the Reservation is
+backed with this allocation.
+
+include/linux/vcm.h includes comments documenting each API.
+
+Virtual Contiguous Memory Regions
+---------------------------------
+
+A Virtual Contiguous Memory Region (VCM) abstracts the memory space a
+device sees. The addresses of the region are only used by the devices
+which are associated with the region. This address space would normally be
+implemented as a device page table.
+
+A VCM is created and destroyed with three functions:
+
+ struct vcm *vcm_create(unsigned long start_addr, unsigned long len);
+
+ struct vcm *vcm_create_from_prebuilt(size_t ext_vcm_id);
+
+ int vcm_free(struct vcm *vcm);
+
+start_addr is an offset into the address space where allocations will
+start from. len is the length from start_addr of the VCM. Both functions
+generate an instance of a VCM.
+
+ext_vcm_id is used to pass a request to the VMM to generate a VCM
+instance. In the current implementation the call simply makes a note that
+the VCM instance is a VMM VCM instance for other interfaces usage. This
+muxing is seen throughout the implementation.
+
+vcm_create() and vcm_create_from_prebuilt() produce VCM instances for
+virtually mapped devices (IOMMUs and CPUs). To create a one-to-one mapped
+VCM, users pass the start_addr and len of the physical region. The VCMM
+matches this and records that the VCM instance is a one-to-one VCM.
+
+The newly created VCM instance can be passed to any function that needs to
+operate on or with a virtual contiguous memory region. Its main attributes
+are a start_addr and a len as well as an internal setting that allows the
+implementation to mux between true virtual spaces, one-to-one mapped
+spaces and VMM managed spaces.
+
+The current implementation uses the genalloc library to manage the VCM for
+IOMMU devices. Return values and more in-depth per-function documentation
+for these and the ones listed below are in include/linux/vcm.h.
+
+Reservations
+------------
+
+A Reservation is a contiguous region allocated from a VCM. There is no
+physical memory associated with it.
+
+A Reservation is created and destroyed with:
+
+ struct res *vcm_reserve(struct vcm *vcm, size_t len, u32 attr);
+
+ int vcm_unreserve(struct res *res);
+
+A vcm is a VCM created above. len is the length of the request. It can be
+up to the length of the VCM region the reservation is being created
+from. attr are mapping attributes: read, write, execute, user, supervisor,
+secure, not-cached, write-back/write-allocate, write-back/no
+write-allocate, write-through. These attrs are appropriate for ARM but can
+be changed to match to any architecture.
+
+The implementation calls gen_pool_alloc() for IOMMU devices,
+alloc_vm_area() for VMM areas and is a pass-through for one-to-one mapped
+areas.
+
+Associated Virtual Contiguous Memory Regions and Activation
+-----------------------------------------------------------
+
+An Associated Virtual Contiguous Memory Region (AVCM) is a mapping of a
+VCM to a device. The mapping can be active or inactive.
+
+An AVCM is managed with:
+
+ struct avcm *vcm_assoc(struct vcm *vcm, struct device *dev, u32 attr);
+
+ int vcm_deassoc(struct avcm *avcm);
+
+ int vcm_activate(struct avcm *avcm);
+
+ int vcm_deactivate(struct avcm *avcm);
+
+A VCM instance is a VCM created above. A dev is an opaque device handle
+thats passed down to the device driver the VCMM muxes in to handle a
+request. attr are association attributes: split, use-high or
+use-low. split controls which transactions hit a high-address page-table
+and which transactions hit a low-address page-table. For instance, all
+transactions whose most significant address bit is one would use the
+high-address page-table, any other transaction would use the low address
+page-table. This scheme is ARM-specific and could be changed in other
+architectures. One VCM instance can be associated with many devices and
+many VCM instances can be associated with one device.
+
+An AVCM is only a link. To program and deprogram a device with a VCM the
+user calls vcm_activate() and vcm_deactivate(). For IOMMU devices,
+activating a mapping programs the base address of a page table into an
+IOMMU. For VMM and one-to-one based devices, mappings are active
+immediately but the API does require an activation call for them for
+internal reference counting.
+
+Memory Targets
+--------------
+
+A Memory Target is a platform independent way of specifying a physical
+pool; it abstracts a pool of physical memory. The physical memory pool may
+be physically discontiguous, need to be allocated from in a unique way or
+have other user-defined attributes.
+
+Physical Memory Allocation and Reservation Backing
+--------------------------------------------------
+
+Physical memory is allocated as a separate step from reserving
+memory. This allows multiple reservations to back the same physical
+memory.
+
+A Physical Memory Allocation is managed using the following functions:
+
+ struct physmem *vcm_phys_alloc(enum memtype_t memtype,
+ size_t len, u32 attr);
+
+ int vcm_phys_free(struct physmem *physmem);
+
+ int vcm_back(struct res *res, struct physmem *physmem);
+
+ int vcm_unback(struct res *res);
+
+attr can include an alignment request, a specification to map memory using
+various block sizes and/or to use physically contiguous memory. memtype is
+one of the memory types listed in Memory Targets.
+
+The current implementation manages two pools of memory. One pool is a
+contiguous block of memory and the other is a set of contiguous block
+pools. In the current implementation the block pools contain 4K, 64K and
+1M blocks. The physical allocator does not try to split blocks from the
+contiguous block pools to satisfy requests.
+
+The use of 4K, 64K and 1M blocks solves a problem with some IOMMU
+hardware. IOMMUs are placed in front of multimedia engines to provide a
+contiguous address space to the device. Multimedia devices need large
+buffers and large buffers may map to a large number of physical
+blocks. IOMMUs tend to have small translation lookaside buffers
+(TLBs). Since the TLB is small the number of physical blocks that map a
+given range needs to be small or else the IOMMU will continually fetch new
+translations during a typical streamed multimedia flow. By using a 1 MB
+mapping (or 64K mapping) instead of a 4K mapping the number of misses can
+be minimized, allowing the multimedia block to meet its performance goals.
+
+Low Level Control
+-----------------
+
+It is necessary in some instances to access attributes and provide
+higher-level control of the low-level hardware abstraction. The API
+contains many members and functions for this task but the two that are
+typically used are:
+
+ res->dev_addr;
+
+ int vcm_hook(struct device *dev, vcm_handler handler, void *data);
+
+res->dev_addr is the device address given a reservation. This device
+address is a virtual IOMMU address for reservations on IOMMU VCMs, a
+virtual VMM address for reservations on VMM VCMs and a virtual (really
+physical since its one-to-one mapped) address for one-to-one devices.
+
+The function, vcm_hook, allows a caller in the kernel to register a
+user_handler. The handler is passed the data member passed to vcm_hook
+during a fault. The user can return 1 to indicate that the underlying
+driver should handle the fault and retry the transaction or they can
+return 0 to halt the transaction. If the user doesn't register a
+handler the low-level driver will print a warning and terminate the
+transaction.
+
+A Detailed Walk Through
+-----------------------
+
+The following call sequence walks through a typical allocation
+sequence. In the first stage the memory for a device is reserved and
+backed. This occurs without mapping the memory into a VMM VCM region. The
+second stage maps the first VCM region into a VMM VCM region so the kernel
+can read or write it. The second stage is not necessary if the VMM does
+not need to read or modify the contents of the original mapping.
+
+ Stage 1: Map and Allocate Memory for a Device
+
+ The call sequence starts by creating a VCM region:
+
+ vcm = vcm_create(start_addr, len);
+
+ The next call associates a VCM region with a device:
+
+ avcm = vcm_assoc(vcm, dev, attr);
+
+ To activate the association, users call vcm_activate() on the avcm from
+ the associate call. This programs the underlining device with the
+ mappings.
+
+ ret = vcm_activate(avcm);
+
+ Once a VCM region is created and associated it can be reserved from
+ with:
+
+ res = vcm_reserve(vcm, res_len, res_attr);
+
+ A user then allocates physical memory with:
+
+ physmem = vcm_phys_alloc(memtype, len, phys_attr);
+
+ To back the reservation with the physical memory allocation the user
+ calls:
+
+ vcm_back(res, physmem);
+
+
+ Stage 2: Map the Device's Memory into the VMM's VCM region
+
+ If the VMM needs to read and/or write the region that was just created,
+ the following calls are made.
+
+ The first call creates a prebuilt VCM with:
+
+ vcm_vmm = vcm_from_prebuilt(ext_vcm_id);
+
+ The prebuilt VCM is associated with the CPU device and activated with:
+
+ avcm_vmm = vcm_assoc(vcm_vmm, dev_cpu, attr);
+ vcm_activate(avcm_vmm);
+
+ A reservation is made on the VMM VCM with:
+
+ res_vmm = vcm_reserve(vcm_vmm, res_len, attr);
+
+ Finally, once the topology has been set up a vcm_back() allows the VMM
+ to read the memory using the physmem generated in stage 1:
+
+ vcm_back(res_vmm, physmem);
+
+Mapping IOMMU, one-to-one and VMM Reservations
+----------------------------------------------
+
+The following example demonstrates mapping IOMMU, one-to-one and VMM
+reservations to the same physical memory. It shows the use of phys_addr
+and phys_size to create a contiguous VCM for one-to-one mapped devices.
+
+ The user allocates physical memory:
+
+ physmem = vcm_phys_alloc(memtype, SZ_2MB + SZ_4K, CONTIGUOUS);
+
+ Creates an IOMMU VCM:
+
+ vcm_iommu = vcm_create(SZ_1K, SZ_16M);
+
+ Creates a one-to-one VCM:
+
+ vcm_onetoone = vcm_create(phys_addr, phys_size);
+
+ Creates a Prebuit VCM:
+
+ vcm_vmm = vcm_from_prebuit(ext_vcm_id);
+
+ Associate and activate all three to their respective devices:
+
+ avcm_iommu = vcm_assoc(vcm_iommu, dev_iommu, attr0);
+ avcm_onetoone = vcm_assoc(vcm_onetoone, dev_onetoone, attr1);
+ avcm_vmm = vcm_assoc(vcm_vmm, dev_cpu, attr2);
+ vcm_activate(avcm_iommu);
+ vcm_activate(avcm_onetoone);
+ vcm_activate(avcm_vmm);
+
+ Associations that fail return 0.
+
+ And finally, creates and backs reservations on all 3 such that they
+ all point to the same memory:
+
+ res_iommu = vcm_reserve(vcm_iommu, SZ_2MB + SZ_4K, attr);
+ res_onetoone = vcm_reserve(vcm_onetoone, SZ_2MB + SZ_4K, attr);
+ res_vmm = vcm_reserve(vcm_vmm, SZ_2MB + SZ_4K, attr);
+ vcm_back(res_iommu, physmem);
+ vcm_back(res_onetoone, physmem);
+ vcm_back(res_vmm, physmem);
+
+ Like associations, reservations that fail return 0.
+
+VCM Summary
+-----------
+
+The VCMM is an attempt to abstract attributes of three distinct classes of
+mappings into one API. The VCMM allows users to reason about mappings as
+first class objects. It also allows memory mappings to flow from the
+traditional 4K mappings prevalent on systems today to more efficient block
+sizes. Finally, it allows users to manage mapping interoperation without
+becoming VMM experts. These features will allow future systems with many
+MMU mapped devices to interoperate simply and therefore correctly.
+
+
+IOMMU Hardware Control
+======================
+
+The VCM currently supports a single type of IOMMU, a Qualcomm System MMU
+(SMMU). The SMMU interface contains functions to map and unmap virtual
+addresses, perform address translations and initialize hardware. A
+Qualcomm SMMU can contain multiple MMU contexts. Each context can
+translate in parallel. All contexts in a SMMU share one global translation
+look-aside buffer (TLB).
+
+To support context muxing the SMMU module creates and manages device
+independent virtual contexts. These context abstractions are bound to
+actual contexts at run-time. Once bound, a context can be activated. This
+activation programs the underlying context with the virtual context
+affecting a context switch.
+
+The following functions are all documented in:
+
+ arch/arm/mach-msm/include/mach/smmu_driver.h.
+
+Mapping
+-------
+
+To map and unmap a virtual page into physical space the VCM calls:
+
+ int smmu_map(struct smmu_dev *dev, unsigned long pa,
+ unsigned long va, unsigned long len, unsigned int attr);
+
+ int smmu_unmap(struct smmu_dev *dev, unsigned long va,
+ unsigned long len);
+
+ int smmu_update_start(struct smmu_dev *dev);
+
+ int smmu_update_done(struct smmu_dev *dev);
+
+The size given to map must be 4K, 64K, 1M or 16M and the VA and PA must be
+aligned to the given size. smmu_update_start() and smmu_update_done()
+should be called before and after each map or unmap.
+
+Translation
+-----------
+
+To request a hardware VA to PA translation on a single address the VCM
+calls:
+
+ unsigned long smmu_translate(struct smmu_dev *dev,
+ unsigned long va);
+
+Fault Handling
+--------------
+
+To register an interrupt handler for a context the VCM calls:
+
+ int smmu_hook_interrupt(struct smmu_dev *dev, vcm_handler handler,
+ void *data);
+
+The registered interrupt handler should return 1 if it wants the SMMU
+driver to retry the transaction again and 0 if it wants the SMMU driver to
+terminate the transaction.
+
+Managing SMMU Initialization and Contexts
+-----------------------------------------
+
+SMMU hardware initialization and management happens in 2 steps. The first
+step initializes global SMMU devices and abstract device contexts. The
+second step binds contexts and devices.
+
+An SMMU hardware instance is built with:
+
+ int smmu_drvdata_init(struct smmu_driver *drv, unsigned long base,
+ int irq);
+
+An SMMU context is initialized and deinitialized with:
+
+ struct smmu_dev *smmu_ctx_init(int ctx);
+ int smmu_ctx_deinit(struct smmu_dev *dev);
+
+An abstract SMMU context is bound to a particular SMMU with:
+
+ int smmu_ctx_bind(struct smmu_dev *ctx, struct smmu_driver *drv);
+
+Activation
+----------
+
+Activation affects a context switch.
+
+Activation, deactivation and activation state testing are done with:
+
+ int smmu_activate(struct smmu_dev *dev);
+ int smmu_deactivate(struct smmu_dev *dev);
+ int smmu_is_active(struct smmu_dev *dev);
+
+
+Userspace Access to Devices with IOMMUs
+=======================================
+
+A device that issues transactions through an IOMMU must work with two
+APIs. The first API is the VCM. The VCM API is device independent. Users
+pass the VCM a dev_id and the VCM makes calls on the hardware device it
+has been configured with using this dev_id. The second API is whatever
+device topology has been created to organize the particular IOMMUs in a
+system. The only constraint on this second API is that it must give the
+user a single dev_id that it can pass through the VCM.
+
+For the Qualcomm SMMUs the second API consists of a tree of platform
+devices and two platform drivers as well as a context lookup function that
+traverses the device tree and returns a dev_id given a context name.
+
+Qualcomm SMMU Device Tree
+-------------------------
+
+The current tree organizes the devices into a tree that looks like the
+following:
+
+smmu/
+ smmu0/
+ ctx0
+ ctx1
+ ctx2
+ smmu1/
+ ctx3
+
+
+Each context, ctx[n] and each smmu, smmu[n] is given a name. Since users
+are interested in contexts not smmus, the context name is passed to a
+function to find the dev_id associated with that name. The functions to
+find, free and get the base address (since the device probe function calls
+ioremap to map the SMMUs configuration registers into the kernel) are
+listed here:
+
+ struct smmu_dev *smmu_get_ctx_instance(char *ctx_name);
+ int smmu_free_ctx_instance(struct smmu_dev *dev);
+ unsigned long smmu_get_base_addr(struct smmu_dev *dev);
+
+Documentation for these functions is in:
+
+ arch/arm/mach-msm/include/mach/smmu_device.h
+
+Each context is given a dev node named after the context. For example:
+
+ /dev/vcodec_a_mm1
+ /dev/vcodec_b_mm2
+ /dev/vcodec_stream
+ etc...
+
+Users open, close and mmap these nodes to access VCM buffers from
+userspace in the same way that they used to open, close and mmap /dev
+nodes that represented large physically contiguous buffers (called PMEM
+buffers on Android).
+
+Example
+-------
+
+An abbreviated example is shown here:
+
+Users get the dev_id associated with their target context, create a VCM
+topology appropriate for their device and finally associate the VCMs of
+the topology with the contexts that will take the VCMs:
+
+ dev_id = smmu_get_ctx_instance(vcodec_a_stream);
+
+create vcm and needed topology
+
+ avcm = vcm_assoc(vcm, dev_id, attr);
+
+Tying it all Together
+---------------------
+
+VCMs, IOMMUs and the device tree all work to support system-wide memory
+mappings. The use of each API in this system allows users to concentrate
+on the relevant details without needing to worry about low-level
+details. The API's clear separation of memory spaces and the devices that
+support those memory spaces continues the Linux tradition of abstracting the
+what from the how.
+
+
+Maintainer: Zach Pfeffer <zpfeffer@codeaurora.org>
--
1.7.0.2
--
Sent by an employee of the Qualcomm Innovation Center, Inc.
The Qualcomm Innovation Center, Inc. is a member of the Code Aurora Forum.
| 1 | Linux IOMMU Support |
| 2 | =================== |
| 3 | |
| 4 | The architecture spec can be obtained from the below location. |
| 5 | |
| 6 | http://www.intel.com/technology/virtualization/ |
| 7 | |
| 8 | This guide gives a quick cheat sheet for some basic understanding. |
| 9 | |
| 10 | Some Keywords |
| 11 | |
| 12 | DMAR - DMA remapping |
| 13 | DRHD - DMA Engine Reporting Structure |
| 14 | RMRR - Reserved memory Region Reporting Structure |
| 15 | ZLR - Zero length reads from PCI devices |
| 16 | IOVA - IO Virtual address. |
| 17 | |
| 18 | Basic stuff |
| 19 | ----------- |
| 20 | |
| 21 | ACPI enumerates and lists the different DMA engines in the platform, and |
| 22 | device scope relationships between PCI devices and which DMA engine controls |
| 23 | them. |
| 24 | |
| 25 | What is RMRR? |
| 26 | ------------- |
| 27 | |
| 28 | There are some devices the BIOS controls, for e.g USB devices to perform |
| 29 | PS2 emulation. The regions of memory used for these devices are marked |
| 30 | reserved in the e820 map. When we turn on DMA translation, DMA to those |
| 31 | regions will fail. Hence BIOS uses RMRR to specify these regions along with |
| 32 | devices that need to access these regions. OS is expected to setup |
| 33 | unity mappings for these regions for these devices to access these regions. |
| 34 | |
| 35 | How is IOVA generated? |
| 36 | --------------------- |
| 37 | |
| 38 | Well behaved drivers call pci_map_*() calls before sending command to device |
| 39 | that needs to perform DMA. Once DMA is completed and mapping is no longer |
| 40 | required, device performs a pci_unmap_*() calls to unmap the region. |
| 41 | |
| 42 | The Intel IOMMU driver allocates a virtual address per domain. Each PCIE |
| 43 | device has its own domain (hence protection). Devices under p2p bridges |
| 44 | share the virtual address with all devices under the p2p bridge due to |
| 45 | transaction id aliasing for p2p bridges. |
| 46 | |
| 47 | IOVA generation is pretty generic. We used the same technique as vmalloc() |
| 48 | but these are not global address spaces, but separate for each domain. |
| 49 | Different DMA engines may support different number of domains. |
| 50 | |
| 51 | We also allocate guard pages with each mapping, so we can attempt to catch |
| 52 | any overflow that might happen. |
| 53 | |
| 54 | |
| 55 | Graphics Problems? |
| 56 | ------------------ |
| 57 | If you encounter issues with graphics devices, you can try adding |
| 58 | option intel_iommu=igfx_off to turn off the integrated graphics engine. |
| 59 | |
| 60 | If it happens to be a PCI device included in the INCLUDE_ALL Engine, |
| 61 | then try enabling CONFIG_DMAR_GFX_WA to setup a 1-1 map. We hear |
| 62 | graphics drivers may be in process of using DMA api's in the near |
| 63 | future and at that time this option can be yanked out. |
| 64 | |
| 65 | Some exceptions to IOVA |
| 66 | ----------------------- |
| 67 | Interrupt ranges are not address translated, (0xfee00000 - 0xfeefffff). |
| 68 | The same is true for peer to peer transactions. Hence we reserve the |
| 69 | address from PCI MMIO ranges so they are not allocated for IOVA addresses. |
| 70 | |
| 71 | |
| 72 | Fault reporting |
| 73 | --------------- |
| 74 | When errors are reported, the DMA engine signals via an interrupt. The fault |
| 75 | reason and device that caused it with fault reason is printed on console. |
| 76 | |
| 77 | See below for sample. |
| 78 | |
| 79 | |
| 80 | Boot Message Sample |
| 81 | ------------------- |
| 82 | |
| 83 | Something like this gets printed indicating presence of DMAR tables |
| 84 | in ACPI. |
| 85 | |
| 86 | ACPI: DMAR (v001 A M I OEMDMAR 0x00000001 MSFT 0x00000097) @ 0x000000007f5b5ef0 |
| 87 | |
| 88 | When DMAR is being processed and initialized by ACPI, prints DMAR locations |
| 89 | and any RMRR's processed. |
| 90 | |
| 91 | ACPI DMAR:Host address width 36 |
| 92 | ACPI DMAR:DRHD (flags: 0x00000000)base: 0x00000000fed90000 |
| 93 | ACPI DMAR:DRHD (flags: 0x00000000)base: 0x00000000fed91000 |
| 94 | ACPI DMAR:DRHD (flags: 0x00000001)base: 0x00000000fed93000 |
| 95 | ACPI DMAR:RMRR base: 0x00000000000ed000 end: 0x00000000000effff |
| 96 | ACPI DMAR:RMRR base: 0x000000007f600000 end: 0x000000007fffffff |
| 97 | |
| 98 | When DMAR is enabled for use, you will notice.. |
| 99 | |
| 100 | PCI-DMA: Using DMAR IOMMU |
| 101 | |
| 102 | Fault reporting |
| 103 | --------------- |
| 104 | |
| 105 | DMAR:[DMA Write] Request device [00:02.0] fault addr 6df084000 |
| 106 | DMAR:[fault reason 05] PTE Write access is not set |
| 107 | DMAR:[DMA Write] Request device [00:02.0] fault addr 6df084000 |
| 108 | DMAR:[fault reason 05] PTE Write access is not set |
| 109 | |
| 110 | TBD |
| 111 | ---- |
| 112 | |
| 113 | - For compatibility testing, could use unity map domain for all devices, just |
| 114 | provide a 1-1 for all useful memory under a single domain for all devices. |
| 115 | - API for paravirt ops for abstracting functionality for VMM folks. |
Another article about The Virtual Contiguous Memory Manager from Qualcomm Innovation Center (QuIC)
https://www.kernel.org/doc/ols/2010/ols2010-pages-225-230.pdf















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









