









在Lucene对文本进行处理的过程中,可以大致分为三大部分:
1、索引文件:提取文档内容并分析,生成索引
2、搜索内容:搜索索引内容,根据搜索关键字得出搜索结果
3、分析内容:对搜索词汇进行分析,生成Quey对象。
索引文件
基本步骤如下:
1、创建索引库IndexWriter
2、根据文件创建文档Document
3、向索引库中写入文档内容
package org.algorithm;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/*
* lucene索引的建立
* */
public class IndexFiles {
//创建索引库IndexWriter
public static IndexWriter getIndexWriter(String indexPath) throws IOException{
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
Directory dir = FSDirectory.open(new File(indexPath));
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer);
IndexWriter writer = new IndexWriter(dir, config);
return writer;
}
//根据文件创建文档Document
public static void index(IndexWriter writer) throws IOException{
Document doc = new Document();
//向索引库中写入文档内容
doc.add(new StringField("id", "1",Store.YES));
doc.add(new StringField("name", "lina", Store.YES));
doc.add(new StringField("content", "love you", Store.YES));
writer.addDocument(doc);//添加进写入流里
writer.forceMerge(1);//优化压缩段,大规模添加数据的时候才使用
writer.commit();//提交数据
System.out.println("索引添加成功!");
}
public static void main(String[] args) throws IOException {
String indexPath = "E:/LucenePath";
IndexWriter writer = getIndexWriter(indexPath);
index(writer);
}
}
Luke查看Lucene索引:
1、Luke的使用
下载Luke,这里下载的是lukeall-4.0.0.jar
使用方法:
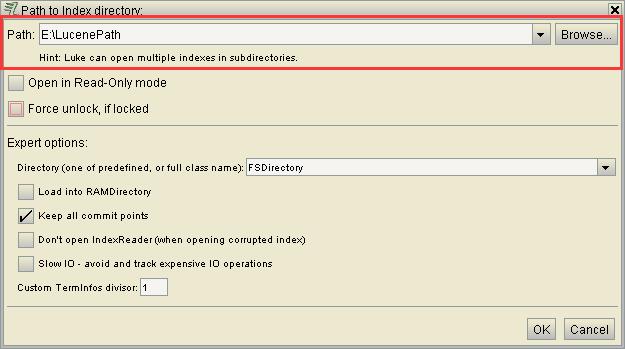
下载完luke后直接放在某个盘符下然后可以在cmd窗口找到luke工具所在的盘符根路径下,使用 java -jar luke.jar 就可以启动了,有的luke工具直接双击运行就可以启动,使用时候两种方式都可以试一下,启动之后,点击Browser按钮,找到你的索引路径点OK,即可显示你索引的内容。
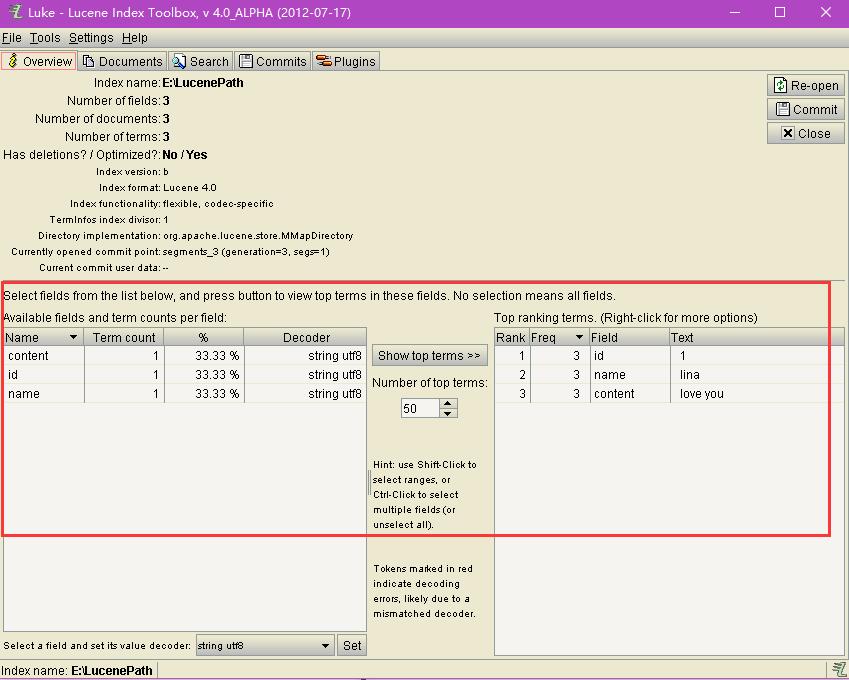
overview界面是用来进行索引的一般性查看和操作的,比如索引目录,域信息,版本,term信息,Rank排名等信息。注意,索引文件里Analyze却不Store的字段信息还是不可见的,也就是只能看STORE了的内容。
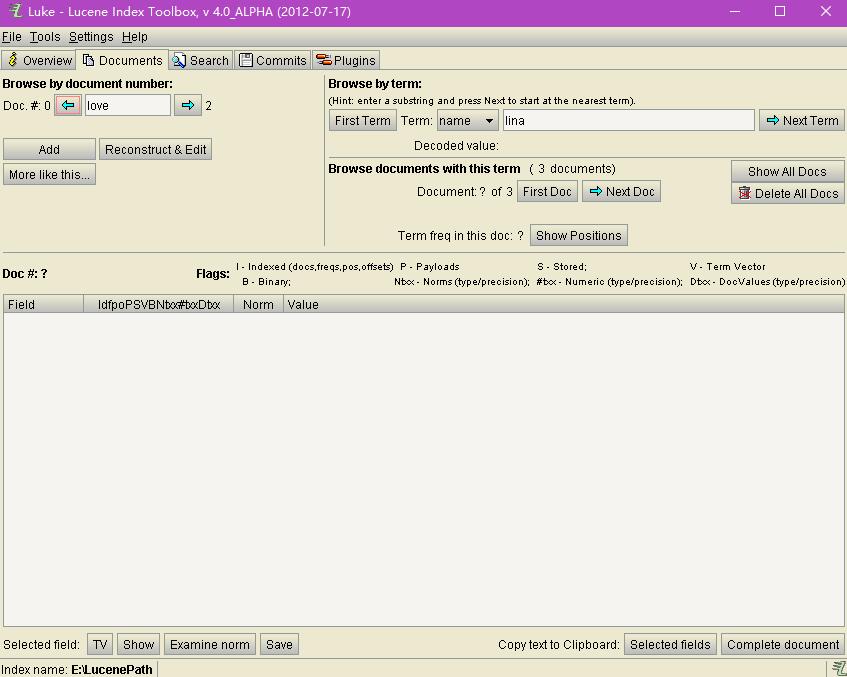
documents界面是用来进行文档的操作和查看的,能根据文档编号和词进行查找,其实这个就是搜索功能。
search界面是可以进行索引的搜索测试,可以编写lucene搜索语句,看到语句解析后的query树,还可以选择进行搜索的分词器、默认字段和重复搜索次数,然后下面的listview中就会列出一个搜索的的文档的所有保存的(store)字段的值,可以看到查询花费的时间。
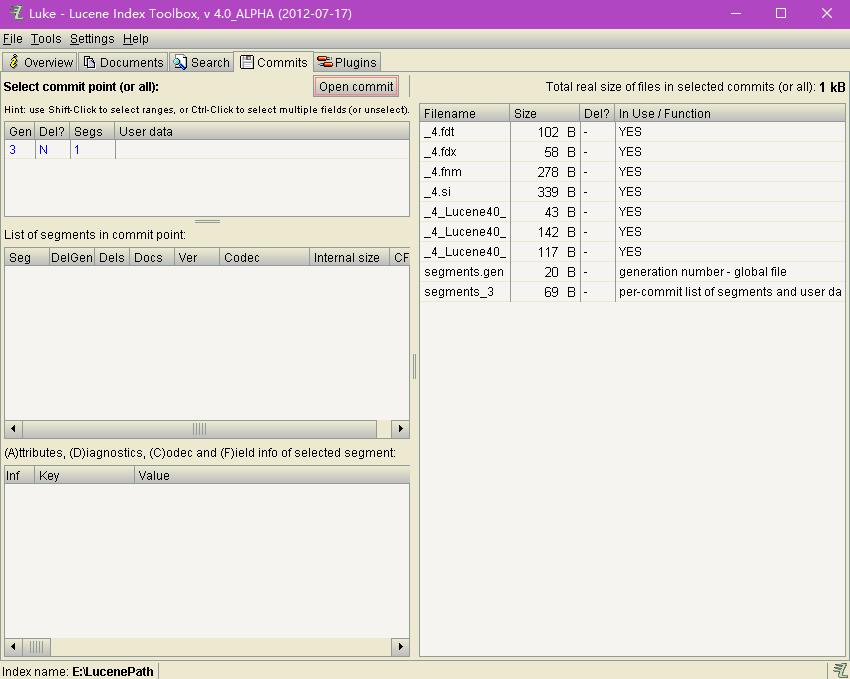
file界面,故名思义,这个就是用来查看每个索引相关文件的一些属性的界面,具体的话,可以通过这个界面分析下索引文件的多少,是否需要优化或者合并等等
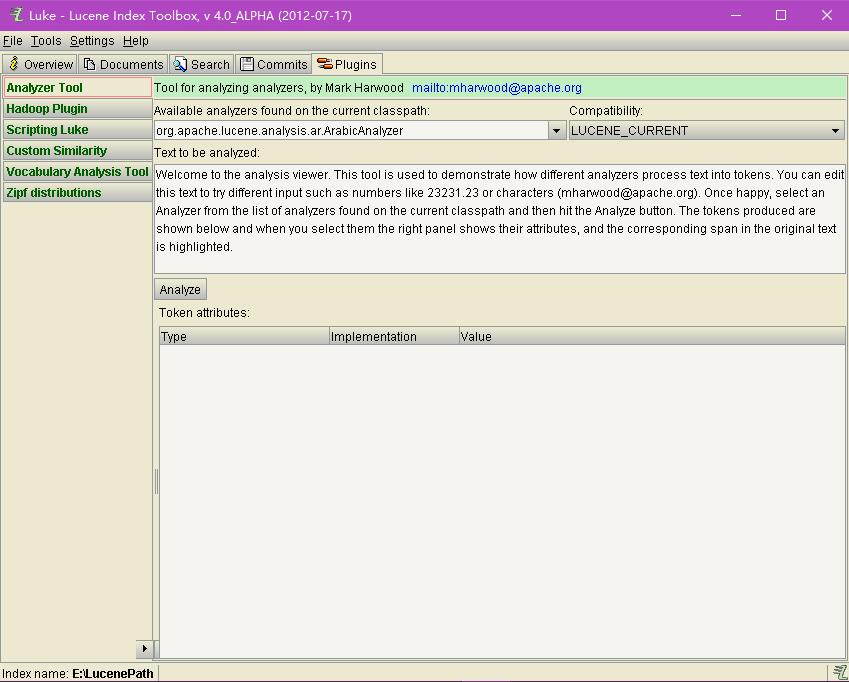
plugins界面,就是可以看到luke提供的各种插件。比较有用的还是分词工具,提供一个分词的类,然后下面文本框输入一段文本,然后就可以让这个工具帮你分词,你可以看到详细的分词信息,对自定义分词器的调试或者测试。还有一个hadoop插件,支持从hadoop节点中获取节点中文件的相关信息,对分布式搜索引擎搭建有用,算是支持多平台的lucene索引文件块的查看。
最后,还可以将lukeall-4.0.0.jar导入到ecplise中,查看源码进行分析其功能特点。















 3333
3333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









