







准确率和召回率是用于信息检索和统计学分类领域的两个度量值,用于评价结果的质量,在机器学习中对于数据进行预测的过程中,同样的使用这些指标来评价预测的结果的质量。
准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;
召回率是指检索出的相关文档数和文档库中的所有的相关文档数的比率,衡量的是检索系统的查全率。
1. 正确率 = 正确识别的个体总数 / 识别出的个体总数
2. 召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
3. F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
预测值与实际值之间的差异:
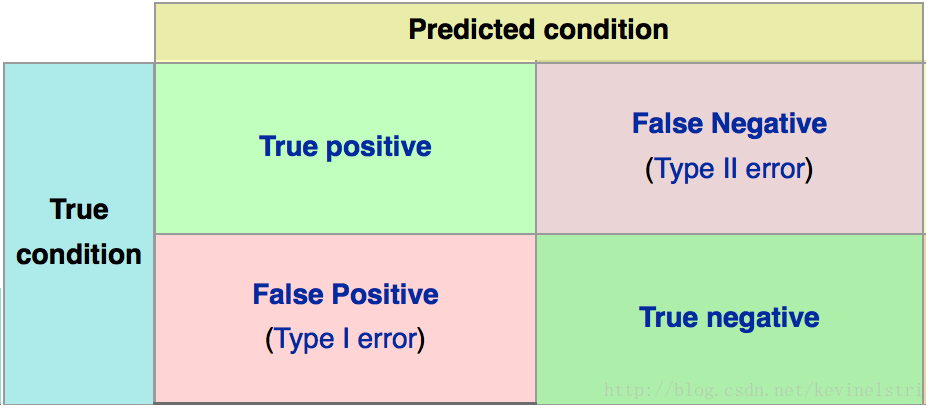
假设原始样本中有两类,其中:
1:总共有 P个类别为1的样本,假设类别1为正例。
2:总共有N个类别为0 的样本,假设类别0为负例。
经过分类后:
3:有 TP个类别为1 的样本被系统正确判定为类别1,FN 个类别为1 的样本被系统误判定为类别 0,显然有P=TP+FN;
4:有 FP 个类别为0 的样本被系统误判断定为类别1,TN 个类别为0 的样本被系统正确判为类别 0,显然有N=FP+TN;
精确度(Precision):
P = TP/(TP+FP) ; 反映了被分类器判定的正例中真正的正例样本的比重。
准确率(Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN); 反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负 。
召回率(Recall),也称为 True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; 反映了被正确判定的正例占总的正例的比重 。
F-measure or balanced F-score
F = 2 * 召回率 * 准确率/ (召回率+准确率);这就是传统上通常说的F1 measure。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









