










文章转自:时空上下文视觉跟踪(STC)算法的解读与代码复现,作者:zouxy09@qq.com
本博文主要是关注一篇视觉跟踪的论文。这篇论文是Kaihua Zhang等人今年投稿到一个会议的文章,因为会议还没有出结果,所以作者还没有发布他的Matlab源代码。但为了让我们先睹为快,作者把论文放在arxiv这个网站上面供大家下载了。对于里面所描述的神奇的效果,大家都跃跃欲试,也有人将其复现了。我这里也花了一天的时间去复现了单尺度的C++版本,主要是基于OpenCV。多尺度的有点复杂,这个后面再做考虑了。另外,能力有限,论文解读和代码实现可能会出现错误,所以如果代码里面出现错误,还望大家不吝指点。
论文见:
Kaihua Zhang, Lei Zhang, Ming-Hsuan Yang,and David Zhang, Fast Trackingvia Spatio-Temporal Context Learning
目前作者已公开了支持多尺度的Matlab代码了哦。可以到以下网址下载:
http://www4.comp.polyu.edu.hk/~cslzhang/STC/STC.htm
一、概述
该论文提出一种简单却非常有效的视觉跟踪方法。更迷人的一点是,它速度很快,原作者实现的Matlab代码在i7的电脑上达到350fps。
该论文的关键点是对时空上下文(Spatio-Temporal Context)信息的利用。主要思想是通过贝叶斯框架对要跟踪的目标和它的局部上下文区域的时空关系进行建模,得到目标和其周围区域低级特征的统计相关性。然后综合这一时空关系和生物视觉系统上的focus of attention特性来评估新的一帧中目标出现位置的置信图,置信最大的位置就是我们得到的新的一帧的目标位置。另外,时空模型的学习和目标的检测都是通过FFT(傅里叶变换)来实现,所以学习和检测的速度都比较快。
二、工作过程
具体过程见下图:
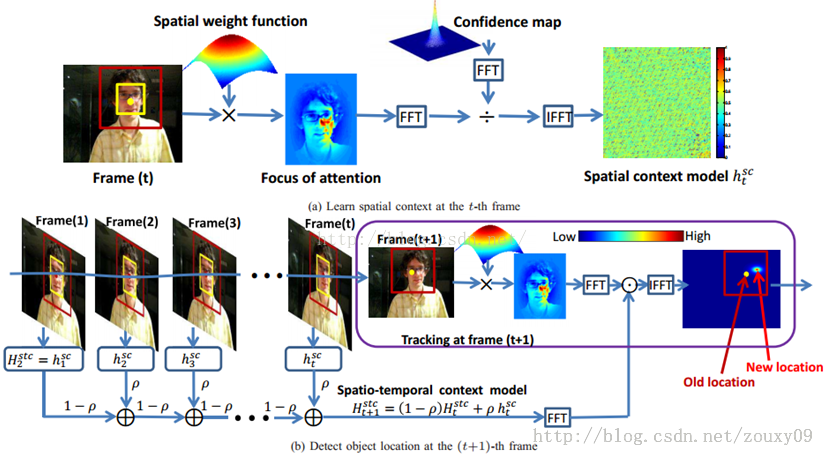
(1)t帧:在该帧目标(第一帧由人工指定)已经知道的情况下,我们计算得到一个目标的置信图(Confidence Map,也就是目标的似然)。通过生物视觉系统上的focus of attention特性我们可以得到另一张概率图(先验概率)。通过对这两个概率图的傅里叶变换做除再反傅里叶变换,就可以得到建模目标和周围背景的空间相关性的空间上下文模型(条件概率)。然后我们用这个模型去更新跟踪下一帧需要的时空上下文模型(可能这里还不太能理解,看到后面的相关理论分析和算法描述后可能会清晰一点)。
(2)t+1帧:利用t帧的上下文信息(时空上下文模型),卷积图像得到一个目标的置信图,值最大的位置就是我们的目标所在地。或者理解为图像各个地方对该上下文信息的响应,响应最大的地方自然就是满足这个上下文的地方,也就是目标了。
三、相关理论描述
3.1、上下文的重要性
时间和空间上的上下文信息对跟踪来说是非常重要的。虽然对跟踪,我们一直利用了时间上的上下文信息(用t去跟踪t+1等),但对空间上下文信息的利用却比较匮乏。为什么空间上下文信息会重要呢?考虑我们人,例如我们需要在人群中识别某个人脸(众里寻他千百度),那我们为什么只关注它的脸呢?如果这个人穿的衣服啊帽子和其他人不一样,那么这时候的识别和跟踪就会更加容易和鲁棒。或者场景中这个人和其他的东西有一定的关系,例如他靠在一棵树上,那么他和树就存在了一定的关系,而树在场景中是不会动的(除非你摇动摄像头了),那我们借助树来辅助找到这个人是不是比单单去找这个人要容易,特别是人被部分遮挡住的时候。还有一些就是如果这个人带着女朋友(有其他物体陪着一起运动),那么可以将他们看成一个集合结构,作为一组进行跟踪,这样会比跟踪他们其中一个要容易。
总之,一个目标很少与整个场景隔离或者没有任何联系,因为总存在一些和目标运动存在短时或者长时相关的目标。这种空间上下文的相关性就是我们可以利用的。
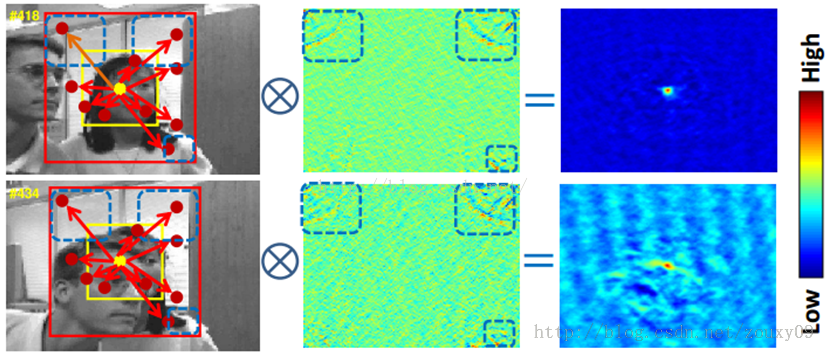
在视觉跟踪,局部上下文包括一个目标和它的附近的一定区域的背景。因为,在连续帧间目标周围的局部场景其实存在着很强的时空关系。例如,上图中的目标存在着严重的阻挡,导致目标的外观发生了很大的变化。然而,因为只有小部分的上下文区域是被阻挡的,整体的上下问区域是保持相似的,所以该目标的局部上下文不会发生很大的变化。因此,当前帧局部上下文会有助于帮助预测下一帧中目标的位置。图中,黄色框的是目标,然后它和它的周围区域,也就是红色框包围的区域,就是该目标的上下文区域。左:虽然出现严重的阻挡导致目标的外观发现很大的变化,但目标中心(由黄色的点表示)和其上下文区域中的周围区域的其他位置(由红色点表示)的空间关系几乎没有发生什么变化。中:学习到的时空上下文模型(蓝色方框内的区域具有相似的值,表示该区域与目标中心具有相似的空间关系)。右:学习到的置信图。
时间信息:邻近帧间目标变化不会很大。位置也不会发生突变。
空间信息:目标和目标周围的背景存在某种特定的关系,当目标的外观发生很大变化时,这种关系可以帮助区分目标和背景。
对目标这两个信息的组合就是时空上下文信息,该论文就是利用这两个信息来进行对阻挡等鲁棒并且快速的跟踪。
3.2、具体细节
跟踪问题可以描述为计算一个估计目标位置x似然的置信图:
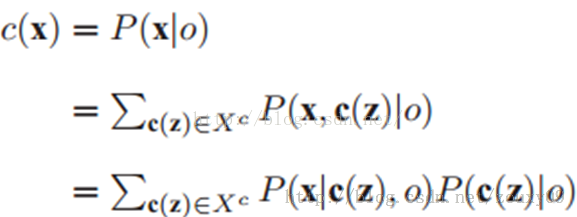
(1)Spatial Context Model 空间上下文模型
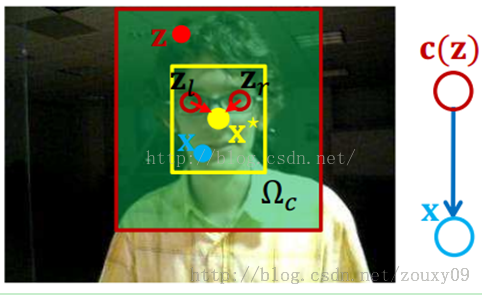
空间上下文模型描述的是条件概率函数:

hsc(x-z)是一个关于目标x和局部上下文位置z的相对距离和方向的函数,它编码了目标和它的空间上下文的空间关系。需要注意的是,这个函数并不是径向对称的。这有助于分辨二义性。例如图三,左眼和右眼相对于位置x*来说他们的距离是一样的,但相对位置也就是方向是不一样的。所以他们会有不一样的空间关系。这样就对防止误跟踪有帮助。
(2)Context Prior Model 上下文先验模型
这是先验概率,建模为:
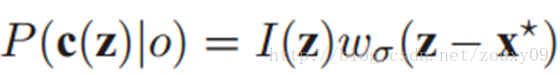
其中I(z)是点z的灰度,描述的是这个上下文z的外观。w是一个加权函数,z离x越近,权值越大。定义如下:
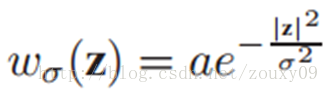
这个加权函数是由生物视觉系统的focus of attention 启发得到的,它表示人看东西的时候,会聚焦在一个确定的图像区域。通俗的来说,就是离我们的目标越近的点,会越受关注,越远就不好意思了,你的光芒会被无情的忽略掉。那多远的距离会被多大程度的忽略呢?这就得看参数sigma(相当于高斯权重函数的方差)了,这个值越大,越多的风景映入眼帘,祖国大好河山,尽收眼底。如果这个值越小,那就相当于坐井观天了。
(3)Confidence Map 置信图
定义为:
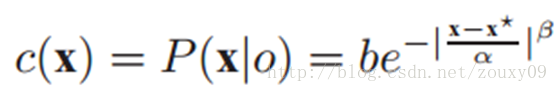
这个公式的参数β是很重要的,太大太小效果可能差之千里。具体分析见原论文。这个置信图是在给定目标的位置x*的基础上,我们通过这个公式来计算得到上下文区域任何一点x的似然得到的。
(4)时空模型的快速学习
我们需要基于上下文先验模型和置信图来学习这个时空模型:
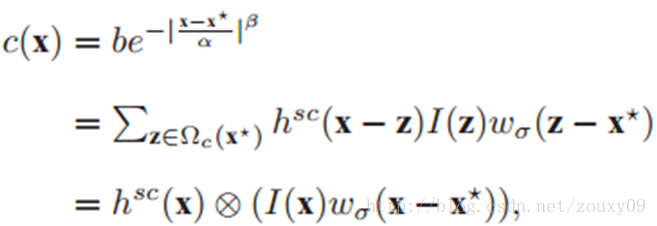
里面的卷积可以通过FFT来加速(时域的卷积相当于频域的乘积),具体如下:
这样,我们就可以通过两个FFT和一个IFFT来学习我们要的空间上下文模型了:
然后我们用这个模型去更新时空上下文模型:
(4)最后的跟踪
得到时空上下文模型后,我们就可以在新的一帧计算目标的置信图了:
同样是通过FFT来加速。然后置信图中值最大的位置,就是我们的目标位置了。
(5)多尺度的实现
多尺度可以通过调整方差sigma来实现。具体分析见原论文。(感觉这个是很remarkable的一点)。尺度和方差sigma的更新如下:
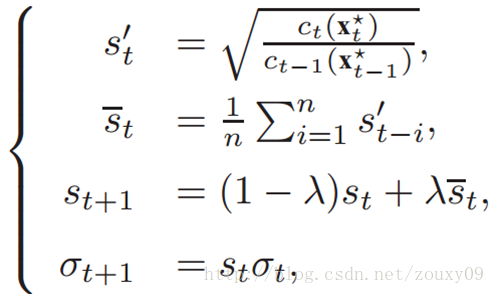
四、算法描述
简单的算法描述如下,编程实现其实也是这个过程。(另外,不知道我的尺度更新的位置对不对,望指点)
(1)t帧:
根据该帧图像I和得到的目标位置x*。顺序进行以下计算:
1)学习空间上下文模型:
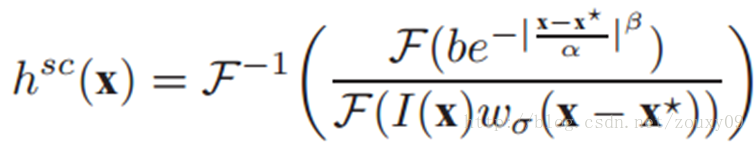
2)更新跟踪下一帧目标需要的时空上下文模型:
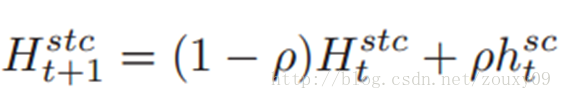
3)更新尺度等参数:
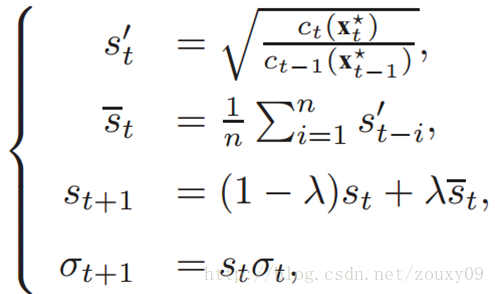
(2)t+1帧:
1)计算置信图:
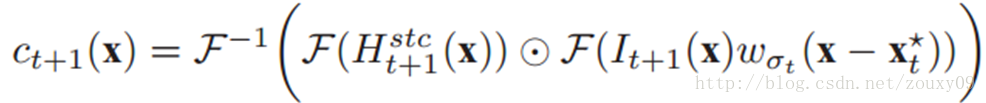
2)找到最大值,这个最大值的位置就是我们要求的目标位置:
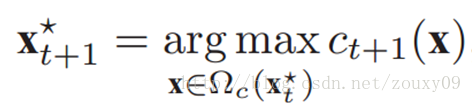
五、代码实现
我的代码是基于VS2010+OpenCV2.4.2的(暂时还没加入边界处理,也就是跟踪框到达图像边缘的时候程序就会出错)。代码可以读入视频,也可以读摄像头,两者的选择只需要在代码中稍微修改即可。对于视频来说,运行会先显示第一帧,然后我们用鼠标框选要跟踪的目标,然后跟踪器开始跟踪每一帧。对摄像头来说,就会一直采集图像,然后我们用鼠标框选要跟踪的目标,接着跟踪器开始跟踪后面的每一帧。
另外,为了消去光照的影响,需要先对图像去均值化,还需要加Hamming窗以减少图像边缘对FFT带来的频率影响。Hamming窗如下:
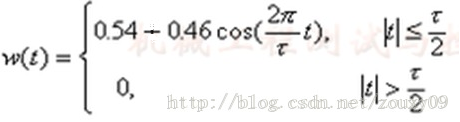
另外,OpenCV没有复数(FFT后是复数)的乘除运算,所以需要自己编写,参考如下:
复数除法:
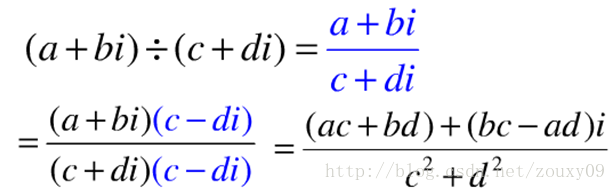
复数乘法:
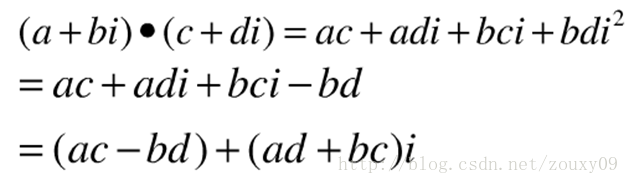
具体代码如下,STCTracker.h代码:
// Fast object tracking algorithm
// Author : zouxy
// Date : 2013-11-21
// HomePage : http://blog.csdn.net/zouxy09
// Email : zouxy09@qq.com
// Reference: Kaihua Zhang, et al. Fast Tracking via Spatio-Temporal Context Learning
// HomePage : http://www4.comp.polyu.edu.hk/~cskhzhang/
// Email: zhkhua@gmail.com
#pragma once
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
class STCTracker
{
public:
STCTracker();
~STCTracker();
void init(const Mat frame, const Rect box);
void tracking(const Mat frame, Rect &trackBox);
private:
void createHammingWin();
void complexOperation(const Mat src1, const Mat src2, Mat &dst, int flag = 0);
void getCxtPriorPosteriorModel(const Mat image);
void learnSTCModel(const Mat image);
private:
double sigma; // scale parameter (variance)
double alpha; // scale parameter
double beta; // shape parameter
double rho; // learning parameter
Point center; // the object position
Rect cxtRegion; // context region
Mat cxtPriorPro; // prior probability
Mat cxtPosteriorPro; // posterior probability
Mat STModel; // conditional probability
Mat STCModel; // spatio-temporal context model
Mat hammingWin; // Hamming window
};
// Fast object tracking algorithm
// Author : zouxy
// Date : 2013-11-21
// HomePage : http://blog.csdn.net/zouxy09
// Email : zouxy09@qq.com
// Reference: Kaihua Zhang, et al. Fast Tracking via Spatio-Temporal Context Learning
// HomePage : http://www4.comp.polyu.edu.hk/~cskhzhang/
// Email: zhkhua@gmail.com
#include "STCTracker.h"
STCTracker::STCTracker()
{
}
STCTracker::~STCTracker()
{
}
/************ Create a Hamming window ********************/
void STCTracker::createHammingWin()
{
for (int i = 0; i < hammingWin.rows; i++)
{
for (int j = 0; j < hammingWin.cols; j++)
{
hammingWin.at<double>(i, j) = (0.54 - 0.46 * cos( 2 * CV_PI * i / hammingWin.rows ))
* (0.54 - 0.46 * cos( 2 * CV_PI * j / hammingWin.cols ));
}
}
}
/************ Define two complex-value operation *****************/
void STCTracker::complexOperation(const Mat src1, const Mat src2, Mat &dst, int flag)
{
CV_Assert(src1.size == src2.size);
CV_Assert(src1.channels() == 2);
Mat A_Real, A_Imag, B_Real, B_Imag, R_Real, R_Imag;
vector<Mat> planes;
split(src1, planes);
planes[0].copyTo(A_Real);
planes[1].copyTo(A_Imag);
split(src2, planes);
planes[0].copyTo(B_Real);
planes[1].copyTo(B_Imag);
dst.create(src1.rows, src1.cols, CV_64FC2);
split(dst, planes);
R_Real = planes[0];
R_Imag = planes[1];
for (int i = 0; i < A_Real.rows; i++)
{
for (int j = 0; j < A_Real.cols; j++)
{
double a = A_Real.at<double>(i, j);
double b = A_Imag.at<double>(i, j);
double c = B_Real.at<double>(i, j);
double d = B_Imag.at<double>(i, j);
if (flag)
{
// division: (a+bj) / (c+dj)
R_Real.at<double>(i, j) = (a * c + b * d) / (c * c + d * d + 0.000001);
R_Imag.at<double>(i, j) = (b * c - a * d) / (c * c + d * d + 0.000001);
}
else
{
// multiplication: (a+bj) * (c+dj)
R_Real.at<double>(i, j) = a * c - b * d;
R_Imag.at<double>(i, j) = b * c + a * d;
}
}
}
merge(planes, dst);
}
/************ Get context prior and posterior probability ***********/
void STCTracker::getCxtPriorPosteriorModel(const Mat image)
{
CV_Assert(image.size == cxtPriorPro.size);
double sum_prior(0), sum_post(0);
for (int i = 0; i < cxtRegion.height; i++)
{
for (int j = 0; j < cxtRegion.width; j++)
{
double x = j + cxtRegion.x;
double y = i + cxtRegion.y;
double dist = sqrt((center.x - x) * (center.x - x) + (center.y - y) * (center.y - y));
// equation (5) in the paper
cxtPriorPro.at<double>(i, j) = exp(- dist * dist / (2 * sigma * sigma));
sum_prior += cxtPriorPro.at<double>(i, j);
// equation (6) in the paper
cxtPosteriorPro.at<double>(i, j) = exp(- pow(dist / sqrt(alpha), beta));
sum_post += cxtPosteriorPro.at<double>(i, j);
}
}
cxtPriorPro.convertTo(cxtPriorPro, -1, 1.0/sum_prior);
cxtPriorPro = cxtPriorPro.mul(image);
cxtPosteriorPro.convertTo(cxtPosteriorPro, -1, 1.0/sum_post);
}
/************ Learn Spatio-Temporal Context Model ***********/
void STCTracker::learnSTCModel(const Mat image)
{
// step 1: Get context prior and posterior probability
getCxtPriorPosteriorModel(image);
// step 2-1: Execute 2D DFT for prior probability
Mat priorFourier;
Mat planes1[] = {cxtPriorPro, Mat::zeros(cxtPriorPro.size(), CV_64F)};
merge(planes1, 2, priorFourier);
dft(priorFourier, priorFourier);
// step 2-2: Execute 2D DFT for posterior probability
Mat postFourier;
Mat planes2[] = {cxtPosteriorPro, Mat::zeros(cxtPosteriorPro.size(), CV_64F)};
merge(planes2, 2, postFourier);
dft(postFourier, postFourier);
// step 3: Calculate the division
Mat conditionalFourier;
complexOperation(postFourier, priorFourier, conditionalFourier, 1);
// step 4: Execute 2D inverse DFT for conditional probability and we obtain STModel
dft(conditionalFourier, STModel, DFT_INVERSE | DFT_REAL_OUTPUT | DFT_SCALE);
// step 5: Use the learned spatial context model to update spatio-temporal context model
addWeighted(STCModel, 1.0 - rho, STModel, rho, 0.0, STCModel);
}
/************ Initialize the hyper parameters and models ***********/
void STCTracker::init(const Mat frame, const Rect box)
{
// initial some parameters
alpha = 2.25;
beta = 1;
rho = 0.075;
sigma = 0.5 * (box.width + box.height);
// the object position
center.x = box.x + 0.5 * box.width;
center.y = box.y + 0.5 * box.height;
// the context region
cxtRegion.width = 2 * box.width;
cxtRegion.height = 2 * box.height;
cxtRegion.x = center.x - cxtRegion.width * 0.5;
cxtRegion.y = center.y - cxtRegion.height * 0.5;
cxtRegion &= Rect(0, 0, frame.cols, frame.rows);
// the prior, posterior and conditional probability and spatio-temporal context model
cxtPriorPro = Mat::zeros(cxtRegion.height, cxtRegion.width, CV_64FC1);
cxtPosteriorPro = Mat::zeros(cxtRegion.height, cxtRegion.width, CV_64FC1);
STModel = Mat::zeros(cxtRegion.height, cxtRegion.width, CV_64FC1);
STCModel = Mat::zeros(cxtRegion.height, cxtRegion.width, CV_64FC1);
// create a Hamming window
hammingWin = Mat::zeros(cxtRegion.height, cxtRegion.width, CV_64FC1);
createHammingWin();
Mat gray;
cvtColor(frame, gray, CV_RGB2GRAY);
// normalized by subtracting the average intensity of that region
Scalar average = mean(gray(cxtRegion));
Mat context;
gray(cxtRegion).convertTo(context, CV_64FC1, 1.0, - average[0]);
// multiplies a Hamming window to reduce the frequency effect of image boundary
context = context.mul(hammingWin);
// learn Spatio-Temporal context model from first frame
learnSTCModel(context);
}
/******** STCTracker: calculate the confidence map and find the max position *******/
void STCTracker::tracking(const Mat frame, Rect &trackBox)
{
Mat gray;
cvtColor(frame, gray, CV_RGB2GRAY);
// normalized by subtracting the average intensity of that region
Scalar average = mean(gray(cxtRegion));
Mat context;
gray(cxtRegion).convertTo(context, CV_64FC1, 1.0, - average[0]);
// multiplies a Hamming window to reduce the frequency effect of image boundary
context = context.mul(hammingWin);
// step 1: Get context prior probability
getCxtPriorPosteriorModel(context);
// step 2-1: Execute 2D DFT for prior probability
Mat priorFourier;
Mat planes1[] = {cxtPriorPro, Mat::zeros(cxtPriorPro.size(), CV_64F)};
merge(planes1, 2, priorFourier);
dft(priorFourier, priorFourier);
// step 2-2: Execute 2D DFT for conditional probability
Mat STCModelFourier;
Mat planes2[] = {STCModel, Mat::zeros(STCModel.size(), CV_64F)};
merge(planes2, 2, STCModelFourier);
dft(STCModelFourier, STCModelFourier);
// step 3: Calculate the multiplication
Mat postFourier;
complexOperation(STCModelFourier, priorFourier, postFourier, 0);
// step 4: Execute 2D inverse DFT for posterior probability namely confidence map
Mat confidenceMap;
dft(postFourier, confidenceMap, DFT_INVERSE | DFT_REAL_OUTPUT| DFT_SCALE);
// step 5: Find the max position
Point point;
minMaxLoc(confidenceMap, 0, 0, 0, &point);
// step 6-1: update center, trackBox and context region
center.x = cxtRegion.x + point.x;
center.y = cxtRegion.y + point.y;
trackBox.x = center.x - 0.5 * trackBox.width;
trackBox.y = center.y - 0.5 * trackBox.height;
trackBox &= Rect(0, 0, frame.cols, frame.rows);
cxtRegion.x = center.x - cxtRegion.width * 0.5;
cxtRegion.y = center.y - cxtRegion.height * 0.5;
cxtRegion &= Rect(0, 0, frame.cols, frame.rows);
// step 7: learn Spatio-Temporal context model from this frame for tracking next frame
average = mean(gray(cxtRegion));
gray(cxtRegion).convertTo(context, CV_64FC1, 1.0, - average[0]);
context = context.mul(hammingWin);
learnSTCModel(context);
}














 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









