






一、K近邻算法简介:
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居)。这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
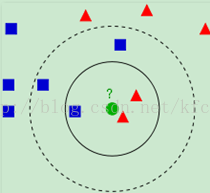
如上图所示,当k=3时,此时红色的个数为2,则绿色的输入实例的类别为红色的三角形,当k=5时,此时蓝色的个数为3,输入实例的类别为蓝色的四边形。
在分类过程中,k值通常是人为预先定义的常值,从上图可以看出,k值的选取对会对结果有很多的影响。
三要素:K 值的选择,距离度量和分类决策规则
KNN算法的过程为:
- 选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中的数据点的距离
- 按照距离递增次序进行排序,选取与当前距离最小的k个点
- 对于离散分类,返回k个点出现频率最多的类别作预测分类;对于回归则返回k个点的加权值作为预测值
下面我向大家介绍只分成了两类数据时的算法代码介绍:
from numpy import *
import operator
import matplotlib.pyplot as plt
plt.figure(1)
plt.figure(2) #同时显示两个图,一个原始数据,一个总数据,方便对比
group = array([[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],
[0.9,1.2],[1.1,1.3],[1.4,1.0],[1.7,1.9],
[1.3,0.8],[1.5,0.6],[0.1, 0.2],[0.3,0.6],
[0, 0.1],[0.2,0.3],[0.5,0.5],[0.4,0.7],
[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]])
labels = ['A', 'A', 'A','A','A',
'A', 'A', 'A','A','A',
'B','B','B','B', 'B',
'B','B','B','B', 'B'] # 20组数,2个类别
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #获取数据集的行数
#计算距离
#tile(a,(b,c)):将a的内容在行上重复b次,列上重复c次
#下面这一行代码的结果是将待分类数据集扩展到与已有数据集同样的规模,然后再与已有数据集作差
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2 #对上述差值求平方
sqDistances = sqDiffMat.sum(axis=1) #对于每一行数据求和
distances = sqDistances**0.5 #对上述结果开方
sortedDistIndicies = distances.argsort() #对开方结果建立索引
#计算距离最小的k个点的Lable
classCount={} #建立空字典,类别字典,保存各类别的数目
for i in range(k): #通过循环寻找k个近邻
voteIlabel = labels[sortedDistIndicies[i]] #先找出开方结果索引表中第i个值对应的Label值
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # 存入当前label以及对应的类别值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) #对类别字典进行逆排序,级别数目多的往前放
#返回结果
return sortedClassCount[0][0] #返回级别字典中的第一个值,也就是最有可能的Label值
print '''已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
'''
p=[1.0,1.0,0.8,0.7,0.9,1.1,1.4,1.7,1.3,1.5]
q=[1.1,1.0,0.7,1.4,1.2,1.3,1.0,1.9,0.8,0.6]
r=[0.1,0.3,0,0.2,0.5,0.4,0.3,0.4,0.7,0.8]
s=[0.2,0.6,0.1,0.3,0.5,0.7,0.5,0.4,0.3,0.2]
x='y'
while x=='y': #循环运行次数,方便多个未知数据的处理
a=input('请输入您需要判断的数据的x坐标:')
b=input('请输入您需要判断的数据的y坐标:')
c=input('请输入您需要用来进行运算的k值:')
d = classify([a,b], group, labels, c)
print '\n您输入的数据为[%s,%s],属于%s类\n' % (a,b,d)
label=['A','B']
plt.figure(1)
plt.plot(p,q,'or') #o指实点,r指颜色red,下一行g指颜色green
plt.plot(r,s,'og')
plt.title('knn raw data') #给图示加上标题
plt.legend(label, loc = 0, ncol = 1) #给图示加上图例
label=['A','B','C']
plt.figure(2)
plt.plot(p,q,'or')
plt.plot(r,s,'og')
plt.plot(a,b,'b*')
plt.title('knn data')
plt.legend(label, loc = 0, ncol = 1)
plt.show() #将上述的点都显示在图中
x=raw_input('继续判断请输入y,结束请按其他键,并按回车键确认:')
print '\n',
已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
请输入您需要判断的数据的x坐标:已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
请输入您需要判断的数据的x坐标:0.7
请输入您需要判断的数据的y坐标:0.55
请输入您需要用来进行运算的k值:5
您输入的数据为[0.7,0.55],属于B类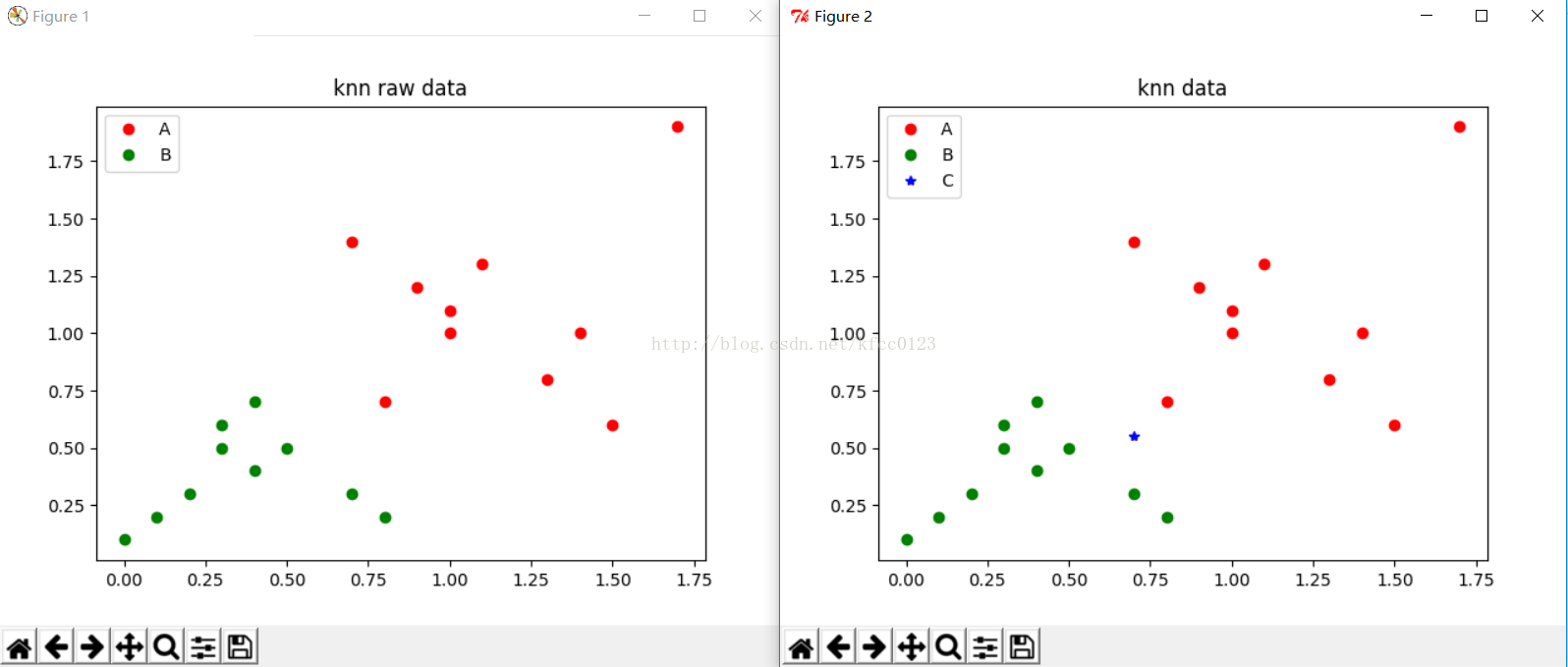
当你还想再对其他未知的数据进行判断,只需要点击这两张图右上角的x,就会出现:
已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
请输入您需要判断的数据的x坐标:0.7
请输入您需要判断的数据的y坐标:0.55
请输入您需要用来进行运算的k值:5
您输入的数据为[0.7,0.55],属于B类
继续判断请输入y,结束请按其他键,并按回车键确认:
已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
请输入您需要判断的数据的x坐标:0.7
请输入您需要判断的数据的y坐标:0.55
请输入您需要用来进行运算的k值:5
您输入的数据为[0.7,0.55],属于B类
继续判断请输入y,结束请按其他键,并按回车键确认:y
请输入您需要判断的数据的x坐标:0.8
请输入您需要判断的数据的y坐标:0.9
请输入您需要用来进行运算的k值:3
您输入的数据为[0.8,0.9],属于A类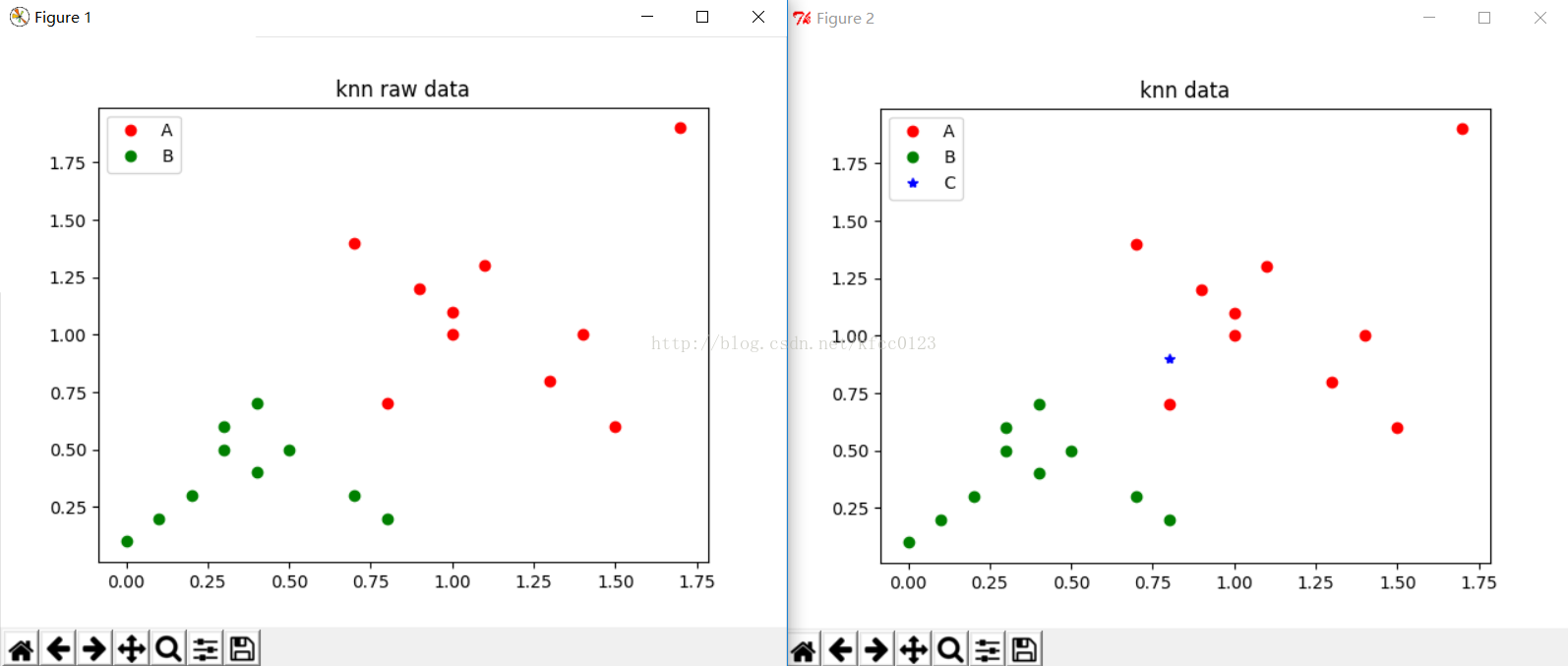
若不想继续,可以按其他键(除y以外的所有键)结束:
已有数据为:
A类:[1.0, 1.1], [1.0, 1.0],[0.8,0.7],[0.7,1.4],[0.9,1.2],
[1.1,1.3],[1.4,1.0],[1.7,1.9],[1.3,0.8],[1.5,0.6]
B类:[0.1, 0.2],[0.3,0.6],[0, 0.1],[0.2,0.3],[0.5,0.5],
[0.4,0.7],[0.3,0.5],[0.4,0.4],[0.7,0.3],[0.8,0.2]
请输入您需要判断的数据的x坐标:0.7
请输入您需要判断的数据的y坐标:0.55
请输入您需要用来进行运算的k值:5
您输入的数据为[0.7,0.55],属于B类
继续判断请输入y,结束请按其他键,并按回车键确认:0
>>> 













 1755
1755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









