







当buddy系统还有大量的连续物理内存时,我们可以通过__pages_alloc成功分配很大的一块连续物理内存空间,随着系统运行时间加长,buddy系统内很难中找到一块大的连续物理内存空间,因此__pages_alloc可能会失败,即便通过kswapd进行页面的回收和交换,buddy仍然不可避免的碎片化
首先我们要明确的是,连续物理内存的分配并不是必要的。对于大部分DMA操作,我们的确需要连续的物理内存;但是对于某些分配内存情况:比如,模块加载,设备和声音驱动程序中,可以在内核源码中关键字vmalloc查找,对vmalloc的使用有个感性认识。
vmalloc把buddy系统内的不连续物理内存,映射到内核中一段连续的地址空间内,因此对于那些无法直接映射的高端物理内存Highmem来说,vmalloc是主要用途之一(另外一个用途是应用程序的地址映射,之前我一直搞不清它和vmalloc的关系。实际二者没关系,只是看起来很像)。因此vmalloc理应优先使用廉价的Highmem内存,而把宝贵的低端内存,留给其他的内核操作。事实上也是如此,vmalloc实现函数的分配标志,指明了从Highmem分配
void *vmalloc(unsigned long size)
{
return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
}
对于vmalloc来说是需要预留一定的地址空间的,我个人觉得地址空间也算是一种资源,尤其对于IA32体系结构和大部分32bit体系结构,整个内核地址空间只有1G bytes(3:1 split)。而DMA和Normal内存zone 又需要占用数百M的地址空间,参见下面这个经典的kernel地址空间划分图
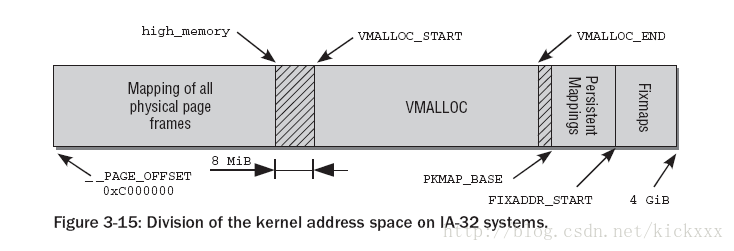
Persistent mappings和Fixmaps地址空间都比较小,这里我们忽略它们,这样只剩下直接地址映射和VMALLOC区,这个划分应该是平衡两个需求的结果
1. 尽量增加DMA和Normal区大小,也就是直接映射地址空间大小,当前主流平台的内存,基本上都超过了512MB,很多都是标配1GB内存,因此注定有一部分内存无法进行线性映射。
2. 保留一定数量的VMALLOC大小,这个值是应用平台特定的,如果应用平台某个驱动需要用vmalloc分配很大的地址空间,那么最好通过在kernel参数中指定vmalloc大小的方法,预留较多的vmalloc地址空间。
3. 并不是Highmem没有或者越少越好,这个是我的个人理解,理由如下:高端内存就像个垃圾桶和缓冲区,防止来自用户空间或者vmalloc的映射破坏Normal zone和DMA zone的连续性,使得它们碎片化。当这个垃圾桶较大时,那么污染Normal 和DMA的机会自然就小了。
下面的图是VMALLOC地址空间内部划分情况
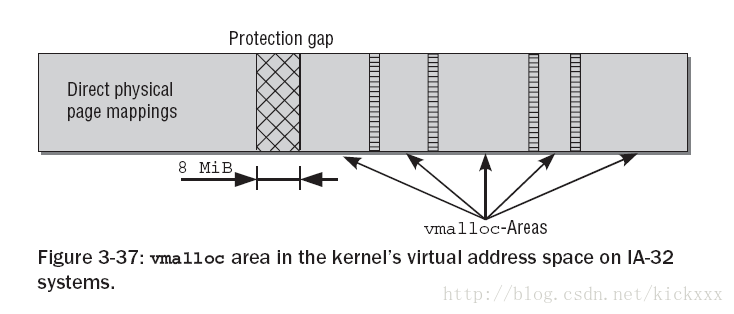
在直接地址映射和VMALLOC区之间有一个8MiB的隔离带,隔离带是做什么的呢? 隔离带是用来针对内核故障的保护措施,当访问虚拟地址越界时,则会产生一个page fault异常,也就是说这个内核地址空间没有对应相应的物理地址,这在内核地址空间是不允许的。如果不存在隔离带,那么越界访问不知不觉的跨越直接映射和VMALLOC区,内核却没注意到这个错误。
在VMALLOC内部,会划分为多个vmalloc_area,每个vmalloc_area直间有一个4KB的地址空隙,通过这个小的隔离,可以防止不同映射区直接的越界访问。
数据结构
在进入vmalloc代码实现之前,我们先了解相关的数据结构。
struct vm_struct {
/* keep next,addr,size together to speedup lookups */
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
unsigned long phys_addr;
};
内核在管理虚拟内存地址空间时,必须通过数据结构来跟踪哪些子区域被使用,哪些是空闲的。所有的这些数据连接到一个链表中
@next:所有的vm_struct通过next 组成一个单链表,表头为全局变量vmlist
@addr:定义了这个虚拟地址空间子区域的起始地址
@size:定义了这个虚拟地址空间子区域的大小
@flags:存储了与该内存区关联的标志
@pages是一个指针,指向page指针的数组,每个数组成员都表示一个映射到这个地址空间的物理页面的实例。
@nr_pages:page指针数据的长度
@phys_addr:仅当用ioremap映射了由物理地址描述的物理内存区域才有效。
注意 vm_struct和vm_area_struct是完全不同的,虽然二者都是做虚拟地址空间映射的:
1. 前者是内核虚拟地址空间映射,而后者则是应用进程虚拟地址空间映射。
2. 前者不会产生page fault,而后者一般不会提前分配页面,只有当访问的时候,产生page fault来分配页面。
vmalloc 映射示例
下图给除了vmalloc映射的一个实例,这个vmalloc区映射了三个物理内存页面
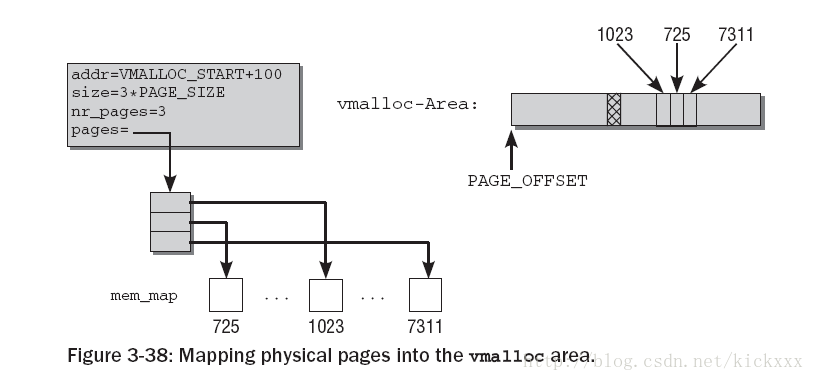
从VMALLOC_START+100开始,大小为3*PAGE_SIZE的内核地址空间,被映射到物理页面725, 1023和7311
vmalloc 代码实现
因为大部分体系结构都支持mmu,这里我们只考虑有mmu的情况。实际上没有mmu支持时,vmalloc就无法实现非连续物理地址到连续内核地址空间的映射,vmalloc退化为kmalloc实现
506 void *__vmalloc(unsigned long size, gfp_t gfp_mask, pgprot_t prot)
507 {
508 return __vmalloc_node(size, gfp_mask, prot, -1);
509 }
510 EXPORT_SYMBOL(__vmalloc);
512 /**
513 * vmalloc - allocate virtually contiguous memory
514 * @size: allocation size
515 * Allocate enough pages to cover @size from the page level
516 * allocator and map them into contiguous kernel virtual space.
517 *
518 * For tight control over page level allocator and protection flags
519 * use __vmalloc() instead.
520 */
521 void *vmalloc(unsigned long size)
522 {
523 return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
524 }
525 EXPORT_SYMBOL(vmalloc);
非常清楚,vmalloc优先使用HIGHMEM内存。返回值为内核虚拟地址空间地址,这个地址以及@size决定的分配空间,一定在VMALLOC范围之内。
__vmalloc也仅仅是__vmalloc_node包装函数
479 /**
480 * __vmalloc_node - allocate virtually contiguous memory
481 * @size: allocation size
482 * @gfp_mask: flags for the page level allocator
483 * @prot: protection mask for the allocated pages
484 * @node: node to use for allocation or -1
485 *
486 * Allocate enough pages to cover @size from the page level
487 * allocator with @gfp_mask flags. Map them into contiguous
488 * kernel virtual space, using a pagetable protection of @prot.
489 */
490 static void *__vmalloc_node(unsigned long size, gfp_t gfp_mask, pgprot_t prot,
491 int node)
492 {
493 struct vm_struct *area;
494
495 size = PAGE_ALIGN(size);
496 if (!size || (size >> PAGE_SHIFT) > num_physpages)
497 return NULL;
498
499 area = get_vm_area_node(size, VM_ALLOC, node, gfp_mask);
500 if (!area)
501 return NULL;
502
503 return __vmalloc_area_node(area, gfp_mask, prot, node);
504 }
495 把请求的@size按照页面对齐,说明分配是按照4K对齐的
非常自然的,分配过程分为两个步骤:1 分配地址空间,2 进行映射
499 从VMALLOC地址空间申请一块合适的地址空间
503 有了地址空间后,就需要对地址空间进行页面映射,也就是说分配页面物理页面
分配地址空间
263 struct vm_struct *get_vm_area_node(unsigned long size, unsigned long flags,
264 int node, gfp_t gfp_mask)
265 {
266 return __get_vm_area_node(size, flags, VMALLOC_START, VMALLOC_END, node,
267 gfp_mask);
268 }
在VMALLOC_START和VMALLOC_END指定的范围内查找
169 static struct vm_struct *__get_vm_area_node(unsigned long size, unsigned long flags,
170 unsigned long start, unsigned long end,
171 int node, gfp_t gfp_mask)
172 {
173 struct vm_struct **p, *tmp, *area;
174 unsigned long align = 1;
175 unsigned long addr;
176
177 BUG_ON(in_interrupt());
178 if (flags & VM_IOREMAP) {
179 int bit = fls(size);
180
181 if (bit > IOREMAP_MAX_ORDER)
182 bit = IOREMAP_MAX_ORDER;
183 else if (bit < PAGE_SHIFT)
184 bit = PAGE_SHIFT;
185
186 align = 1ul << bit;
187 }
188 addr = ALIGN(start, align);
189 size = PAGE_ALIGN(size);
190 if (unlikely(!size))
191 return NULL;
192
193 area = kmalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);
194
195 if (unlikely(!area))
196 return NULL;
197
198 /*
199 * We always allocate a guard page.
200 */
201 size += PAGE_SIZE;
202
203 write_lock(&vmlist_lock);
204 for (p = &vmlist; (tmp = *p) != NULL ;p = &tmp->next) {
205 if ((unsigned long)tmp->addr < addr) {
206 if((unsigned long)tmp->addr + tmp->size >= addr)
207 addr = ALIGN(tmp->size +
208 (unsigned long)tmp->addr, align);
209 continue;
210 }
211 if ((size + addr) < addr)
212 goto out;
213 if (size + addr <= (unsigned long)tmp->addr)
214 goto found;
215 addr = ALIGN(tmp->size + (unsigned long)tmp->addr, align);
216 if (addr > end - size)
217 goto out;
218 }
219
220 found:
221 area->next = *p;
222 *p = area;
223
224 area->flags = flags;
225 area->addr = (void *)addr;
226 area->size = size;
227 area->pages = NULL;
228 area->nr_pages = 0;
229 area->phys_addr = 0;
230 write_unlock(&vmlist_lock);
231
232 return area;
233
234 out:
235 write_unlock(&vmlist_lock);
236 kfree(area);
237 if (printk_ratelimit())
238 printk(KERN_WARNING "allocation failed: out of vmalloc space - use vmalloc=<size> to increase size.\n");
239 return NULL;
240 }
@start是进行扫描的首地址,@end是扫描的终止地址。在start和end指定的地址空间内分配。
193 首先分配一个vm_struct 结构,因为这个机构很小,自然使用kmalloc进行分配了,至于在哪个node分配,不用care
198~201 每个vm_struct之间都有4KB的隔离区,所以这里多分配4KB
204 ~ 218 循环遍历已经创建的vm_struct区,找到能够创建地址空间的位置
205 ~ 209 如果start大于当前vm_struct的起始位置,那么我们尝试下一个。同时判断start是否落在这个vm_struct内,如果是还要修改start
213 ~ 214 如果size + addr小于当前的vm_struct,说明匹配了一个可用位置,直接跳到found标号
221 ~ 222 把这个vm_struct增加到vmlist中去
从这个函数我们可以看出来,vm_struct的分配并不会考虑最优匹配,而是在碰到一个够用空间后直接返回。
分配物理页面 并映射
__vmalloc_area_node
426 void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
427 pgprot_t prot, int node)
428 {
429 struct page **pages;
430 unsigned int nr_pages, array_size, i;
431
432 nr_pages = (area->size - PAGE_SIZE) >> PAGE_SHIFT;
433 array_size = (nr_pages * sizeof(struct page *));
434
435 area->nr_pages = nr_pages;
436 /* Please note that the recursion is strictly bounded. */
437 if (array_size > PAGE_SIZE) {
438 pages = __vmalloc_node(array_size, gfp_mask | __GFP_ZERO,
439 PAGE_KERNEL, node);
440 area->flags |= VM_VPAGES;
441 } else {
442 pages = kmalloc_node(array_size,
443 (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO,
444 node);
445 }
446 area->pages = pages;
447 if (!area->pages) {
448 remove_vm_area(area->addr);
449 kfree(area);
450 return NULL;
451 }
452
453 for (i = 0; i < area->nr_pages; i++) {
454 if (node < 0)
455 area->pages[i] = alloc_page(gfp_mask);
456 else
457 area->pages[i] = alloc_pages_node(node, gfp_mask, 0);
458 if (unlikely(!area->pages[i])) {
459 /* Successfully allocated i pages, free them in __vunmap() */
460 area->nr_pages = i;
461 goto fail;
462 }
463 }
464
465 if (map_vm_area(area, prot, &pages))
466 goto fail;
467 return area->addr;
468
469 fail:
470 vfree(area->addr);
471 return NULL;
472 }
432 根据area的size计算需要的物理页面数目,减去1个PAGE_SIZE是因为这个vmalloc区包含一个4KB的隔离区
433 ~ 445 为area->pages数组分配内存,理论上一个页面只能保证1000个page指针,所以area->pages也使用vmalloc分配就很正常了
453 ~ 463调用alloc_pages_node一个一个的分配page,所以vmalloc的分配速度自然没有使用alloc_pages的kmalloc高,但是vmalloc的成功率就很高了。
465 目前为止,还有一件事没完成,那就是物理地址对逻辑地址的映射,map_vm_area就是做这事的
线性地址到物理地址映射
148 int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
149 {
150 pgd_t *pgd;
151 unsigned long next;
152 unsigned long addr = (unsigned long) area->addr;
153 unsigned long end = addr + area->size - PAGE_SIZE;
154 int err;
155
156 BUG_ON(addr >= end);
157 pgd = pgd_offset_k(addr);
158 do {
159 next = pgd_addr_end(addr, end);
160 err = vmap_pud_range(pgd, addr, next, prot, pages);
161 if (err)
162 break;
163 } while (pgd++, addr = next, addr != end);
164 flush_cache_vmap((unsigned long) area->addr, end);
165 return err;
166 }
167 EXPORT_SYMBOL_GPL(map_vm_area);153 别忘了,减去隔离区的一个PAGE_SIZE大小
158 ~ 163 对addr和end范围内的页表进行映射,包括pgd pud pmd和pte。
164 这是一个体系结构相关的函数,有些体系结构无法察觉到页表的变化,因此在修改页表后,需要程序主动的去刷新以下;有些CPU有感知变化的能力,会自动的刷新高速缓存,IA32就是如此。
GOOD,分析完了,vmalloc的代码还是简明清晰的,这次阅读解决了几个以前迷惑的问题
1. vmalloc区域是不是和应用空间内存映射一样,通过page fault来装载页面的。
答案:不是,vmalloc映射建立好后,逻辑地址,物理页面全部分配好,而且页表也已经更新好,和用户空间映射完全一样。这是合理的,因为如果像用户空间映射那样,访问地址产生page fault,会使得vmalloc获得的内存使用上受到极大的限制,比如不能在禁止调度的地方访问vmalloc分配的地址。














 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









