







1.子查询
语法:select ... from 表1 where 字段1 > (子查询语句)
例句:查看年龄比“李斯文”大的学员,要求显示学员信息;
select * from stuinfo where stuage > (select stuage from stuinfo where stuname = '李斯文')
实战:查询北京市下面的所有地区
select name from area where cityid = (select code from city where name = '北京市')
--注意:将“子查询”和“比较运算”符联合使用,必须保证子查询返回的值不能多余一个
----------------------------------------------------------------------------------------------------------------------
2.BETWEEN在某个范围内进行查询
语法:select ... from 表1 where 字段 between 参数1 and 参数2
select * from area where id between 1 and 20
GO
select * from area where id not between 10 and 20
----------------------------------------------------------------------------------------------------------------------
3.IN和NOT IN 子查询
select * from area where cityid in('110100','130100')
GO
select * from area where cityid in (select code from city where code = '110100')
GO
select * from area where cityid not in(select code from city where code = '110100')
----------------------------------------------------------------------------------------------------------------------
4.GROUP BY分组查询
select provinceid,avg(id) from city group by provinceid
GO
select provinceid,code from city group by provinceid,code
--注意:在使用Group By关键字时,在select列表中可以指定的项目是有限制的,
--1)被分组的列
--2)每个分组返回一个值的表达式,例如一个列名作为参数的聚合函数(sum()、avg()、max()、min()、count())。
----------------------------------------------------------------------------------------------------------------------
5.HAVING子句分组筛选
select provinceid from city group by provinceid having count(*)>0
----------------------------------------------------------------------------------------------------------------------
注意:WHERE————》GROUP BY————》HAVING次序
select 部门编号,count(*) from 表
where 工资 >= 2000
group by 部门编号
having count(*)>1
----------------------------------------------------------------------------------------------------------------------
6.声明局部变量及赋值
声明变量:
DECLARE @namevalue varcher(8)
DECLARE @num int
变量赋值:
SET @namevalue ="100"
SET @num=100
或
SELECT @namevalue ="100"
SELECT @num=100
----------------------------------------------------------------------------------------------------------------------
7.IF-ELSE条件语句
if(条件)
BEGIN
语句...
END
else
BEGIN
语句...
END
----------------------------------------------------------------------------------------------------------------------
8.存储过程
语法:
CREATE PROC[EDURE] 存储过程名称
@参数1 数据类型,
@参数n 数据类型
AS
SQL语句...
例句:
CREATE PROCEDURE proc_city
@namevalue varcher(8),
@num int
AS
SELECT * FROM city WHERE cityname=@namevalue and ispass != @num----------------------------------------------------------------------------------------------------------------------
9.distinct去除重复
select name, distinct cityid from area----------------------------------------------------------------------------------------------------------------------
10.case分为简单case函数和搜索case函数
1.简单case函数
Case sex
when ‘1’ then ‘男'
when ‘2’ then ‘女'
else '其他' end
2.搜索case函数
Case when sex = '1' then '男'
when sex = ‘2’ then ‘女'
else '其他' end
select code,
sum(case when cityid = '110100' then 1 else 0 end)'北京',
sum(case when cityid = '120100' then 1 else 0 end)'石家庄'
from area group by code
----------------------------------------------------------------------------------------------------------------------
11.UNION和UNION ALL操作符用于合并两个或多个SELECT语句的结果集
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
例句1:
SELECT E_Name FROM Employees_China
UNION
SELECT E_Name FROM Employees_USA
例句2:
SELECT E_Name FROM Employees_China
UNION ALL
SELECT E_Name FROM Employees_USA----------------------------------------------------------------------------------------------------------------------
12.WITH AS:临时存储,一般在存储过程里使用
例句1:
with t as (select * from emp where depno=10)
select * from t where empno=xxx
例句2:
with a as (select * from test)
select * from a
例句3:
with cte as(
select distinct c1,c2 from table_1 t1 where t1.c1 = '1' or t1.c2 = '2'
)
select * from table_2 t2
join cte on t2.c3 = cte.c1 and t2.c4 = cte.c2
where 1=1
order by t2.c1 desc
offset 1 rows
fetch next 20 rows only----------------------------------------------------------------------------------------------------------------------
知道会员组,知道组员,统计每个会员组下有多少学员
tblGroups表
CREATE TABLE [dbo].[tblGroups](
[Id] [uniqueidentifier] NOT NULL,
[Name] [nvarchar](50) NOT NULL,
[Description] [nvarchar](max) NULL,
CONSTRAINT [PK_tblGroups] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
tblMembers表
CREATE TABLE [dbo].[tblMembers](
[Id] [uniqueidentifier] NOT NULL,
[FirstName] [nvarchar](50) NOT NULL,
[LastName] [nvarchar](50) NULL,
[Email] [nvarchar](50) NULL,
[GroupId] [uniqueidentifier] NOT NULL,
CONSTRAINT [PK_tblMembers] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SQL语句
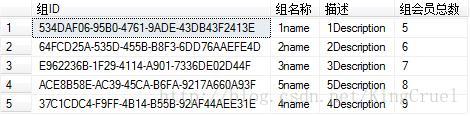
select g.Id AS 组ID,g.Name as 组名称,g.Description as 描述 ,hh.CID as 组会员总数 from
(select m.GroupId as gID,COUNT(m.GroupId) as CID from dbo.tblMembers as m
left join dbo.tblGroups g
on m.GroupId = g.Id
group by m.GroupId) hh, dbo.tblGroups g
where hh.gID = g.Id
sql语言
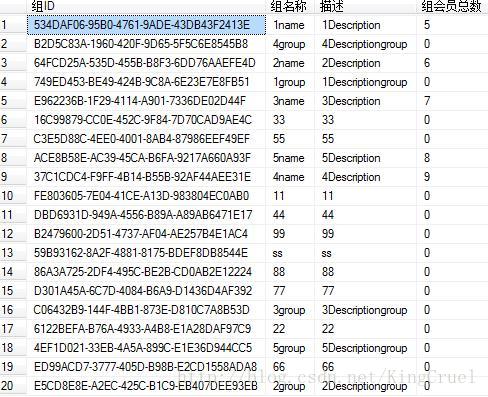
select g.Id AS 组ID,g.Name as 组名称,g.Description as 描述 ,hh.CID as 组会员总数 from
(select g.Id as gID,COUNT(m.GroupId) as CID from dbo.tblGroups as g
left join dbo.tblMembers m
on g.Id = m.GroupId
group by g.Id) hh, dbo.tblGroups g
where hh.gID = g.Id
或
select g.Id,g.Name,g.Description,(select COUNT(*) from tblMembers m where m.GroupId = g.Id)
from tblGroups g.














 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









