







1 问题引出
前几天在 CSDN 论坛遇到这样一个问题。
我要通过正则分别取出下面 <font color="#008000"> 与 </font> 之间的字符串
1 、在 <font color="#008000"> 与 </font> 之间的字符串是没法固定的,是随机自动生成的
2 、其中 <font color="#008000"> 与 </font> 的数量也是没法固定的,也是随机自动生成的
<font color="#008000"> ** 这里是不固定的字符串 1 ** </font>
<font color="#008000"> ** 这里是不固定的字符串 2 ** </font>
<font color="#008000"> ** 这里是不固定的字符串 3 ** </font>
有朋友给出这样的正则“ (?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>) ”,看下匹配结果。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> " ;
MatchCollection mc = Regex .Matches(test, @"(?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>)" );
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "/n---------------/n" ;
}
/*-------- 输出--------
** 这里是不固定的字符串1 **
---------------
<font color="#008000"> ** 这里是不固定的字符串2 **
---------------
<font color="#008000"> ** 这里是不固定的字符串3 **
---------------
*/
为什么会是这样的结果,而不是我们期望的如下的结果呢?
/*-------- 输出--------
** 这里是不固定的字符串1 **
---------------
** 这里是不固定的字符串2 **
---------------
** 这里是不固定的字符串3 **
---------------
*/
这涉及到逆序环视的匹配原理,以及贪婪与非贪婪模式应用的一些细节,下面先针对逆序环视的匹配细节展开讨论,然后再回过头来看下这个问题。
2 逆序环视匹配原理
关于环视的一些基础讲解和基本匹配原理,在 正则基础之 —— 环视 这篇博客里已有所介绍,只不过当时整理得比较匆忙,没有涉及更详细的匹配细节。这里仅针对逆序环视展开讨论。
逆序环视的基础知识在上面博文中已介绍过,这里简单引用一下。
| 表达式 | 说明 |
| (?<=Expression) | 逆序肯定环视,表示所在位置左侧能够匹配 Expression |
| (?<!Expression) | 逆序否定环视,表示所在位置左侧不能匹配 Expression |
对于逆序肯定环视 (?<=Expression) 来说,当子表达式 Expression 匹配成功时, (?<=Expression) 匹配成功,并报告 (?<=Expression) 匹配当前位置成功。
对于逆序否定环视 (?<!Expression) 来说,当子表达式 Expression 匹配成功时, (?<!Expression) 匹配失败;当子表达式 Expression 匹配失败时, (?<!Expression) 匹配成功,并报告 (?<!Expression) 匹配当前位置成功。
2.1 逆序环视匹配行为分析
2.1.1 逆序环视支持现状
目前支持逆序环视的语言还比较少,比如当前比较流行的脚本语言 JavaScript 中就是不支持逆序环视的。个人认为不支持逆序环视已成为目前 JavaScript 中使用正则的最大限制,一些使用逆序环视很轻松搞定的输入验证,却要通过各种变通的方式来实现。
需求:验证输入由字母、数字和下划线组成,下划线不能出现在开始或结束位置。
对于这样的需求,如果支持逆序环视,直接“ ^(?!_)[a-zA-Z0-9_]+(?<!_)$ ”就可以了搞定了,但是在 JavaScript 中,却需要用类似于“ ^[a-zA-Z0-9]([a-zA-Z0-9_]*[a-zA-Z0-9])?$ ”这种变通方式来实现。这只是一个简单的例子,实际的应用中,会比这复杂得多,而为了避免量词的嵌套带来的效率陷阱,正则实现起来很困难,甚至有些情况不得不拆分成多个正则来实现。
而另一些流行的语言,比如 Java 中,虽然支持逆序环视,但只支持固定长度的子表达式,量词也只支持“ ? ”,其它不定长度的量词如“ * ”、“ + ” 、“ {m,n} ”等是不支持的。
源字符串: <div>a test</div>
需求:取得 div 标签的内容,不包括 div 标签本身
Java 代码实现:
import java.util.regex.*;
String test = "<div>a test</div>" ;
String reg = "(?<=<div>)[^<]+(?=</div>)" ;
Matcher m = Pattern.compile (reg).matcher(test);
while (m.find())
{
System. out .println(m.group());
}
/*-------- 输出--------
a test
*/
但是如果源字符串变一下,加个属性变成“ <div id=”test1”>a test</div> ”,那么除非标签中属性内容是固定的,否则就无法在 Java 中用逆序环视来实现了。
为什么在很多流行语言中,要么不支持逆序环视,要么只支持固定长度的子表式呢?先来分析一下逆序环视的匹配原理吧。
2.1.2 Java 中逆序环视匹配原理分析
不支持逆序环视的自不必说,只支持固定长度子表达式的逆序环视如何呢。
源字符串: <div>a test</div>
正则表达式: (?<=<div>)[^<]+(?=</div>)

需要明确的一点,无论是什么样的正则表达式,都是要从字符串的位置 0 处开始尝试匹配的。
首先由“ (?<=<div>) ”取得控制权,由位置 0 开始尝匹配,由于“ <div> ”的长度固定为 5 ,所以会从当前位置向左查找 5 个字符,但是由于此时位于位置 0 处,前面没有任何字符,所以尝试匹配失败。
正则引擎传动装置向右传动,由位置 1 处开始尝试匹配,同样匹配失败,直到位置 5 处,向左查找 5 个字符,满足条件,此时把控制权交给“ (?<=<div>) ”中的子表达式“ <div> ”。“ <div> ”取得控制权后,由位置 0 处开始向右尝试匹配,由于正则都是逐字符进行匹配的,所以这时会把控制权交给“ <div> ”中的“ < ”,由“ < ”尝试字符串中的“ < ”,匹配成功,接下来由“ d ”尝试字符串中的“ d ”,匹配成功,同样的过程,由“ <div> ”匹配位置 0 到位置 5 之间的“ <div> ”成功,此时“ (?<=<div>) ”匹配成功,匹配成功的位置是位置 5 。
后续的匹配过程请参考 正则基础之 —— 环视 和 正则基础之 ——NFA 引擎匹配原理 。
那么对于量词“ ? ”又是怎么样一种情况呢,看一下下面的例子。
源字符串: cba
正则表达式: (?<=(c?b))a
String test = "cba" ;
String reg = "(?<=(c?b))a" ;
Matcher m = Pattern.compile (reg).matcher(test);
while (m.find())
{
System. out .println(m.group());
System. out .println(m.group(1));
}
/*-------- 输出--------
a
b
*/
可以看到,“ c? ”并没有参与匹配,在这里,“ ? ”并不具备贪婪模式的作用,“ ? ” 只提供了一个分支的作用,共记录了两个分支,一个分支需要从当前位置向前查找一个字符,另一个分支需要从当前位置向前查找两个字符。正则引擎从当前位置, 尝试这两种情况,优先尝试的是需要向前查找较少字符的分支,匹配成功,则不再尝试另一个分支,只有这一分支匹配失败时,才会去尝试另一个分支。
String test = "dcba" ;
String reg = "(?<=(dc?b))a" ;
Matcher m = Pattern.compile (reg).matcher(test);
while (m.find())
{
System. out .println(m.group());
System. out .println(m.group(1));
}
/*-------- 输出--------
a
dcb
*/
虽然有两个分支,但向前查找的字符数可预知的,所以只支持“ ? ”时并不复杂,但如果再支持其它不定长度量词,情况又如何呢?
2.1.3 .NET 中逆序环视匹配原理
.NET 的逆序环视中,是支持不定长度量词的,在这个时候,匹配过程就变得复杂了。先看一下定长的是如何匹配的。
string test = "<div>a test</div>" ;
Regex reg = new Regex (@"(?<=<div>)[^<]+(?=</div>)" );
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "/n" ;
}
/*-------- 输出--------
a test
*/
从结果可以看到, .NET 中的逆序环视在子表达式长度固定时,匹配行为与 Java 中应该是一样的。那么不定长量词又如何呢?
string test = "cba" ;
Regex reg = new Regex (@"(?<=(c?b))a" );
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "/n" ;
richTextBox2.Text += m.Groups[1].Value + "/n" ;
}
/*-------- 输出--------
a
cb
*/
可以看到,这里的“ ? ”具备了贪婪模式的特性。那么这个时候是否会有这样的疑问,它的匹配过程仍然是从当前位置向左尝试,还是从字符串开始位置向右尝试匹配呢?
string test = "<ddd<cccba" ;
Regex reg = new Regex (@"(?<=(<.*?b))a" );
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "/n" ;
richTextBox2.Text += m.Groups[1].Value + "/n" ;
}
/*-------- 输出--------
a
<cccb
*/
从结果可看出,在逆序环视中有不定量词的时候,仍然是从当前位置,向左尝试匹配的,否则 Groups[1] 的内容就是“ <ddd<cccb ”,而不是“ <cccb ”了。
这是非贪婪模式的匹配情况,再看一下贪婪模式匹配的情况。
string test = "e<ddd<cccba" ;
Regex reg = new Regex (@"(?<=(<.*b))a" );
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "/n" ;
richTextBox2.Text += m.Groups[1].Value + "/n" ;
}
/*-------- 输出--------
a
<ddd<cccb
*/
可以看到,采用贪婪模式以后,虽然尝试到“ c ”前面的“ < ”时已经可以匹配成功,但由于是贪婪模式,还是要继续尝试匹配的。直到尝试到开始位置,取最长的成功匹配作为匹配结果。
2.2 匹配过程
再来理一下逆序环视的匹配过程吧。
源字符串: <div id=“test1”>a test </div>
正则表达式: (?<=<div[^>]*>) [^<]+(?=</div>)
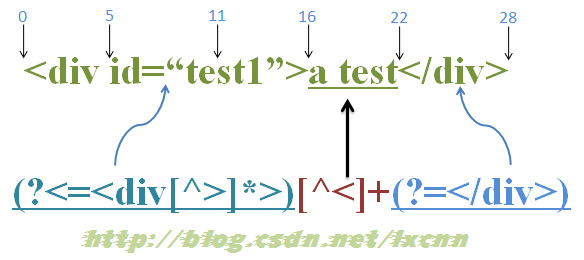
首先由“ (?<=<div[^>]*>) ”取得控制权,由位置 0 开始尝匹配,由于“ <div[^>]*> ”的长度不固定,所以会从当前位置向左逐字符查找,当然,也有可能正则引擎做了优化,先计算一下最小长度后向前查找,在这里“ <div[^>]*> ”至少需要 5 个字符,所以由当前位置向左查找 5 个字符,才开始尝试匹配,这要看各语言的正则引擎如何实现了,我推测是先计算最小长度。但是由于此时位于位置 0 处,前面没有任何字符,所以尝试匹配失败。
正则引擎传动装置向右传动,由位置 1 处开始尝试匹配,同样匹配失败,直到位置 5 处,向左查找 5 个字符,满足条件,此时把控制权交给“ (?<=<div[^>]*>) ”中的子表达式“ <div[^>]*> ”。“ <div[^>]*> ”取得控制权后,由位置 0 处开始向右尝试匹配,由于正则都是逐字符进行匹配的,所以这时会把控制权交给“ <div[^>]*> ”中的“ < ”,由“ < ”尝试字符串中的“ < ”,匹配成功,接下来由“ d ”尝试字符串中的“ d ”,匹配成功,同样的过程,由“ <div[^>]* ”匹配位置 0 到位置 5 之间的“ <div ”成功,其中“ [^>]* ”在匹配“ <div ”中的空格时是要记录可供回溯的状态的,此时控制权交给“ > ”,由于已没有任何字符可供匹配,所以“ > ”匹配失败,此时进行回溯,由“ [^>]* ”让出已匹配的空格给“ > ”进行匹配,同样匹配失败,此时已没有可供回溯的状态,所以这一轮匹配尝试失败。
正则引擎传动装置向右传动,由位置 6 处开始尝试匹配,同样匹配失败,直到位置 16 处,此时的当前位置指的就是位置 16 ,把控制权交给“ (?<=<div[^>]*>) ”,向左查找 5 个字符,满足条件,记录回溯状态,控制权交给“ (?<=<div[^>]*>) ”中的子表达式“ <div[^>]*> ”。“ <div[^>]*> ”取得控制权后,由位置 11 处开始向右尝试匹配, “ <div[^>]*> ”中的“ < ”尝试字符串中的“ s ”,匹配失败。继续向左尝试,在位置 10 处由“ < ”尝试字符串中的“ e ”,匹配失败。同样的过程,直到尝试到位置 0 处,由“ <div[^>]* ”在位置 0 向右尝试匹配,成功匹配到“ <div id=“test1”> ”,此时“ (?<=<div[^>]*>) ”匹配成功,控制权交给“ [^>]+ ”,继续进行下面的匹配,直到整个表达式匹配成功。
总结正则表达式“ (?<=SubExp1) SubExp2 ”的匹配过程:
1、 由位置 0 处向右尝试匹配,直到找到一个满足“ (?<=SubExp1) ”最小长度要求的位置 x ;
2、 从位置 x 处向左查找满足“ SubExp1 ”最小长度要求的位置 y ;
3、 由“ SubExp1 ”从位置 y 开始向右尝试匹配;
4、 如果“ SubExp1 ”为固定长度或非贪婪模式,则找到一个成功匹配项即停止尝试匹配;
5、 如果“ SubExp1 ”为贪婪模式,则要尝试所有的可能,取最长的成功匹配项作为匹配结果。
6、 “ (?<=SubExp1) ”成功匹配后,控制权交给后面的子表达式,继续尝试匹配。
需要说明的一点,逆序环视中的子表达式“ SubExp1 ”,匹配成功时,匹配开始的位置是不可预知的,但匹配结束的位置一定是位置 x 。
3 问题分析与总结
3.1 问题分析
那么再回过头来看下最初的问题。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> " ;
MatchCollection mc = Regex .Matches(test, @"(?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>)" );
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "/n---------------/n" ;
}
/*-------- 输出--------
** 这里是不固定的字符串1 **
---------------
<font color="#008000"> ** 这里是不固定的字符串2 **
---------------
<font color="#008000"> ** 这里是不固定的字符串3 **
---------------
*/
其实真正让人费解的是这里的逆序环视的匹配结果,为了更好的说明问题,改下正则。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> " ;
MatchCollection mc = Regex .Matches(test, @"(?<=(<font[/s/S]*?>))([/s/S]*?)(?=</font>)" );
for (int i=0;i<mc.Count;i++)
{
richTextBox2.Text += " 第" + (i+1) + " 轮成功匹配结果:/n" ;
richTextBox2.Text += "Group[0] :" + m.Value + "/n" ;
richTextBox2.Text += "Group[1] :" + m.Groups[1].Value + "/n---------------/n" ;
}
/*-------- 输出--------
第1轮成功匹配结果:
Group[0]: ** 这里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2轮成功匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串2 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
---------------
第3轮成功匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串3 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串2 ** </font>
---------------
*/
对于第一轮成功匹配结果应该不存在什么疑问,这里不做解释。
第一轮成功匹配结束的位置是第一个“ </font> ”前的位置,第二轮成功匹配尝试就是从这一位置开始。
首先由“ (?<=<font[/s/S]*?>) ”取得控制权,向左查找 6 个字符后开始尝试匹配,由于“ < ”会匹配失败,所以会一直尝试到位置 0 处,这时“ <font ”是可以匹配成功的,但是由于“ <font[/s/S]*?> ”要匹配成功,匹配的结束位置必须是第一个“ </font> ”前的位置,所以“ > ”是匹配失败的,这一位置整个表达式匹配失败。
正则引擎传动装置向右传动,直到第一个“ </font> ”后的位置,“ <font[/s/S]*?> ”匹配成功,匹配开始位置是位置 0 ,匹配结束位置是第一个“ </font> ”后的位置,“ <font[/s/S]*?> ”匹配到的内容是“ <font color="#008000"> ** 这里是不固定的字符串 1 ** </font> ”,其中“ [/s/S]*? ”匹配到的内容是“ color="#008000"> ** 这里是不固定的字符串 1 ** </font ”,后面的子表达式继续匹配,直到第二轮匹配成功。
接下来的第三轮成功匹配,匹配过程与第二轮基本相同,只不过由于使用的是非贪婪模式,所以“ <font[/s/S]*?> ”在匹配到“ <font color="#008000"> ** 这里是不固定的字符串 2 ** </font> ”时匹配成功,就结束匹配,不再向左尝试匹配了。
接下来看下贪婪模式的匹配结果。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> " ;
MatchCollection mc = Regex .Matches(test, @"(?<=(<font[/s/S]*>))([/s/S]*?)(?=</font>)" );
for (int i=0;i<mc.Count;i++)
{
richTextBox2.Text += " 第" + (i+1) + " 轮成功匹配结果:/n" ;
richTextBox2.Text += "Group[0] :" + m.Value + "/n" ;
richTextBox2.Text += "Group[1] :" + m.Groups[1].Value + "/n---------------/n" ;
}
/*-------- 输出--------
第1 轮匹配结果:
Group[0] : ** 这里是不固定的字符串1 **
Group[1] :<font color="#008000">
---------------
第2 轮匹配结果:
Group[0] :
<font color="#008000"> ** 这里是不固定的字符串2 **
Group[1] :<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
---------------
第3 轮匹配结果:
Group[0] :
<font color="#008000"> ** 这里是不固定的字符串3 **
Group[1] :<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
<font color="#008000"> ** 这里是不固定的字符串2 ** </font>
---------------
*/
仅仅是一个字符的差别,整个表达式的匹配结果没有变化,但匹配过程差别却是很大的。
那么如果想得到下面这种结果要如何做呢?
/*-------- 输出--------
** 这里是不固定的字符串1 **
---------------
** 这里是不固定的字符串2 **
---------------
** 这里是不固定的字符串3 **
---------------
*/
把量词修饰的子表达式的匹配范围缩小就可以了。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> " ;
MatchCollection mc = Regex .Matches(test, @"(?is)(?<=(<font[^>]*>))(?:(?!</?font/b).)*(?=</font>)" );
for (int i=0;i<mc.Count;i++)
{
richTextBox2.Text += " 第" + (i+1) + " 轮匹配结果:/n" ;
richTextBox2.Text += "Group[0] :" + mc[i].Value + "/n" ;
richTextBox2.Text += "Group[1] :" + mc[i].Groups[1].Value + "/n---------------/n" ;
}
/*-------- 输出--------
第1 轮匹配结果:
Group[0] : ** 这里是不固定的字符串1 **
Group[1] :<font color="#008000">
---------------
第2 轮匹配结果:
Group[0] : ** 这里是不固定的字符串2 **
Group[1] :<font color="#008000">
---------------
第3 轮匹配结果:
Group[0] : ** 这里是不固定的字符串3 **
Group[1] :<font color="#008000">
---------------
*/
3.2 逆序环视应用总结
通过对逆序环视的分析,可以看出,逆序环视中使用不定长度的量词,匹配过程很复杂,代价也是很大的,这也许也是目前绝大多数语言不支持逆序环视,或是不支持在逆序环视中使用不定长度量词的原因吧。
在正则应用中需要注意的几点:
1、 不要轻易在逆序环视中使用不定长度的量词,除非确实需要;
2、 在任何场景下,不只是逆序环视中,不要轻易使用量词修饰匹配范围非常大的子表达式,小数点“ . ”和“ [/s/S] ”之类的,使用时尤其要注意。
注:本文分析过程有部分为自己的猜测,无从考证,如果错漏,还请批评指正。















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









