









1 数据准备
1.1 实验数据基于AMPCamp2015的exercise,原始数据在U盘的/data目录中,首先将数据上传到hdfs
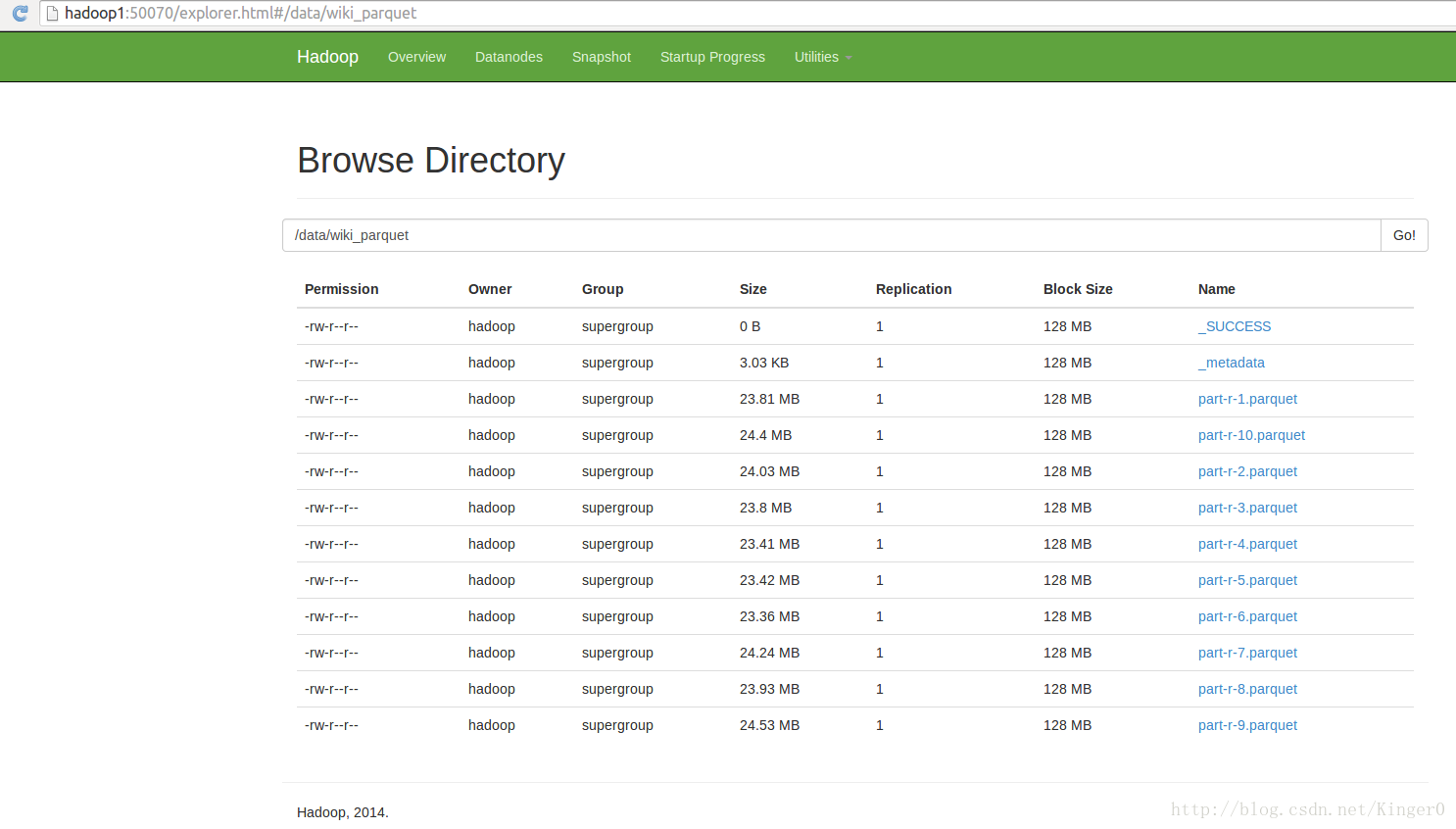
2 开始实验
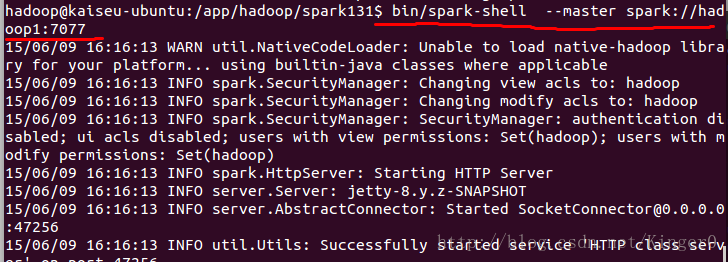
2.1 启动spark-shell
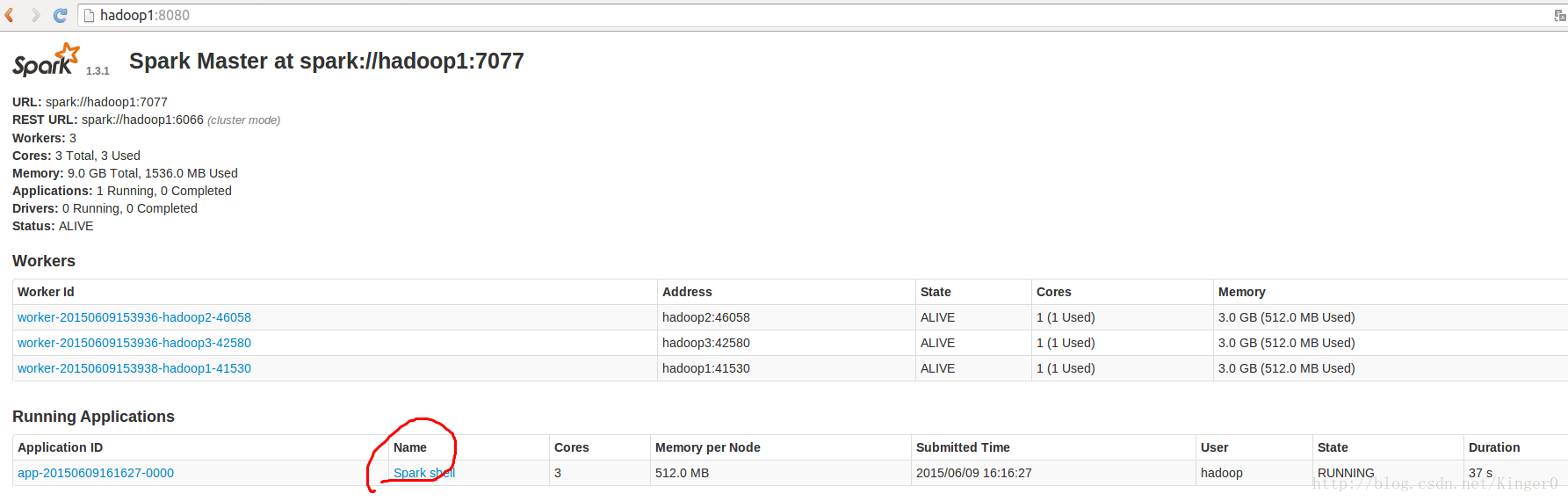
监控界面如下:
2.2 代码
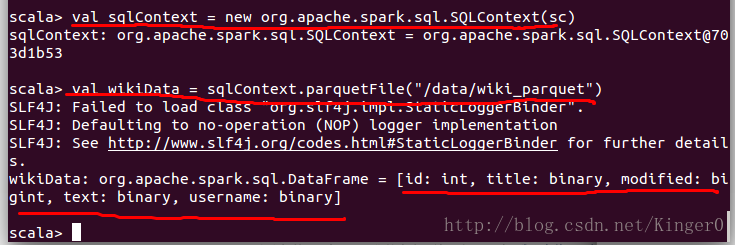
2.2.1 创建SQLContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)

2.2.2 装载数据
首先,装载数据,装载的数据格式为parquet,Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.(Parquet是一种面向列存存储的文件格式,Cloudera的大数据在线分析(OLAP)项目Impala中使用该格式作为列存储。Apache Parquet 是一个列存储格式,主要用于 Hadoop 生态系统。对数据处理框架、数据模型和编程语言无关。)
上一步中上传到hdfs的数据/data/wiki_parquet中保存的是来自于wikipedia的包含“berkeley”的网页
val wikiData = sqlContext.parquetFile("/data/wiki_parquet")
2.2.3 首先,看一共有多少数据
wikiData.count()

结果为:

2.2.4 将数据注册为表
wikiData.registerTempTable("wikiData")
并进行查询:
val countResult = sqlContext.sql("SELECT COUNT(*) FROM wikiData").collect()

得到的结果为:
并进行查询:
val countResult = sqlContext.sql("SELECT COUNT(*) FROM wikiData").collect()
得到的结果为:

val sqlCount = countResult.head.getLong(0)

3 查询
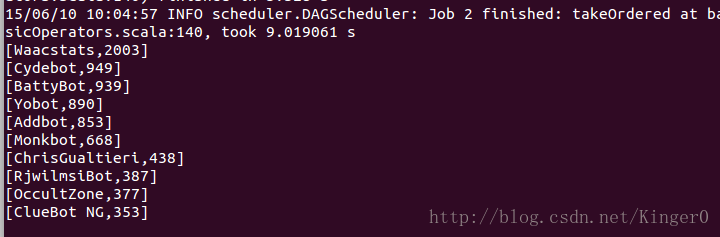
3.1 查询创建网页最多的前10位用户
sqlContext.sql("SELECT username, COUNT(*) AS cnt FROM wikiData WHERE username <> '' GROUP BY username ORDER BY cnt DESC LIMIT 10").collect().foreach(println)
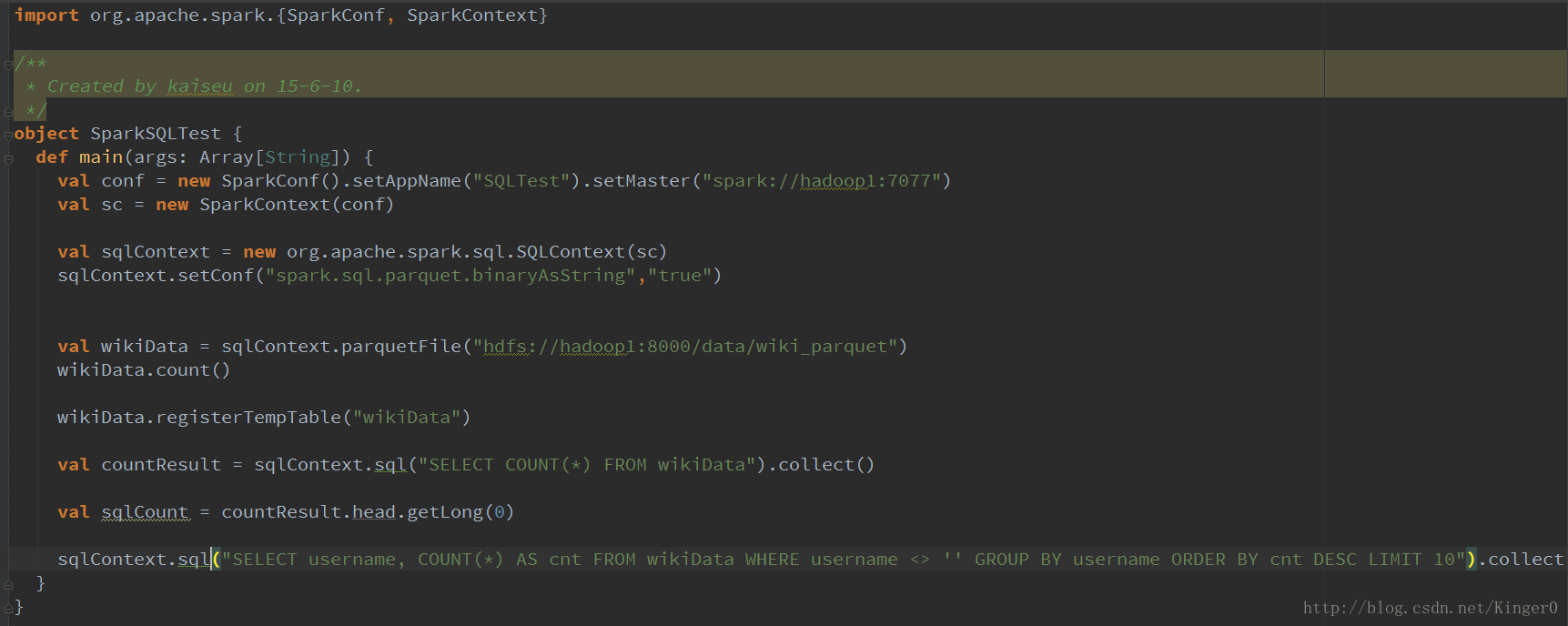
4 IDEA提交
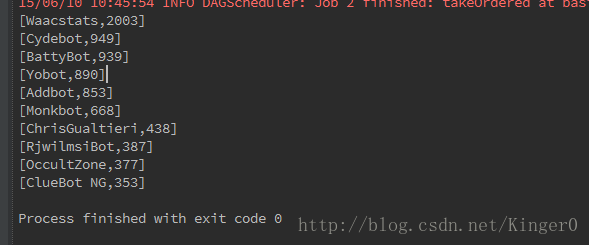
结果:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









