







一、前言
最近小编跳槽了,刚好入职了一家移动互联网公司。非常的幸运。来新公司后的第一个项目就是对通知服务进行优化改进,其中,一个业务就是当用户登录的时候,就会登录访问通知表,根据用户id加载通知信息。由于通知量已经上亿了,在查询的时候是非常慢的。
以前的项目中,使用的mycat做数据库中间件,对数据库进行分库分表操作的。这个操作也是挺好的。同事提出了另一种方案——使用Sharding-Jdbc进行分库分表。
二、Sharding-Jdbc介绍
Sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,是继dubbox、elastic-job之后ddframe开源的第三个项目。
Sharding-JDBC直接封装jdbc协议,可理解为增强版的JDBC驱动,旧代码迁移成本几乎为零,定位为轻量级java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy层。
##主要包括以下特点:
-
可适用于任何基于java的ORM框架,如:JPA、Hibernate、Mybatis、Spring JDBC Template,或直接使用JDBC
-
可基于任何第三方的数据库连接池,如:DBCP、C3P0、Durid等
-
理论上可支持任意实现JDBC规范的数据库。目前仅支持mysql
-
分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
-
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
-
性能高,单库查询QPS为原生JDBC的99.8%,双库查询QPS比单库增加94%。
架构
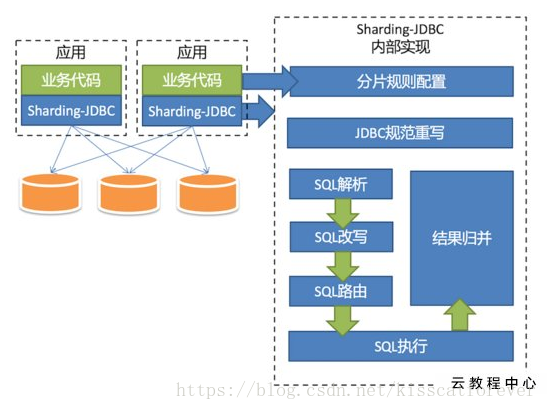
核心概念
LogicTable:数据分片的逻辑表,对于水平拆分的数据库(表)来说,是同一类表的总称。如:订单数据根据主键尾数拆分为10张表,分表是t order 0到t order 9,他们的逻辑表名为t_order。
-
ActualTable:分片数据中真实存在的物理表。
-
DataNode:数据分片的最小单元,由数据源名称和数据表组成。如:ds 1.t order_0。
-
DynamicTable:逻辑表和物理表不一定需要在配置规则中静态配置。如,按照日期分片的场景,物理表的名称随着时间的推移会产生变化。
-
BindingTable:指在任何场景下分片规则均一致的主表和子表。例:订单表和订单项表,均按照订单ID分片,则此两张表互为BindingTable关系。BindingTable关系的多表关联查询不会出现笛卡尔积关联,查询效率将大大提升。
-
ShardingColumn:分片字段用于将数据库(表)水平拆分的字段。
-
ShardingAlgorithm:分片算法。
-
SQL Hint:对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。
三、实战操作
##3.1 建立数据库和表
分别建了两个库两张表:
CREATE DATABASE `user_0`;
CREATE TABLE `user_info_1` (
`user_id` bigint(19) NOT NULL,
`user_name` varchar(45) DEFAULT NULL,
`account` varchar(45) NOT NULL,
`password` varchar(45) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_info_0` (
`user_id` bigint(19) NOT NULL,
`user_name` varchar(45) DEFAULT NULL,
`account` varchar(45) NOT NULL,
`password` varchar(45) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE DATABASE `user_1`;
CREATE TABLE `user_info_1` (
`user_id` bigint(19) NOT NULL,
`user_name` varchar(45) DEFAULT NULL,
`account` varchar(45) NOT NULL,
`password` varchar(45) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_info_0` (
`user_id` bigint(19) NOT NULL,
`user_name` varchar(45) DEFAULT NULL,
`account` varchar(45) NOT NULL,
`password` varchar(45) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.2 添加sharding-jdbc依赖
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>2.0.3</version>
</dependency>
添加后,完整的pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--sharding-jdbc -->
<!--<dependency>-->
<!--<groupId>com.dangdang</groupId>-->
<!--<artifactId>sharding-jdbc-core</artifactId>-->
<!--<version>1.3.3</version>-->
<!--</dependency>-->
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3.3 整合sharding-jdbc
当你mybatis调整好了的时候,这个时候就该加sharding jdbc的配置了,接下如果出问题,应该先朝sharding jdbc的方向去考虑.
从目录结构中我们可以看到,我有一个config包,我把我的配置都写在这里面的,首先,我们先实现我们的分库分表的策略。
分库策略的类,DemoDatabaseShardingAlgorithm:
package com.example.demo.config;
import com.google.common.collect.Range;
import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
import java.util.LinkedHashSet;
public class DemoDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
for (String each : collection) {
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
使用io.shardingjdbc,就应该实现PreciseShardingAlgorithm接口,然后实现doSharding方法,对应SQL中的=, IN,还有RangeShardingAlgorithm接口中,对应SQL中的BETWEEN AND,因为我只需要=,in操作,所以只实现了PreciseShardingAlgorithm接口,你如果都需要,你可以都实现(千万不要忽略了一个类可以实现多个接口)。
如果你使用的当当网的sharding jdbc,那么你需要实现SingleKeyDatabaseShardingAlgorithm这个接口,实现其中的三个方法,我注释到的部分就是原来我用当当网的sharding jdbc的实现。
分表策略的类,DemoTableShardingAlgorithm:
package com.example.demo.config;
import com.google.common.collect.Range;
import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue;
import io.shardingjdbc.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
import java.util.LinkedHashSet;
//public class DemoTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> {
public class DemoTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
for (String each : collection) {
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
与分库的步骤一致,也是需要实现PreciseShardingAlgorithm和RangeShardingAlgorithm两个接口的类。剩下的就是最重要的部分,sharding jdbc的配置:
DataSourceConfig:
package com.example.demo.config;
import io.shardingjdbc.core.api.config.ShardingRuleConfiguration;
import io.shardingjdbc.core.api.config.TableRuleConfiguration;
import io.shardingjdbc.core.api.config.strategy.StandardShardingStrategyConfiguration;
import io.shardingjdbc.core.jdbc.core.datasource.ShardingDataSource;
import org.apache.commons.dbcp.BasicDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.*;
@Configuration
@MapperScan(basePackages = "com.example.demo.mapper", sqlSessionTemplateRef = "testSqlSessionTemplate")
public class DataSourceConfig {
/**
* 配置分库分表策略
*
* @return
* @throws SQLException
*/
@Bean(name = "shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig;
shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getUserTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("user_info");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoDatabaseShardingAlgorithm.class.getName()));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoTableShardingAlgorithm.class.getName()));
return new ShardingDataSource(shardingRuleConfig.build(createDataSourceMap()));
}
/**
* 设置表的node
* @return
*/
@Bean
TableRuleConfiguration getUserTableRuleConfiguration() {
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("user_info");
orderTableRuleConfig.setActualDataNodes("user_${0..1}.user_info_${0..1}");
orderTableRuleConfig.setKeyGeneratorColumnName("user_id");
return orderTableRuleConfig;
}
/**
* 需要手动配置事务管理器
*
* @param shardingDataSource
* @return
*/
@Bean
public DataSourceTransactionManager transactitonManager(DataSource shardingDataSource) {
return new DataSourceTransactionManager(shardingDataSource);
}
@Bean
@Primary
public SqlSessionFactory sqlSessionFactory(DataSource shardingDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(shardingDataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return bean.getObject();
}
@Bean
@Primary
public SqlSessionTemplate testSqlSessionTemplate(SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
private Map<String, DataSource> createDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
result.put("user_0", createDataSource("user"));
result.put("user_1", createDataSource("user_1"));
return result;
}
private DataSource createDataSource(final String dataSourceName) {
BasicDataSource result = new BasicDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setUrl(String.format("jdbc:mysql://localhost:3306/%s", dataSourceName));
result.setUsername("root");
result.setPassword("123456");
return result;
}
}
当你遇到一个问题:意思差不多是,需要一个数据源,但是发现好几个,你可以在getShardingDataSource()这个方法上添加注解:@Primary,设置默认数据源,还有一个重中之重的部分,在Applicatian这个启动类中:加上注解,主要是为了防止代码的自动配置。
@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})
@EnableTransactionManagement(proxyTargetClass = true)
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})
@EnableTransactionManagement(proxyTargetClass = true)
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
补充:📅 ⌚️2020-08-13
为了生成全局唯一的id:
项目发布生产的时候,一般不是只发布一台,为了保证高可用,我们一般发布多台机器,这样多台的时候就会遇到并发问题。就有可能生成相同的id,可以设置workerid,根据发布机器的ip和线程号 % 1024 来获得workerId。这样就唯一了。
//解决主键冲突问题
Long workerId=(IPv4Util.getLocalIpToLong()+Thread.currentThread().getId())%1024;
logger.info("workerId={}",workerId);
appNotifyDTO.setId((Long) defaultKeyGenerator.generateKey());
四、小结
说实话,sharding-jdbc的体验和mycat是一样的, 都感觉不到分了很多表。不同的是,sharding-jdbc的分库分表更加的简单,不是数据库中间件。操作更加的方便。
代码github地址:https://github.com/AresKingCarry/ShardingJDBCDemo















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











