










SQL SERVER 2017 提供了图形数据库功能(实际是在表级别提供),图形数据库集成到关系型数据库中,便于关系型数据库使用SQL操作。图形数据库属于NOSQL类型,如Neo4j 等。
图形数据库是一个集合节点(或顶点) 和边缘 (或关系)。 节点表示实体 (例如,一个人或组织),边缘表示连接 (如组件或好友) 的两个节点之间的关系。 节点和边缘可能具有与之关联的属性。总的来说,图形数据库就是存储实体与关系的数据库。
基础概念:
节点表:存储一类节点信息(一般实体表),如“人员表”、“城市表”、“餐馆表”等
边缘表:关系表,存储节点之间的有向关系。
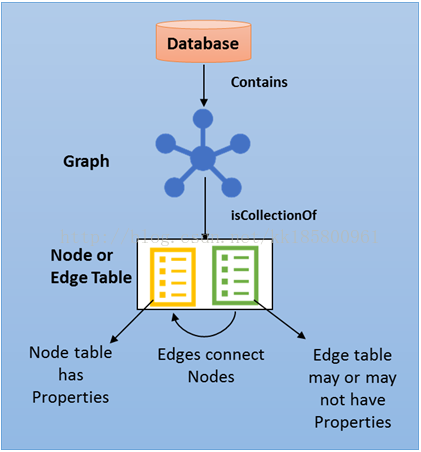
说到关系,我们一直都接触过。比如部门人员关系、物品层级分类等,都用到父级别,这是比较简单的关系模型。但以往我们用的这种关系,我们默认是知道父级别和子级别对应的字段,这样才能关联。因为只有实体,没有关系,当我们需要对关系标注一些额外信息时(如我们之间关系友好程度、权重等),就可能需要单独的一张关系表了。多麻烦,原本有id和父级id就体现关系了,现在又得多家一张表。查询的时候还要按顺序递归父节点。
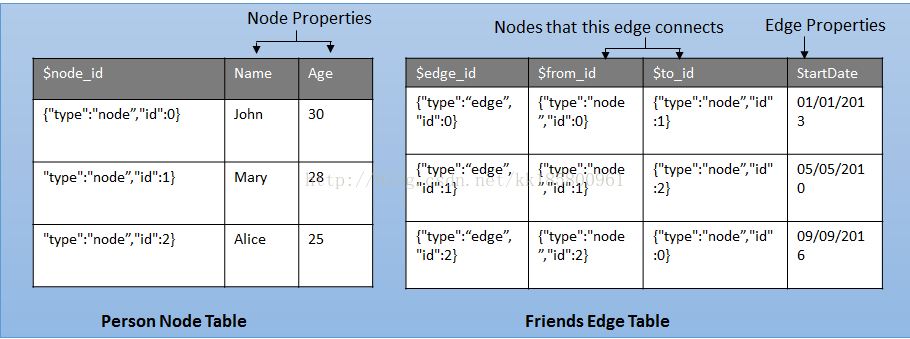
节点表和边缘表都可以添加自己的属性(字段),创建节点表需指定“NODE”,创建边缘表需制定“EDGE”。节点表和边缘表都会添加隐藏的字段,如下图出属性之外的字段。
示例:
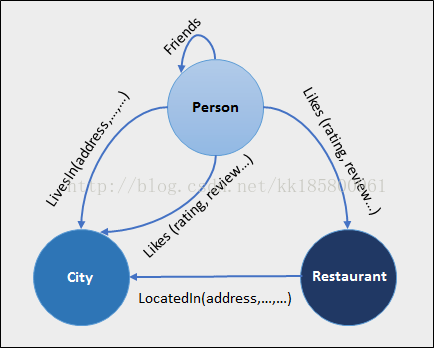
创建三个节点对象表: Person(人)、Restaurant(餐馆)、City(城市)
它们之前的边缘表(关系表):likes(人喜欢的城市、餐馆)、friendOf(人与人之间的好友关系)、livesIn(人生活在哪个城市)、locatedIn(餐馆位于哪个城市)
脚本如下:
-- 创建一个数据库
CREATE DATABASE graphdemo;
go
USE graphdemo;
go
-- 创建节点表(声明为 NODE)
CREATE TABLE Person (
ID INTEGER PRIMARY KEY,
name VARCHAR(100)
) AS NODE;
go
CREATE TABLE Restaurant (
ID INTEGER NOT NULL,
name VARCHAR(100),
city VARCHAR(100)
) AS NODE;
go
CREATE TABLE City (
ID INTEGER PRIMARY KEY,
name VARCHAR(100),
stateName VARCHAR(100)
) AS NODE;
go
-- 创建边缘表(声明为 EDGE)
CREATE TABLE likes (rating INTEGER) AS EDGE;
CREATE TABLE friendOf AS EDGE;
CREATE TABLE livesIn AS EDGE;
CREATE TABLE locatedIn AS EDGE;
go
-- 插入节点数据
INSERT INTO Person VALUES (1,'John');
INSERT INTO Person VALUES (2,'Mary');
INSERT INTO Person VALUES (3,'Alice');
INSERT INTO Person VALUES (4,'Jacob');
INSERT INTO Person VALUES (5,'Julie');
go
INSERT INTO Restaurant VALUES (1,'Taco Dell','Bellevue');
INSERT INTO Restaurant VALUES (2,'Ginger and Spice','Seattle');
INSERT INTO Restaurant VALUES (3,'Noodle Land', 'Redmond');
go
INSERT INTO City VALUES (1,'Bellevue','wa');
INSERT INTO City VALUES (2,'Seattle','wa');
INSERT INTO City VALUES (3,'Redmond','wa');
go
-- 插入边缘数据,需要节点提供 $node_id 和 $from_id 两个字段(属于隐藏字段)
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 1), (SELECT $node_id FROM Restaurant WHERE id = 1),9);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 2), (SELECT $node_id FROM Restaurant WHERE id = 2),9);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 3), (SELECT $node_id FROM Restaurant WHERE id = 3),9);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 4), (SELECT $node_id FROM Restaurant WHERE id = 3),9);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 5), (SELECT $node_id FROM Restaurant WHERE id = 3),9);
go
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 1),(SELECT $node_id FROM City WHERE id = 1));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 2),(SELECT $node_id FROM City WHERE id = 2));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 3),(SELECT $node_id FROM City WHERE id = 3));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 4),(SELECT $node_id FROM City WHERE id = 3));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 5),(SELECT $node_id FROM City WHERE id = 1));
go
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 1),(SELECT $node_id FROM City WHERE id =1));
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 2),(SELECT $node_id FROM City WHERE id =2));
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 3),(SELECT $node_id FROM City WHERE id =3));
go
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 1), (SELECT $NODE_ID FROM person WHERE ID = 2));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 2), (SELECT $NODE_ID FROM person WHERE ID = 3));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 3), (SELECT $NODE_ID FROM person WHERE ID = 1));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 4), (SELECT $NODE_ID FROM person WHERE ID = 2));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 5), (SELECT $NODE_ID FROM person WHERE ID = 4));
go
当查询关系的时候,需要新的条件关键字 MATCH (更多参考MATCH (Transact SQL))
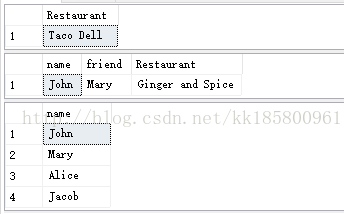
-- 找到 John 喜欢的餐馆
SELECT Restaurant.name as Restaurant
FROM Person, likes, Restaurant
WHERE MATCH (Person-(likes)->Restaurant)
AND Person.name = 'John';
go
-- 找到 John 的朋友喜欢的餐馆
SELECT person1.name,person2.name as friend,Restaurant.name as Restaurant
FROM Person person1, Person person2, likes, friendOf, Restaurant
WHERE MATCH(person1-(friendOf)->person2-(likes)->Restaurant)
AND person1.name='John';
go
--有哪些人生活与喜欢的餐馆在同一个城市
SELECT Person.name
FROM Person, likes, Restaurant, livesIn, City, locatedIn
WHERE MATCH (Person-(likes)->Restaurant-(locatedIn)->City AND Person-(livesIn)->City);
go
查询结果:
其他元素据查看:
--找出节点表和边缘表
select * from sys.tables where is_node =1
select * from sys.tables where is_edge =1
go
--查看节点表和边缘表的字段(有较多隐藏字段)
select [object_id],name,is_hidden,graph_type,graph_type_desc,*
from sys.columns where [object_id] = OBJECT_ID('Person')
go
select [object_id],name,is_hidden,graph_type,graph_type_desc
from sys.columns where [object_id] = OBJECT_ID('friendOf')
go
最后,删除测试数据:
USE graphdemo;
go
DROP TABLE IF EXISTS likes;
DROP TABLE IF EXISTS Person;
DROP TABLE IF EXISTS Restaurant;
DROP TABLE IF EXISTS City;
DROP TABLE IF EXISTS friendOf;
DROP TABLE IF EXISTS livesIn;
DROP TABLE IF EXISTS locatedIn;
go
USE master;
go
DROP DATABASE graphdemo;
go注意:字段 $node_id、$edge_id、$from_id、$to_id 是不可更改的,若要更改,只能删除重新添加














 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









