







自己写的一篇老文章了,移到CSDN,打算以CSDN博客为主了。
在大学学习概率论的时候,总感觉有些枯燥和无趣,而且没有什么实际的用途,最近由于课题需要,研究了一下概率方面的书籍,才发现概率实际上用途广泛而富有魅力。
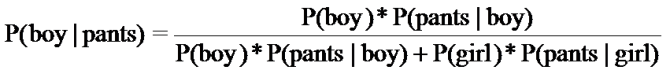
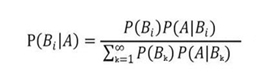
怎么样,很简单吧?
可能有些童鞋可能就不明白了,这个公式能和人工智能扯上什么关系呢?
现在我们把刚才的问题改改,不让你求具体概率是多少,而是问你他(她)是男生的可能性更高,还是女生的可能性高?这貌似和原来的问题没有区别,但仔细观察你会发现,由于我们只要求判断谁的可能性更高,因此不用计算精确值,判断概率谁大谁小就可以了;而且男生概率也好,女生概率也好,贝叶斯公式的分母都没有发生变化,因此只需要比较分子的大小就可以了。
于是原来的问题变成了求argmax (P(Bi)*P(A|Bi)),这个怎么理解呢?这样理解比较容易:一个穿裤子的人更可能是男生还是女生,根据两个条件进行比较:男生(女生)在学生总人数中的比例,以及男生(女生)穿裤子的概率,比较这两个值即可。很明显:男生占人数的60%,女生占40%;男生总是穿裤子(100%),而女生只有50%概率穿裤子,因此,这个人更可能是男生。
看出端倪了么,什么没有,那么我们举一个和计算机技术相关一点的例子,这个也是一个非常经典的例子。
当用户输入一个英语单词时,如果不是一个正确单词,那么计算机推算出用户最可能想输入的单词是哪一个,并显示到屏幕上。这其实是一个拼写检查器,目前goolge和baidu等搜索引擎都有的基本功能。那么我们该如何解决呢?
我们首先要解决的是如何判断一个单词是否拼写正确。这个不难实现,将所有单词录入一个单词库,再逐个比较即可。
其次,要判断当前写错的单词更可能是哪一个单词,就要比较单词谁的出现频率更高(男生所占比重和这个其实是一个意思,占的比重越大,出现的频率也就越高),以及谁更容易被误写成当前这个错误单词(和穿裤子的概率相似)。
但是这里有难题:因为英文单词太多,常用的少说也有万把个,逐个比较费时费力。这时让我们联想一下人是怎么解决这个问题的,当人猜测一个错写的单词时,通常会排除那些差异很大的单词,例如:看到worls这个词,会把hello、java等等不相干的词汇排除,只保留相似的如:word、world等等词汇,再从候选单词中选出出最合理的单词。因为常识(注意:常识出现了,先验概率出现了!)告诉我们,通常人们会写错单词,但不会错得面目全非。
好的,按照这个思想,我们只保留几个比较相似的单词作为候选单词,然后去比较它们的两个概率。
单词出现频率比较好办,我们建立一个文本库,录入大量的英文书刊杂志,然后去统计每个单词在文本库中出现的频率。
单词误写的概率就比较难办了,因为导致将单词错写成当前这个错误单词的原因有很多,比如:单词比较相似,键盘按键太小等等。为了简化解决方案,我们根据一个常识(又是常识,又是先验概率):导致一个单词误写成另一个词语的主要原因是这两个词汇的相似度。相似度越高,误写率越高,因此设定备选单词与错写单词的相似度越高,P(A|Bi)值越高。
为了更简化过程,我们又做一个近似,干脆连P(Bi)*P(A|Bi)都懒得算了,而是这样设定:当有多个单词时,P(A|Bi)最高的单词直接胜出,例如:当前错误单词是happu,而备选单词有hap和happy,由于hap与happu差了2个字母,而happy只差了1个,因此直接选择happy,而不再计算hap和happy谁的出现的频率更高(这种假设肯定会导致判断精度下降,好处就是实现很容易);当有多个单词的P(A|Bi)相同且P(A|Bi)同为最高时,再去计算P(Bi)谁大谁小。
于是一个单词拼写检查器就完成了。
我写了一个,下载地址: http://iask.sina.com.cn/u/ish?uid=1171839324
感兴趣的话大家可以下载试试。
现在我们再来考虑单词翻译:用户输入一个中文单词,将其翻译成英文单词。这个其实有其他方法实现,但是使用概率也可以完成。
和刚才一样,我们首先对候选词进行一次narrow,排除那些完全不沾边的英文词汇,只保留那些和这个中文单词有点沾边的英文词汇。
其次,计算每个英文候选词被理解为该中文词语的可能性,通常核心词义高于次要词义,次要词义高于引申词义,我们首先选择理解可能性最高的英文候选词作为答案,只有当多个候选词P(A|Bi)相同且P(A|Bi)同为最高时,再去计算P(Bi),即出现频率谁大谁小。
于是,一个简单的中译英的词汇翻译工具就完成了。由于时间问题,没有去实现,但原理和刚才的拼写检查器是一样的。
好了,我们已经越来越接近人工智能的领域了,现在我们举一个人工智能领域的例子:用户输入一段英文,让计算机翻译成中文。
晃眼一看,似乎和刚才第二个例子没有太大区别,其实这里有着很大的难题。
根据贝叶斯公式,要判断P(S1,S2,S3,。。。,Sn)*P(O1,O2,O3,。。。,On| S1,S2,S3,。。。,Sn),其中S1,S2,S3,。。。,Sn表示由若干的中文词语构成的一段话,O1,O2,O3,。。。,On表示由若干英文词语构成的一段话。
根据联合概率公式:P(S1,S2,S3,。。。,Sn) = P(S1)*P(S2|S1)*P(S3|S1,S2,S3)。。。。。这是一个非常令人头痛的问题,按照人类语言的理解,要探讨S1,S2,S3,。。。,Sn这段话构成中文语句的可能性,就要分析词语S1出现的概率,以及在S1出现的条件下,S2出现的概率,以及S1,S2出现的条件下,S3出现的概率,以及S1,S2,S3出现的情况下,S4出现的概率。。。如此下去,求解过程变得异常复杂。从人类理解的角度来讲,这要求计算机从概率的角度来解释清楚人类说一句话的语义是什么,这也是为什么计算机难以准确翻译长篇文章的原因。
由于贝叶斯没能解决上述问题,因此不得不引入其他的方法。目前最为流行,也是比较有效的方法,是引入隐马尔科夫模型,该模型给出了两个关键假设:即马尔科夫性与独立输出假设,使得上述问题得到解决,但这样做是有代价的,代价就是准确度的降低。即便如此,采用隐马尔科夫模型的概率翻译系统也比从前的系统进步得多。据统计:基于隐马尔科夫模型的翻译系统已将错误率由传统模式识别系统的30%降低到10%,不得不说是一大进步。
对于人工智能的其他领域:机器视觉、语音识别等等,我们不妨认为是将图画、语音翻译成文字的翻译系统,在根本上与上述系统是一样的,因此也能使用概率方法进行解决。
小小的概率却隐藏着如此多的神奇,不得不感叹数学的神奇!














 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









