







此文由香港中文大学汤晓鸥教授团队于2014年发表
论文链接:http://mmlab.ie.cuhk.edu.hk/pdf/YiSun_CVPR14.pdf
1.研究问题
主要通过神经网络学习图像特征,通过分类器验证人脸。
2.此文工作
2.1 人脸特征表达
2.1.1 网络结构
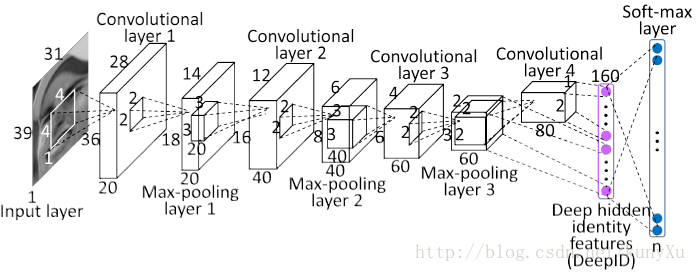
一共四个卷积层,前三个卷基层后都有Max-pooling
在最后一个隐藏层,是由Max-pooling layer3 + Convolutional layer4 全连接而得,为160维。这样的连接方式既考虑到了局部的特征,也考虑到全局特征
最后的soft-max训练时使用,检测时不用,而如果使用soft-max进行分类、识别,效果很差
用于人脸识别和人脸验证的特征是最后一个隐藏层,称为DeepID。
2.1.2 人脸特征

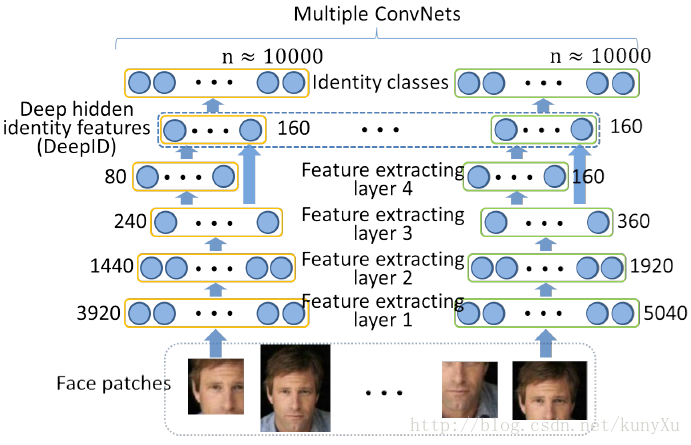
将输入图片缩放为三个比例尺大小,并且分为彩色和灰度图像,最后还将图片切分为10个patch, 所以最后输入的patch 数为:3 2 10=60。
对每一种patch 都训练一个卷积网络,一共需要训练60个卷积网络。
所有patch 输出的特征连接起来,一共为19200(160 2 60),再利用PCA降维到150维用于人脸验证与区分。
2.2 人脸验证方法
2.2.1 联合贝叶斯
通过类内方差与类间方差之间的关系判断两个特征是否为一张脸。有一些推导,具体过程不详述。
2.2.2 神经网络
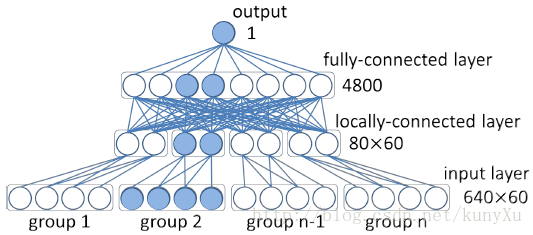
分成60个group,每个group对应一个patch,其中有160(单个网络输出)* 2(flip) * 2(对比的两张脸)=640维。输出为单一特征,表示相似性,由sigmoid生成。
2.3 实验与讨论
训练数据:CeleFaces+, 有10177人,202599张图片;8700人训练DeepID,1477人训练联合贝叶斯分类器。准确率达到97.45%
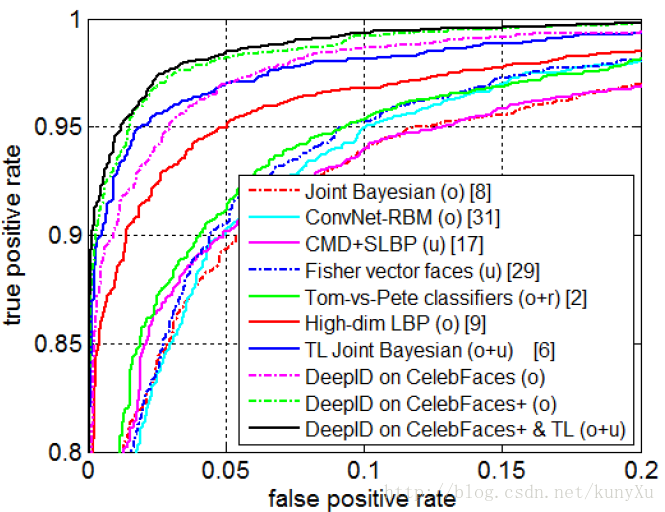
其他一些结论:
使用multi-scale patch 的卷积网络效果比只用一张图片好
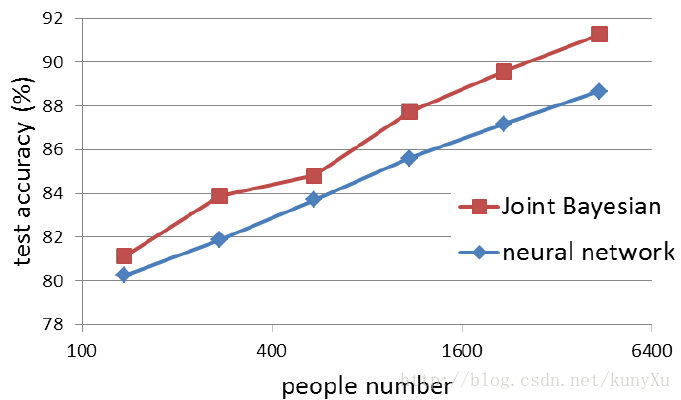
训练样本中的身份数量越多,训练得出的模型越优
3.总结
提出将人脸图像分为多个patch, 对每个patch 分别训练神经网络,这样的效果明显优于纯粹输入图片训练。进一步提高了精度。














 7076
7076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









