







概述
AderTemplate是一个小型的模板引擎。无论是拿来直接使用还是用来研究模板引擎实现方式,都是一个不错的选择。本文尝试对其源代码做一些分析。
数据流程
AderTemplate的数据处理流程可以总结为:
模版文件 -> 模版分析 -> Template对象 -> 分析处理Template的Element集合 -> 输出目标文本
模版文件 -> 模版分析 -> Template对象 -> 分析处理Template的Element集合 -> 输出目标文本
模版语法
简化描述如下:
1,变量替换 :如#variable#
2,循环语句 :<ad:foreach var="x" collection="#values#" index=”i”></ad:foreach>
3,判断语句 :<ad:if test="#value#"> </ad:if>
详细请参看AderTemplate的相关说明
.
模版分析
模版分析的过程可以分成两步:
1 ,把模版文件分析成Token流 ;
1 ,把模版文件分析成Token流 ;
2,对Token流进行分析,形成Element集合
所以,首先要了解Token和Element的结构与异同。
Token的类结构:
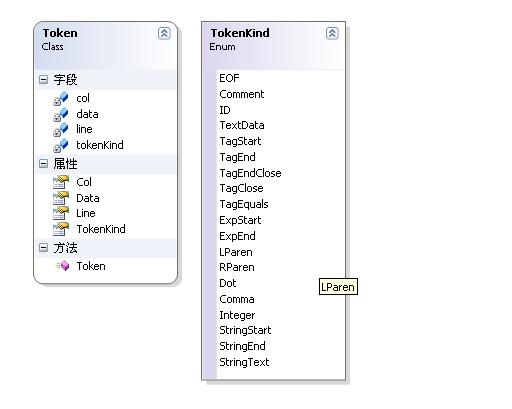
TokenKind(Token的类型)的详细说明:
|
TokenKind
|
说明
|
|
EOF
|
结束符
|
|
Comment
|
注释,但在AderTemplate没看到具体实现
|
|
ID
|
这个比较难描述,下面会通过输出Token流来直官了解下ID
|
|
TextData
|
文本数据,不包含模版语法的独立文本区
|
|
TagStart
|
Tag的开始标记,即<ad: 注:Tag是一个Element,后面详述
|
|
TagEnd
|
Tag的结束符,即 > ,注意与TagClose的区别
|
|
TagEndClose
|
Tag的自闭结束符 ,即 />
|
|
TagClose
|
Tag的结束标记 即</ad: 与<ad:对应,所以与TagEnd很容易区别
|
|
TagEquals
|
Tag的=符号。与Tag无关的=属于TextData,非TagEquals
|
|
ExpStart
|
在AderTemplate中,语法#v#被定义为Expression.左#为ExpStart
|
|
ExpEnd
|
在AderTemplate中,语法#v#被定义为Expression.右#为ExpEnd
|
|
LParent
|
左括号 (
|
|
RParent
|
右括号 )
|
|
Dot
|
即一个点 .
|
|
Comma
|
逗号 ,
|
|
Integer
|
数字
|
|
StringStart
|
文本的开始符,即”
|
|
StringEnd
|
文本的结束符,即”
|
|
StringText
|
How to description ?
|
为了获得更直观的认识。下面尝试把一个简单的模版文件分析的Token流输出。
模版文件,我们暂且命名为templateFile
模版文件,我们暂且命名为templateFile
<ad:foreach collection="#GetBookList(3)#" var="book" index="i">
<tr>
<td>#i#</td>
<td>#book.BookName#</td>
<td>#book.BookCount#</td>
</tr>
</ad:foreach>
分析的代码:
static void Main(string[] args)
{
string data = string.Empty;
using (System.IO.StreamReader reader = new System.IO.StreamReader(templateFile))
{
data = reader.ReadToEnd();
}
//模版分析,形成Token流
TemplateLexer lexer = new TemplateLexer(data);
Console.WriteLine("=======开始输出TemplateLexer分析出Token流=======");
do
{
Token token = lexer.Next();
Console.WriteLine("/tToken类型:{0}/t行列:({1}, {2})/t数据:{3}", token.TokenKind.ToString(), token.Line, token.Col
, token.Data.Replace("/r/n", ""));
if (token.TokenKind == TokenKind.EOF)
break;
} while (true);
Console.WriteLine("=======结束输出TemplateLexer分析出Token流=======/r/n");
}
输出结果:
 =======开始输出TemplateLexer分析出Token流======= Token类型:TextData 行列:(1, 1) 数据:= Token类型:TagStart 行列:(2, 1) 数据:<ad: Token类型:ID 行列:(2, 5) 数据:foreach Token类型:ID 行列:(2, 13) 数据:collection Token类型:TagEquals 行列:(2, 23) 数据:= Token类型:StringStart 行列:(2, 24) 数据:" Token类型:ExpStart 行列:(2, 25) 数据:# Token类型:ID 行列:(2, 26) 数据:GetBookList Token类型:LParen 行列:(2, 37) 数据:( Token类型:Integer 行列:(2, 38) 数据:3 Token类型:RParen 行列:(2, 39) 数据:) Token类型:ExpEnd 行列:(2, 40) 数据:# Token类型:StringEnd 行列:(2, 41) 数据:" Token类型:ID 行列:(2, 43) 数据:var Token类型:TagEquals 行列:(2, 46) 数据:= Token类型:StringStart 行列:(2, 47) 数据:" Token类型:StringText 行列:(2, 48) 数据:book Token类型:StringEnd 行列:(2, 52) 数据:" Token类型:ID 行列:(2, 54) 数据:index Token类型:TagEquals 行列:(2, 59) 数据:= Token类型:StringStart 行列:(2, 60) 数据:" Token类型:StringText 行列:(2, 61) 数据:i Token类型:StringEnd 行列:(2, 62) 数据:" Token类型:TagEnd 行列:(2, 63) 数据:> Token类型:TextData 行列:(2, 64) 数据:<tr> <td> Token类型:ExpStart 行列:(4, 7) 数据:# Token类型:ID 行列:(4, 8) 数据:i Token类型:ExpEnd 行列:(4, 9) 数据:# Token类型:TextData 行列:(4, 10) 数据:</td> <td> Token类型:ExpStart 行列:(5, 7) 数据:# Token类型:ID 行列:(5, 8) 数据:book Token类型:Dot 行列:(5, 12) 数据:. Token类型:ID 行列:(5, 13) 数据:BookName Token类型:ExpEnd 行列:(5, 21) 数据:# Token类型:TextData 行列:(5, 22) 数据:</td> <td> Token类型:ExpStart 行列:(6, 7) 数据:# Token类型:ID 行列:(6, 8) 数据:book Token类型:Dot 行列:(6, 12) 数据:. Token类型:ID 行列:(6, 13) 数据:BookCount Token类型:ExpEnd 行列:(6, 22) 数据:# Token类型:TextData 行列:(6, 23) 数据:</td></tr> Token类型:TagClose 行列:(8, 1) 数据:</ad: Token类型:ID 行列:(8, 6) 数据:foreach Token类型:TagEnd 行列:(8, 13) 数据:> Token类型:EOF 行列:(8, 14) 数据:=======结束输出TemplateLexer分析出Token流=======
=======开始输出TemplateLexer分析出Token流======= Token类型:TextData 行列:(1, 1) 数据:= Token类型:TagStart 行列:(2, 1) 数据:<ad: Token类型:ID 行列:(2, 5) 数据:foreach Token类型:ID 行列:(2, 13) 数据:collection Token类型:TagEquals 行列:(2, 23) 数据:= Token类型:StringStart 行列:(2, 24) 数据:" Token类型:ExpStart 行列:(2, 25) 数据:# Token类型:ID 行列:(2, 26) 数据:GetBookList Token类型:LParen 行列:(2, 37) 数据:( Token类型:Integer 行列:(2, 38) 数据:3 Token类型:RParen 行列:(2, 39) 数据:) Token类型:ExpEnd 行列:(2, 40) 数据:# Token类型:StringEnd 行列:(2, 41) 数据:" Token类型:ID 行列:(2, 43) 数据:var Token类型:TagEquals 行列:(2, 46) 数据:= Token类型:StringStart 行列:(2, 47) 数据:" Token类型:StringText 行列:(2, 48) 数据:book Token类型:StringEnd 行列:(2, 52) 数据:" Token类型:ID 行列:(2, 54) 数据:index Token类型:TagEquals 行列:(2, 59) 数据:= Token类型:StringStart 行列:(2, 60) 数据:" Token类型:StringText 行列:(2, 61) 数据:i Token类型:StringEnd 行列:(2, 62) 数据:" Token类型:TagEnd 行列:(2, 63) 数据:> Token类型:TextData 行列:(2, 64) 数据:<tr> <td> Token类型:ExpStart 行列:(4, 7) 数据:# Token类型:ID 行列:(4, 8) 数据:i Token类型:ExpEnd 行列:(4, 9) 数据:# Token类型:TextData 行列:(4, 10) 数据:</td> <td> Token类型:ExpStart 行列:(5, 7) 数据:# Token类型:ID 行列:(5, 8) 数据:book Token类型:Dot 行列:(5, 12) 数据:. Token类型:ID 行列:(5, 13) 数据:BookName Token类型:ExpEnd 行列:(5, 21) 数据:# Token类型:TextData 行列:(5, 22) 数据:</td> <td> Token类型:ExpStart 行列:(6, 7) 数据:# Token类型:ID 行列:(6, 8) 数据:book Token类型:Dot 行列:(6, 12) 数据:. Token类型:ID 行列:(6, 13) 数据:BookCount Token类型:ExpEnd 行列:(6, 22) 数据:# Token类型:TextData 行列:(6, 23) 数据:</td></tr> Token类型:TagClose 行列:(8, 1) 数据:</ad: Token类型:ID 行列:(8, 6) 数据:foreach Token类型:TagEnd 行列:(8, 13) 数据:> Token类型:EOF 行列:(8, 14) 数据:=======结束输出TemplateLexer分析出Token流=======
对照表格的说明和输出结果。可以把Token理解为特定类型的”文本区’,即把模版文件按照TokenKind定义的类型分解成多个文本区(Token),所以分析模版文件形成的Token流(集合)是一种相对线性的结构。是对模版文件的初步分析与处理。
下面继续说说Element的类体系:
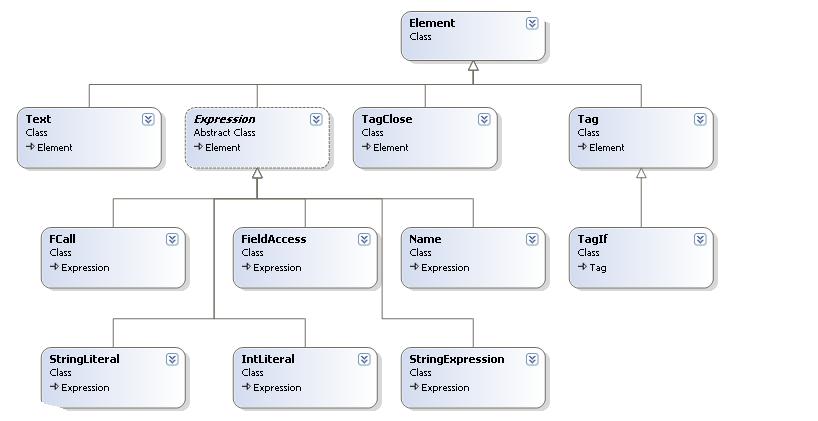
上述类关系图中可以看到Element主要有四个继承体系。
但每个类表达的意义是什么呢?
下面用一个表格做一个简单的说明。
|
类名
|
指代及其含义
|
|
Element
|
各种Element的基类
|
|
Text
|
文本类的Element , 与TokenKind为TextData的Token相似的概念
|
|
TagClose
|
Tag结束符号
|
|
Tag
|
Tag是一个比较广的概念。上述的模版可以表示一个foreach tag
|
|
Expression
|
AderTemplate把语法类似#values#定义为一个Expression
|
|
FCall
|
Expression子类之一,表示该Expression是一个外部函数(Function)
|
|
FieldAccess
|
Expression子类之一,可以近似的理解成”字段访问”,如#book.BookName#
|
|
Name
|
Expression子类之一,可以近似的理解成”外部变量”,如#i#
|
|
StringLiteral
|
Expression子类之一,可以近似的理解成”非数字型变量”。
|
|
IntLiteral
|
Expression子类之一,可以近似的理解成”数字型变量”。
|
|
StringExpression
|
Expression子类之一,但其表示的是Expression的集合封装类
|
为了获得更直观的了解。我们可以通过分析上述的模版文件输出的Element来理解。因为此部分代码比较多。所以不列出了。后面会提供包含本文提到的所有代码的example.
这里需要说明的是Tag Element,Tag是一个复合结构.Tag在不同的分析阶段,会些许不同。
如下面代码的(1)和(2)分析出的Element是不同的。可通过输出结果来跟踪异同。
TemplateLexer lexer = new TemplateLexer(templateData);
TemplateParser parser = new TemplateParser(lexer);
List<Element> elems = parser.Parse(); --(1)
TagParser tagParser = new TagParser(elems);
elems = tagParser.CreateHierarchy(); --(2)
Token与Element异同分析:
在上面已经提到,Token是对模版文件的一种初步分析和分解。AderTemplate对模版文件的分析处理目标是把模版文件表达为一个Template对象。而Template对象的本质其实就是Element集合的封装类,也就是AderTemplate的对模版文件的分析其实是希望把模版文件在程序结构层面表达为一个Element的集合,从上面的Element和Token类关系图可以看出。Element远比Token复杂的多。如果直接从模版文件直接分析成Element集合结构的话,可以预见分析过程会变的相当复杂。所以AderTemplate引入了Token数据结构作为一种辅助分析手段。使得AderTemplate的对模版文件的分析过程变得更流畅和清晰了。程序的架构也变得相对优雅。所以我认为阅读AderTemplate的源代码,关键是理解Token与Element的结构和作用。特别是Element结构。因为它是AderTemplate的基础结构。即解决了在程序层面用什么结构来表达模版文件的问题。
模版分析涉及到的处理类:
TemplateLexer : 从模版文件中分析成Token流。
TemplateParser: 基于Token流分析成初步的Element集合结构。
TagParser
: 把TemplateParser分析出的Element集合做最后的优化处理。
Template(模版)对象:
在AderTemplate中。我们可以简单地认为一个Template就是经过模版分析后形成的最终的Element集合的封装体。
Template(模版)处理:
对Template的Element集合进行分析。生成目标文本。
此过程涉及到的技术其实不复杂,就是反射和委托,所以本文不打算详细分析此过程。否则篇幅过大。而且没什么意义。在后面我会提供一个模拟AderTemplate从Element分析处理到生成目标文本过程的例字。
相关例子
为了辅助理解AderTemplate的整个处理过程。我写了几个例子。
1,输出Token的结构信息。对比模版文件辅助理解Token的结构
1,输出Token的结构信息。对比模版文件辅助理解Token的结构
2,输出从Token流中分析出的Element集合的结构信息。以辅助理解Element的结构。
3,模拟从Element集合中生成目标文本的过程。辅助理解从Element集合到生成目标文本的整个处理流程和过程。这个过程是相对简单的。从这个角度来看,AderTemplate用Element集合来表达模版文件是一个比较优秀的设计。
至于如何从模版文件分析成Element集合(Template对象)则是一个相对复杂的过程了。最好的解释还是源代码本身了。所以就不在此不做更多的分析了。
总结
AderTemplate是一个小型的模版引擎。功能并不算强大。但基本功能已经具备。从应用的角度来说,可能未必是一个最好的选择。但想学习模版引擎的开发。确是一个很不错的选择。我个人认为其架构还是比较优秀的。而且数据处理流程也很清晰。
当写作本文的时候,我阅读AderTemplate的源代码已有好些天了。依然感觉似懂非懂。到是写本文让我把思路给理清了。所以有时候。我觉得。写笔记也是一种学习。:)
本文首发于cnblogs :
http://www.cnblogs.com/kwklover/archive/2007/07/12/815509.html














 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









