







最近也是刚刚开始学Pandas,个人感觉功能太强大导致有些混乱。。。(可能是我刚开始接触吧 )。为了便于记忆,整理下这几天用到的一些东西。
首先这个是我要处理的数据,长这个样子。
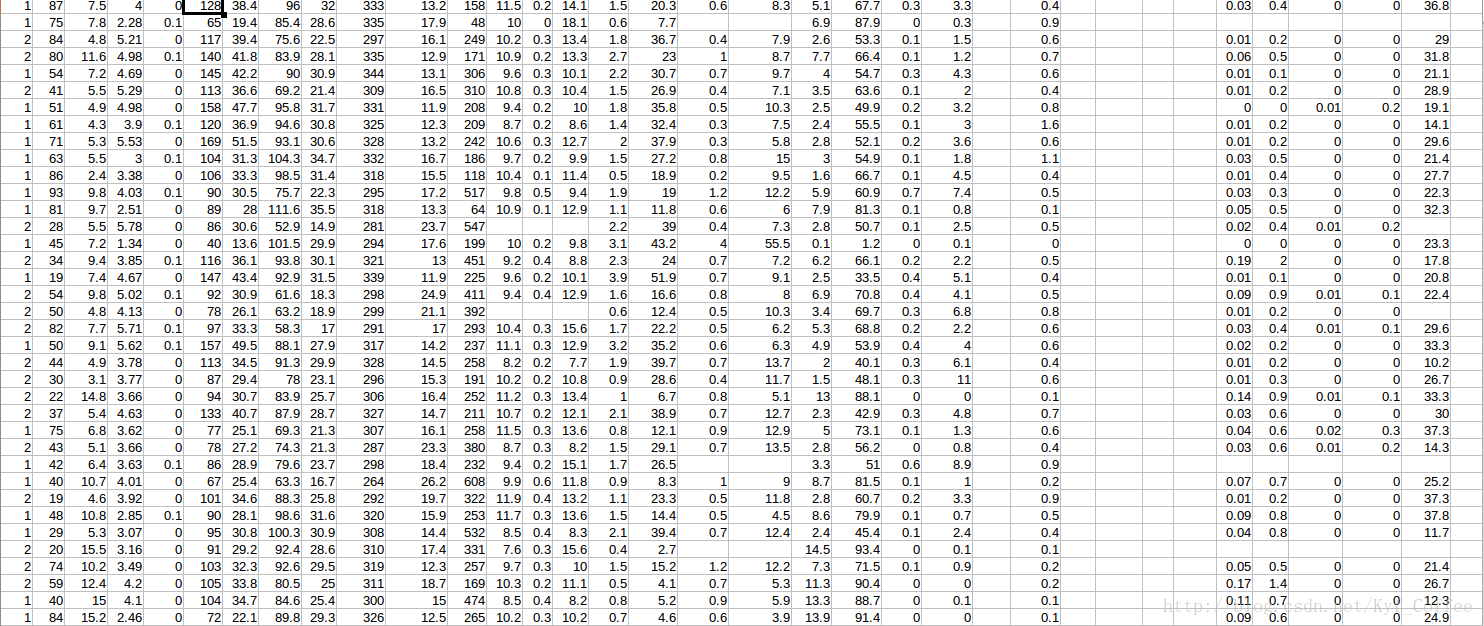
其实就是一个CSV文件,在Pandas中,有专门读取CSV的函数。
data = pd.read_csv('train2.csv')返回的类型为dataFrame,这是一个在pandas中非常重要的类型。将csv读到data后,我们可以直接print出来,其实就和用excel看没啥区别,这对我来说没什么用,但有一个info()函数挺有用的。
print data.info()然后会打印出下边的结果。
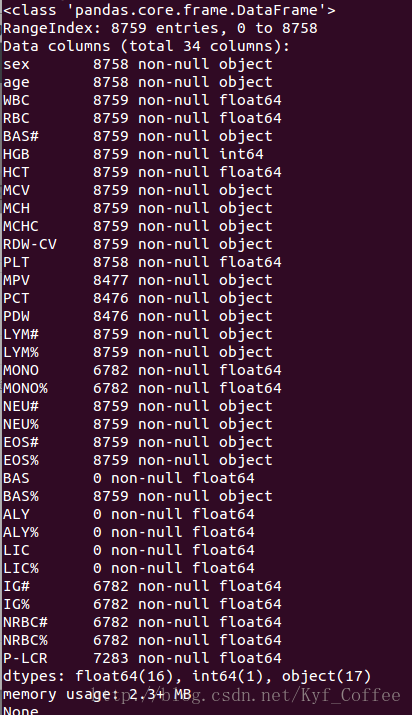
有了这个其实就比肉眼来看好多了,它把里边的每列的信息都告诉我了。首先看数据类型,里边有float64,int64,object这三种,查了一下,除了这三种以外,pandas中还有时间类型datetime和布尔型bool。
然后就开始处理数据,首先可以看到其中有四列数据为0,也就是全空,这个就没啥用了,可以直接把这四列删了,pandas里边提供了多种删除的办法,比如drop(),这个函数就是可以根据你给的列的名字就可以删除对应的列了,用法很简单,具体怎么用可以查看下官方文档。但其实这里就有第一个问题了,虽然也不是太大的问题,但作为一个懒人,我觉得如果有一份新的数据,里边有1W列(假如啊),其中300个是空的,我不至于要把这300个列名都写上吧。。(可能是我目前只知道这个函数是这么用的)。所以我就继续找有没有别的方法,然后就发现了一个更好的选择。
pandas里对于空数据用NAN表示,然后自然的,它就有函数对空数据项处理。dropna()就是干这个的。这是文档。它的作用就是帮你检测空数据然后删去,这里边有个how参数,就是关于用什么方式做标准,它有两个选择,一个是any,就是只有检测到有nan,就直接全部删了(默认是删行。。毕竟一下子删一列太变态),然后第二个是all,意思就是只有全部为nan才删掉。。这个不就是我要找的吗?所以代码就可以这样写,
clean_data = data.dropna(how = 'all',axis = 1)这样就达到了我的目的哈哈,其中axis =1就表示按照列来检测。其实这个函数还有几个参数,我觉得也挺有用的可能以后会用到。第一个就是inplace,这个参数在pandas很多方法里边都有,它是一个布尔型参数,默认都为False,它就是说你的这些操作是在原数据上做还是复制一个新的,这里我就用的默认,因为我还在学啊,万一把原数据搞坏咋办。。还有个参数是thresh,这个看名字其实就知道了,设置它的作用就是既不是按照all,也不是按照any,而是按照你个的值来删,只要满足缺失值大于等于thresh的行(或列),就删除。
现在空列删完后,我本来是打算就开始处理缺失数据(后面谈)了,但代码写完后发现有错,一直找了半天原因都不知道为什么,当时忘记错误截图了,情景就是我在做求均值等运算,貌似是有些值不能求什么的。反正感觉逻辑上说不通,不知道怎么错了。一度陷入不知道咋办的地步。最后没办法,我拿出绝招。。不就8000多个数据吗,我特么一个一个看看。。。。然后。。。结果真的就让我很崩溃,里边竟然有这么一行。。。

我了个去,这是什么鬼。。真让人无语啊。然后,这次我其实多了个心眼,会不会还有别的坑爹数据,我就又稍微细看了一些。然后。。在年龄这一列又发现了些奇怪的东西。
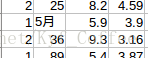
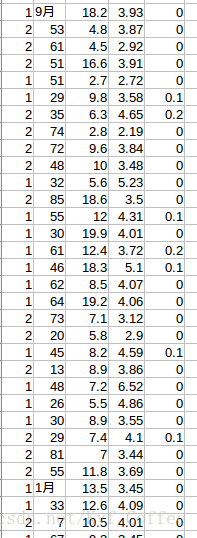
人家都是数字,冒出来些汉字什么鬼,其实后来我又执着的看了许多。。发现类似的问题还真不少。现在问题找到了,就要想办法解决了。其实最初当我刚找到很多*那行时候,我就试了一种很2b的方法,直接用上边提到的drop()函数,把那一行删了,但当我后边又发现很多像年龄里出现汉字什么的的时候我就发现我错了,假设如果以后遇到更大的数据,难道都要先肉眼找错吗?那我还写什么代码,直接删了不就完了。所以,为了不白白浪费我的眼力,我就开始查方法。其实一开始我的想法是就年龄来说,我把那几个特殊的(前提是。。。我用肉眼全看了一遍全部找出来了。。。),根据值找出来,然后删了对应行,后来发现。。这么做又何前边的想法有什么区别呢。我要忘记我用肉眼寻找的惨痛经历!
当然在这里有一点要记一下,可能我过于小白了,网上很多教程定位行啊,列啊什么的都是在讲pandas的强大的索引定位能力,这里就不提了(其实我也没怎么用)。事实上,我觉得很多情况,首先是就这次这个数据,我根本不可能知道我想要的某个数据的索引,我只知道我想找的某个数据的某一项的值。那么怎么找呢,其实很简单,比如我想找年龄为2的一条记录,可以这么写
data = pd.read_csv(path)
print data[data['age']=='2']这样就会打印出年龄字段为2的行。
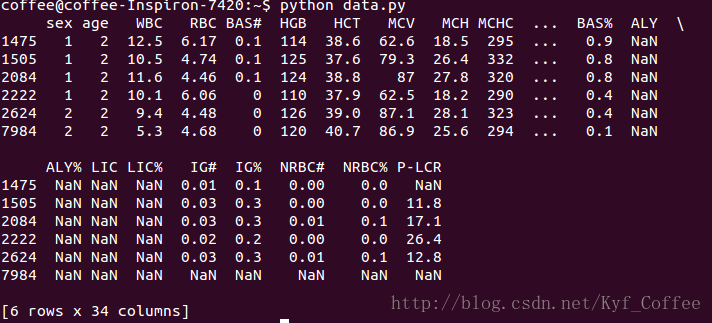
如果要附加些限制,就直接加上与运算就好了,比如想找同时性别为2的行,则
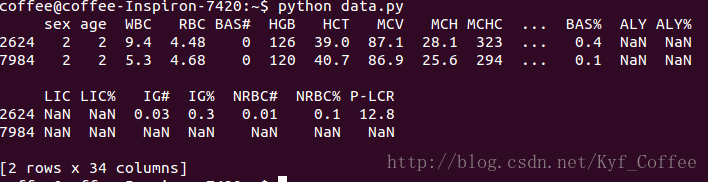
有点跑偏了。继续我的问题,现在假设我根本没用肉眼看过这些数据(实在是太累了),那就不知道现在所知道的一切了。那怎么处理呢。继续想办法,查阅资料的过程中发现了一个匹配函数,isin(),这里不介绍了,直接给文档,作用也是根据想找的内容去找行。但这个并不适合我要解决的问题,因为我现在不知道要找什么。这个时候我想到了正则表达式!!我的数据全是数字啊,(按理说就不该有那些字符串呀。这也是pandas将那些列读取为object类型而不是int或者float的原因),带着这个想法,发现了pandas中果然有模糊匹配的方法!叫做contains()。嗨呀,果然好用。然后先上文档,找到后怎么用呢。其实这些就不太难了。首先先来个正则表达式吧。
regex = r'\d+\.?\d*$'对于正则表达式我也不是很熟,不过这个网上随便一搜到处都是,我写的这个第一部分\d+就是前边要有至少一个数字,因为考虑到年龄、性别啥的就是整数嘛(虽然是object类型),然后.?是判断有一个或者没有小数点. ,这个就判断了可以是小数或者不是了,后边\d*$就是有0个或者n个数字了,加了个$是因为。。我知道有那种1月。2月。。的坑爹情况,反正就算没有加上也保险嘛,数字肯定以数字结尾嘛。写完正则,就要用上边提到的那个函数了,先上代码
for col in clean_data.select_dtypes([np.object]).columns:
clean_data = clean_data[clean_data[col].str.contains(regex,na = False) ]这里一个循环是找出哪些列是object类型的,因为只有这里边才会有坑爹的数据啊。。select_dtype()函数很简单,看文档,然后contains()里边的na参数很重要,开始时候没加这个老报错,首先contains,首先contains返回的是布尔型数据,我们也是靠这个来直接筛选行的,false的化就直接没了,这是pandas因为支持布尔型来选择行列。之前没加na=False报错的原因是因为,我们的数据有些为nan,这时候就没东西去匹配了,所以就报错了,设置参数False后,就直接把这种情况当作False考虑了,这可能会丢失些有用的数据,但也没办法了目前,可能还有更好的方法。这样下来过后,我的数据就不存在那些乱七八糟的字符了。可以看下结果。
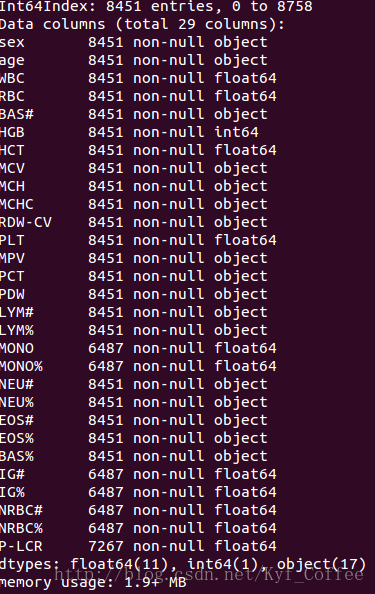
发现这时候数据变成列8451个了。
然后要做的就是处理那些正常的数据了,就是那些类型为float和int的数据。其实上边提到了关于nan的删除,有删除就有填充,毕竟数据不能因为少一个就直接全部丢掉。所以pandas里边有个fillna()函数,有了前边删除的基础,这个就很简单了。这里文档。这里我选择的是将每列的中卫数作为填充,填在了缺失处,因为大概看了下数据,有个describe()函数可以看数据的max,min等等信息,感觉用就用中卫数来填了。。其实这不重要,会填就行了,填什么以后再考虑。代码很简单。
for col in clean_data.select_dtypes([np.float,np.int]).columns:
clean_data[col].fillna(clean_data[col].median(),inplace=True)然后再看一下结果,
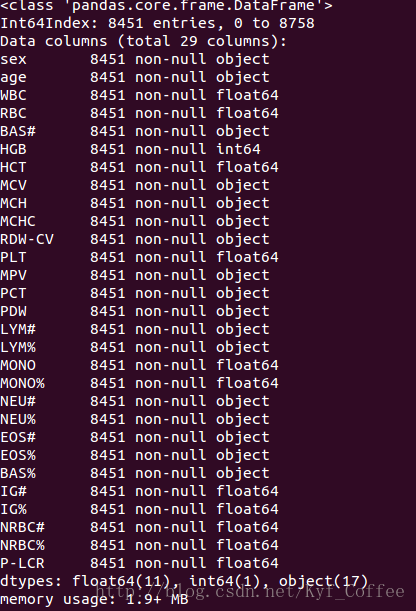
现在就没有空值了,哈哈。现在就可以
然后看了下生成的新的csv,发现有两列基本全是0,那肯定对后边做训练没啥用了,就直接用drop()函数删了,其实也可以写个判断0个数来删,但太麻烦了,偷了个懒就直接按照列号删了。
总结
pandas其实真的好用,文档和网上他人的博客也很多,但实际用时会发现每个人的需求可能都不一样,具体怎么用还要根据具体情况,不断积累。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









