






现在到了数学抽象中最关键的一步:让我们忘记这些符号所表示的对象。(数学家)不应该在这里止步,有许多操作可以应用于这些符号,而根本不必考虑它们到底代表这什么。 (Hermann Weyl 思维的数学方式)
我们可以通过 define 做过程抽象,将过程看作一类计算演化的一个模式,同时高阶过程能够提升语言的威力。
而在解决复杂问题,处理和模拟复杂现象的时候,常需要构造和处理复杂的计算对象。这里重点讨论复合数据:将数据对象组合起来,形成复合数据的方式。
与构造复合过程类似,构造复合数据也能
1)提高编程的概念层次(可能在比基本数据更高的层面上工作)
2)提高设计的模块性(基于复合数据来组织程序)
3)增强语言的表达力(增加了“新”数据类型)
4)为处理计算问题提供更多手段和方法
假设要实现过程 add-rat,计算两个有理数之和。在基本数据层,一个
有理数可以看作两个整数。
这种做法显然很不理想:
1)如果有多个有理数,记住成对的分子和分母是很大麻烦
2)相互分离的两个调用很容易写错
3)所有运算的实现/使用都有同样问题
应该把一个有理数的分子分母粘在一起,做成复合数据(一个整体)
有了复合数据对象,就能在更高概念层上定义和使用操作(处理有理数,而不是处理两个整数),更清晰,更容易理解和使用
数据抽象的定义(表示和操作实现细节)与使用分离,提高了程序模块性。两边都可以独立演化,更容易维护修改
数据抽象能大大提高语言的表达能力
实现复合数据和数据抽象,也是建立适当的数据屏障(隔离)。要实现数据抽象,程序语言需要提供:
1)粘合机制,可用于把一组数据对象组合成一个整体
2)操作定义机制,定义针对组合数据的操作
3)抽象机制,屏蔽实现细节,使组合数据能像简单数据一样使用
处理复合数据的一个关键概念是闭包:组合数据的粘合机制不仅能用于基本数据,同样能用于复合数据,以便构造更复杂的复合数据
一个过程描述了一类计算的模式,又可以作为元素用于实现其他(更复杂的)过程。因此过程是一种抽象, 过程抽象屏蔽计算的实现细节(细节可替代),规定了使用方式(接口),使用方只依赖于抽象的使用方式约定。
而数据抽象可以包含一类数据所需的所有功能,又像基本数据元素一样可以作为其他数据抽象的元素。
1)屏蔽一种复合数据的实现细节
2)提供一套抽象操作,使用组合数据的就像是使用基本数据
3)数据抽象的接口(界面)包括两类操作:构造函数和选择函数。 构造函数基于一些参数构造这类数据,选择函数提取其内容
比如我们熟悉的栈就是一种数据抽象,你不用关心内部实现细节(比如可以用数组实现也可以用链表实现),你又可以把栈当成一种基本数据,去构造其他结构,比如队列。栈只对外提供必要的接口,比如构造接口,取数据的接口等等。
再举个例子:长方形可以看成一种数据抽象,他的内部可以用四个点表示,也可以用对角的两个点表示,也可以直接用长宽表示,他对外接口只要提供出度宽度就好了,当我们计算面积周长是,我们完全不care他们内部怎么组织实现的,我只要通过选择函数(接口)取得我想要的内容(长度宽度)。
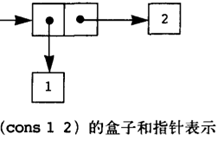
Scheme 的基本复合结构称为“序对” ,基本过程 cons 把两个参数结合起来构造一个序对,过程 car 和 cdr 取出序对的两个成分
(define x (cons 1 2))
(car x)
1
(cdr x)
2序对也是数据对象,可以用于构造更复杂的数据对象,如:
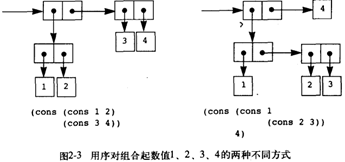
(define y (cons 3 4))
(define z (cons x y))
(car (car z))
1
(car (cdr z))
3可以直接用序对表示有理数。基本过程的可行定义:
(define (make-rat n d) (cons n d))
(define (numer x) (car x))
(define (denom x) (cdr x))输出有理数的过程( display 是一个基本输出函数)
(define (print-rat x)
(display (numer x))
(display "/")
(display (denom x)) )一般而言,实现数据抽象时要首先确定一组基本操作,其余操作都基于它们实现,不直接访问基础数据表示。
建立层次性抽象屏障的价值:
1)建立层次,隔离数据表示和使用,两部分独立,容易维护和修改
2)实现好的数据抽象可以用于其他程序和系统,比如各种库
3)一些设计决策可以推迟,直到有了更多实际信息后再处理
在 Scheme 里可以完全基于过程定义序对,如下面过程定义
(define (cons x y)
(define (dispatch m)
(cond ((= m 0) x)
((= m 1) y)
(else (error "Argument not 0 or 1 -- CONS" m))))
dispatch)或者:
(define (cons x y)
(lambda (m)
(cond ((= m 0) x)
((= m 1) y)
(else (error "Argument not 0 or 1 -- CONS" m)))))
(define (car z) (z 0))
(define (cdr z) (z 1)) 不难检查: (car (cons x y)) 将产生x,(cdr (cons x y)) 将产生y
注意这里(cons x y)返回的是一个过程。
这种过程性表示满足序对构造函数和选择函数的所有条件,,实际 Scheme 系统用存储表示直接实现序对,主要是为了效率
本例说明:过程和数据之间没有绝对界限,完全可以用过程表示数据。
再来看另一种实现:
(define (cons x y)
(lambda(m) (m x y))
)
(define (car z)
(z (lambda(p q) p))
)
(define (cdr z)
(z (lambda(p q) q))
) 注意这里的参数m为一个过程,(cons x y)返回的也为一个过程,该过程接收一个参数。
对于表达式 (car (cons 1 2)) 的展开序列如下:
(car (cons 1 2))
(car (lambda (m) (m 1 2))) ; 展开 cons
((lambda (z) (z (lambda (p q) p))) ; 展开 car ,代换 z
(lambda (m) (m 1 2)))
((lambda (m) (m 1 2)) ; 代换 m
(lambda (p q) p))
((lambda (p q) p) ; 代换 p
1 2)
1 只需要有过程就可以定义出序对,不需要用任何数据结构,对其他数据对象,也同样可以做到。
计算机科学先驱 Alonzo Church 研究 λ 演算,他只用λ表达式(相当于完全基于过程)构造了整数算术系统。
考虑一个问题,如果将a、b的序对表示成2^a*3^b的整数,是否也可以给出相应的cons、car、cdr实现。
(define (cons x y)
(* (expt 2 x) (expt 3 y))
)每个正整数都可以被分解为唯一的素数相乘序列,我们可以利用这一点,通过分解 cons 计算出的整数的序列,从而复原 car 和 cdr 。
(define (car z)
(if (= (remainder z 2) 0)
(+ 1 (car (/ z 2)))
0
)
)
(define (cdr z)
(if (= (remainder z 3) 0)
(+ 1 (car (/ z 3)))
0
)
) 序对为我们提供了构造复杂数据的黏接剂。
任何序对结构都可作为cons 的参数(cons 的闭包性质,序对的 cons还是序对)。只要有cons 就可以构造结构任意复杂的数据对象。
这里的闭包区别于带有自由变量的过程实现中的闭包。
用序对构造的最常用结构是序列:一批数据的有序汇集
包含元素 1, 2, 3, 4 的序列:(cons 1 (cons 2 (cons 3 (cons 4 nil))))
nil 是特殊变量,它不是序对,当作空序列(空表)
使用 cons 顺序构造起来的序列称为表。 list 是构造表的过程:
(list <a1> <a2> ... <an>)等价于
(cons <a1> (cons <a2> (cons ... (cons <an> nil) ...)))表输出为带括号的元素序列
表输出为带括号的元素序列。例如
(define one-through-four (list 1 2 3 4))
one-through-four
(1 2 3 4) 区分 (list 1 2 3 4) 和输出的 (1 2 3 4),前者是表达式,后者是表达式求值的结果
car 取出表是第一项, cdr 取得去掉第一项后其余项的表:
(car one-through-four)
1
(cdr one-through-four)
(2 3 4)
(car (cdr one-through-four))
2
(cons 10 one-through-four)
(10 1 2 3 4)注意序对和表的不同。设
(define x (cons 1 2))
(define y (list 1 2))这时有:
(car x) 1
(cdr x) 2
(car y) 1
(cdr y) (2) 注意:序对和表都需要在内存里安排存储,每次 cons 都要做一次动态存储分配
做表操作时可能导致一些序对单元失去引用。 Scheme 系统有内置的废料收集系统,能自动回收这种单元
定义过程 list-ref 返回表 items 中第 n 项元素( n 是 0 时返回首项)
通过递归,可将list-ref过程定义为:
(define (list-ref items n)
(if (= n 0)
(car items)
(list-ref (cdr items) (- n 1))))(define squares (list 1 4 9 16 25))
(list-ref squares 3)
16求表长的递归定义:
(define (length items)
(if (null? items)
0
(+ 1 (length (cdr items)))))拼接两个表的过程 append:
(define (append list1 list2)
(if (null? list1)
list2
(cons (car list1) (append (cdr list1) list2))))或者:
(define (appendd list1 list2)
(if (null? list2)
list1
(appendd (cons list1 (car list2)) (cdr list2)))) 基本过程 +、 * 和 list 等都允许任意多个参数
我们也可以定义这种过程,只需用带点尾部记法的参数表:
(define (f x y . z) )
圆点之前可以根据需要写多个形参,它们将一一与实参匹配。圆点后写一个形参,应用时关联于其余实参的表。
比如(f 1 2 3 4 5 6)
对应于上面,则x为1,y为2,z为表(3 4 5 6)
下面是一个求任意多个数的平方和的过程:
(define (square-sum x . y)
(define (ssum s vlist)
(if (null? vlist)
s
(ssum (+ s (square (car vlist))) (cdr vlist))))
(ssum (square x) y) )如果需要处理的是 0 项或任意多项,参数表用 (square-sum . y),过程体也需要相应修改
表的映射:把某过程统一应用于表元素,得到结果的表(好多语言都实现了类似的操作)
例:构造把所有元素等比例放大或缩小的表
(define (scale-list items factor)
(if (null? items)
nil
(cons (* (car items) factor)
(scale-list (cdr items) factor))))
(scale-list (list 1 2 3 4 5) 10)
(10 20 30 40 50)总结这一计算的模式,可以得到一个重要的(高阶)过程 map:
(define (map proc items)
(if (null? items)
nil
(cons (proc (car items))
(map proc (cdr items)))))
(map abs (list -10 2.5 -11.6 17))
(10 2.5 11.6 17)
(map (lambda (x) (* x x)) (list 1 2 3 4))
(1 4 9 16) map 把处理元素的过程应用于作为其参数的表里的每个元素,得到的是通过该过程的应用得到的所有新元素的表
可以看作操作的“提升”:把元素层的映射(由一个元素得到另一新元素)提升为表层的操作(由一个表得到另一新表)
用 map 给出 scale-list 的定义:
(define (scale-list items factor)
(map (lambda (x) (* x factor))
items) ) map是一类表处理的高层抽象,代表一种公共编程模式:
在 scale-list 原定义里,元素操作和对表元素的遍历交织在一起,使这两种操作都不够清晰。
在新定义里,通过使用 map 抽象分离了对元素的操作和对表的变换(对表的遍历和作为结果的表的构造),两部分都可以独立变化,可以换一个操作或者换一种操作模式,这是一种很有价值的思路。
类似的抽象还有for-each,我们来定义一个for-each:
(define (foreach proc items)
(if (not (null? items))
(begin
(proc (car items))
(foreach proc (cdr items))
))
)
>(for-each (lambda (x) (newline) (display x)) (list 1 2 3))
1
2
3用表表示序列,可以自然推广到元素也是序列的情况,如把 ((1 2) 3 4) 看作是用 (list (list 1 2) 3 4) 构造的表里有 3 项,其中第 1 项又是表。结构如下图:
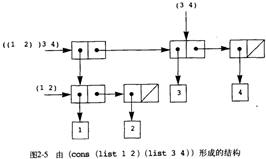
这种结构可以看作是树,其中的子表是子树,基本数据是树叶。树形结构可以自然地递归方式处理,树操作分为对树叶的具体操作和对子树的递归处理。
统计树叶个数的过程 count-leaves:
(define (count-leaves x)
(cond
((null? x) 0)
((not (pair? x)) 1)
(else (+ (count-leaves (car x)) (count-leaves (cdr x))))
)
)count-leaves 实现一种遍历树中所有树叶、积累信息的过程。反映了一种处理多层表的通用技术。
把树叶(假设是数)按 factor 等比缩放。可以用 count-leaves 的
方式遍历树,在遍历中构造作为结果的树:
(define (scale-tree tree factor)
(cond ((null? tree) nil)
((not (pair? tree)) (* tree factor))
(else (cons (scale-tree (car tree) factor)
(scale-tree (cdr tree) factor)))))
(scale-tree (list 1 (list 2 (list 3 4) 5) (list 6 7)) 10)
(10 (20 (30 40) 50) (60 70))把树看作子树序列,也可以基于 map 实现 scale-tree:
(define (scale-tree tree factor)
(map (lambda (sub-tree)
(if (pair? sub-tree) (scale-tree sub-tree factor)
(* sub-tree factor)))
tree))求集合全部子集:
(define (subsets s)
(if (null? s)
(list `())
(let ((rest (subsets (cdr s))))
(append rest (map (lambda (x)(cons (car s) x)) rest))
))) 以序列作为程序接口,可以用高阶过程实现各种程序模式
求一棵树里值为奇数的树叶的平方和:
(define (sum-odd-squares tree)
(cond ((null? tree) 0)
((not (pair? tree)) (if (odd? tree) (square tree) 0))
(else (+ (sum-odd-squares (car tree))
(sum-odd-squares (cdr tree)))))) 相关过程抽象:
1)枚举树中所有树叶
2)滤出其中的奇数
3)对选出的数求平方
4)用 + 累积它们,从 0 开始

上面的程序都没有很好地反映这种信息流动的结构,过程的实现中不同步骤交织在一起,缺乏结构性。如何组织程序,拥有更好的结构性?
回想之前的map,我们是通过表操作实现各步处理。
例如,用 map 实现信息流中的映射:
(map square (list 1 2 3 4 5))
(1 4 9 16 25)对序列的过滤,就是选出其中满足某个谓词的元素:
(define (filter predicate sequence)
(cond ((null? sequence) nil)
((predicate (car sequence)) (cons (car sequence) (filter predicate (cdr sequence))))
(else (filter predicate (cdr sequence)))))累积操作的过程实现:
(define (accumulate op initial sequence)
(if (null? sequence)
initial
(op (car sequence) (accumulate op initial (cdr sequence)))))
(accumulate + 0 (list 1 2 3 4 5))
15
(accumulate cons nil (list 1 2 3 4 5))
(1 2 3 4 5)枚举一棵树的所有树叶:
(define (enumerate-tree tree)
(cond ((null? tree) nil)
((not (pair? tree)) (list tree))
(else (append (enumerate-tree (car tree))
(enumerate-tree (cdr tree))))))
(enumerate-tree (list 1 (list 2 (list 3 4)) 5))
(1 2 3 4 5)那么我们可以利用这些基础操作重新定义的 sum-odd-square:
(define (sum-odd-squares tree)
(accumulate + 0
(map square
(filter odd? (enumerate-tree tree)))))不同于之前以当个数据作为操作对象,将操作交织在一起,这里以表为各模块接口,使个操作过程分离,结果更加清晰。而且这些基本操作还可以进行复用,组合构成其他操作。
给定n,找出所有不同的 i 和 j 使 1 <= j < i <= n 且 i + j 是奇数。
1) 枚举出所有(i,j)
;定义一个区间序列生成函数
(define (enumerate-interval low high)
(if(> low high)
`()
(cons low
(enumerate-interval (+ low 1) high)))
)
(define (make_pair n)
(accumulate append `()
(map (lambda (i) (map (lambda (j) (consi j)) (enumerate-interval 1 (- i 1))))
(enumerate-interval 1 n))))2) 判断是否为奇数
(define (odd-sum pair)
(odd? (+ (car pair) (cdr pair)))
)3) 根据判断过滤
(filter odd-sum (make_pair 4))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











